HDFS之Qurom Journal Manager(QJM)实现机制分析
1.前言
1.1背景
自从hadoop2版本开始,社区引入了NameNode高可用方案。NameNode主从节点间需要同步操作日志来达到主从节点元数据一致。最初业界均通过NFS来实现日志同步,大家之所以选择NFS,一方面因为可以很方便地实现数据共享,另外一方面因为NFS已经发展20多年,已经相对稳定成熟。
虽然如此,NFS也有缺点不能满足HDFS的在线存储业务:网络单点及其存储节点单点。业界提供了数据共享的一些高可用解决方案,但均不能很好地满足目前HDFS的应用场景。
| 方案 |
网络单点 |
存储单点 |
备注 |
| Mysql HA |
无 |
无 |
数据有丢失风险 |
| Drbd+heartbeat+NFS |
无 |
无 |
脑裂;数据有丢失风险 |
| Keepalive+NFS |
无 |
有 |
数据有丢失风险 |
为了满足共享日志的高可用性,社区引入QJM。QJM由cloudera开发,实现了读写高可用性,使HDFS达到真正的高可用性成为可能。
1.2.术语和定义
Epoch
由主节点在启动及其切换为主的时候分配,每次操作JN节点均会检查该值,类似zookeeper中的zxid,此时主NameNode类似zookeeper中的leader,JN节点类似ZK中的Follower
JournalNode
QJM存储段进程,提供日志读写,存储,修复等服务
QJM
Qurom Journal Manager
startLogSegment
开始一个新的日志段,该日志段状态为接收写入日志的状态
finalizeLogSegment
将文件由正在写入日志的状态转化为不接收写日志的状态
recoverUnfinalizedSegments
主从切换等情况下,恢复没有转换为finalized状态的日志
journalId
日志ID,由配置指定,如qjournal://g42:8485;g35:8485;uhp9:8485/geminifs,则其中的geminifs即为journalId
2.设计方案
QJM通过读写多个存储节点达到高可用性,同时为了恢复由于异常造成的多节点数据不一致性,引入了数据一致性算法。QJM逻辑图如下:
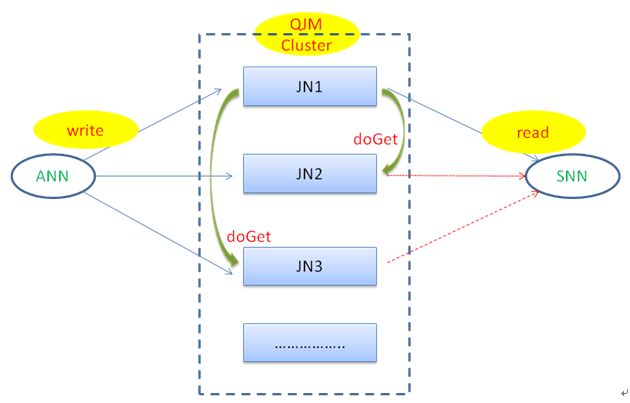
QJM的基本原理就是用2N+1台JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,保证数据高可用。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效。
QJM写原理示意图
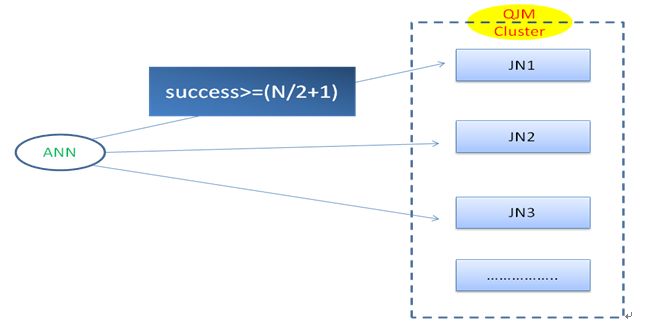
2.1.写日志机制
写操作由主节点来完成,当主节点调用flush操作,会调用RPC同时向N个JN服务异步写日志,有N/2+1个节点返回成功,本次写操作才算成功。
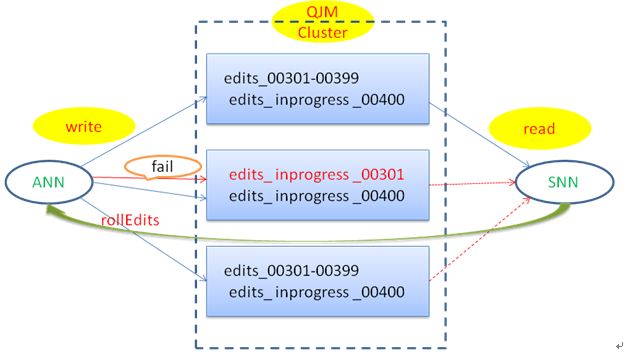
主节点会标记返回失败的JN节点,下次写日志将不再写该节点,直到下次调用滚动日志操作,如果此时该JN节点恢复正常,之后主节点会向其写日志。虽然该节点丢失部分日志,由于主节点写入了多份,因此相应的日志并没有丢失。
为了保证写入每个日志文件txid的连续性,主节点保证分配的txid是连续的,同时JN节点在接受写日志的时候,首先会检查txid是否跟上次写连续,如果不连续会向主节点报错,连续则写入日志文件。
2.2读日志机制
相比写日志过程,读日志要相对简单一些。
读取日志示意图
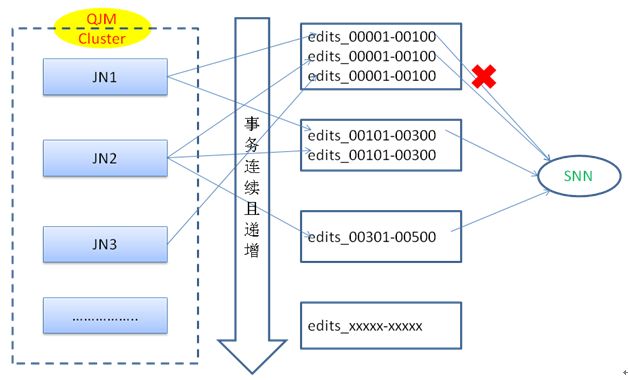
当从节点触发读日志的时候,会经历如下几个步骤:
1、 选择日志文件,建立输入流
从节点遍历出所有还没有消化的日志文件,同时过滤inprocess状态的文件。对于每个JN节点上的日志文件,均按照txid从小到大进行排序放入一个集合。每个JN节点在从节点端均对应这样一个集合。再将每个JN节点间相同的日志文件进行归类为一组(组内日志会检查fisrtTxid是否相等,及其lastTxid是否相等);每个组之间再按照txid从小到大进行排序,这样方便从节点按照txid顺序消化日志;同时也会判断每个组之间txid是否连续。
2、 消化日志
准备好输入流以后,开始消化日志,从节点按照txid先后顺序从每个日志组里面消化日志。在每个日志组里面,首先会检查起始txid是否正确,如果正确,从节点先消化第一个日志文件,如果消化第一个日志文件失败则消化第二个日志文件,以此类推,如果日志组内文件遍历完还没有找到需要的日志,则该日志消化失败,消化每个日志的如果消化的上一个txid等于该日志文件的lastTxid,则该日志文件消化结束。
2.3.日志恢复
在从节点切换为主节点的过程中,会进行最近的日志段状态检查,如果没有转换为finalized状态会将其转换为该状态,日志恢复就处于该过程当中。
恢复日志finalized状态图
2.3.1.触发条件
跟其他一些数据恢复方案不同,QJM并非每次写日志文件出现异常均恢复,而是从切换为主的情况下进行最新的一个日志文件的数据一致性检查,然后决定是否触发数据修复流程,之所以这样实现我想有如下原因:
1、 在开始一个新的edits文件前,HDFS会确保之前最新的日志文件已经由inprocess状态转化为finalized状态,同时QJM每次操作有N/2+1个节点返回成功才算成功,因此除了最新日志文件前,之前老的日志文件是finalized状态,且是高可用的;仅最新的日志文件可能由于主节点服务异常或者QJM某个进程异常导致日志没有正常转换为finalized状态,因此在从切换为主的时候需要恢复处理;
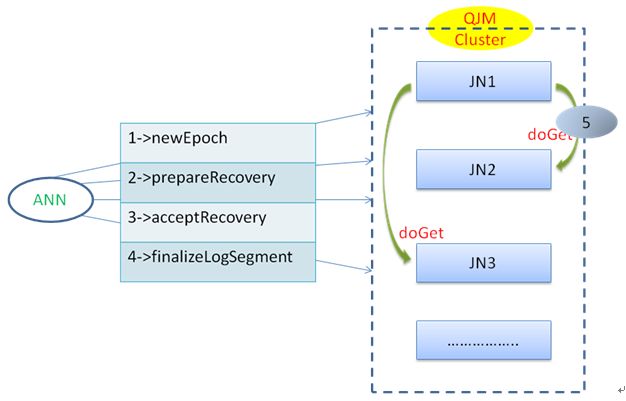
2.3.2.恢复流程
在日志恢复的过程中,需要经历准备恢复(prepareRecovery),接受恢复(acceptRecovery)两个阶段。
2.3.2.1.prepareRecovery
该操作向JN端发送RPC请求,查询需要恢复的日志段文件是否存在,如果存在则判断日志段文件状态(inprocess或finalized),同时也会返回epoch编号,NameNode根据返回的查询信息通过修复算法选择修复的源节点,准备进行数据修复。
2.3.2.2.acceptRecovery
计算获得源节点后,NameNode会向JN端发送恢复操作,JN节点根据接收到的RPC恢复请求,判断当前节点是否需要进行日志修复,如果需要进行修复,则通过doGet方式到源节点下载需要恢复的目标日志文件。下载过程中,先将下载的文件放到临时目录(tmp)目录下,下载完成后进行md5校验,检查是否有数据丢失,数据检查通过再将下载的文件放置到工作目录(current)下,这样数据恢复完成。
在JN节点执行该方法中,有两个问题需要考虑:
1、如果在JN节点下载日志的文件时候,源节点连接不通,会抛异常,如果有多个JN节点可以作为源节点,在NameNode调用JN节点的acceptRecovery方法是,可以考虑返回URL数组而不是单个URL,这样一个URL不能连接还可以尝试连接另外的JN节点进行文件下载;
2、有可能某JN节点下载日志文件的时候,自己进程挂掉,在QJM中,有对该问题的处理方式;
开始接触的时候我担心是否可能有文件既在被从节点读取,又在恢复该日志文件,通过分析后发现不会有何种情况,因为从节点消化的日志均是finalized状态的文件而不是inprocess状态的文件。
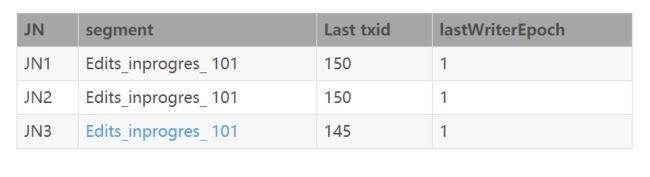
2.3.3.恢复算法
在2.3.2.1节中提到,查询到每个JN相关信息返回后,会使用修复算法选择源节点进行日志数据的修复,此处补上修复算法的策略:
1、 首先判断JN节点是否有指定的txid,如果某节点没有,则该节点不会作为源节点;
2、 如果JN节点存在指定的txid,然后判断该文件是否为finalized状态,如果不同的JN节点,txid所在的文件既有finalized状态的文件又有inprocess状态的文件,以finalized状态文件为候选源节点,当然finalized状态的文件之间还需要判断结束txid是否相等,然后返回其中任意一个节点作为源节点;
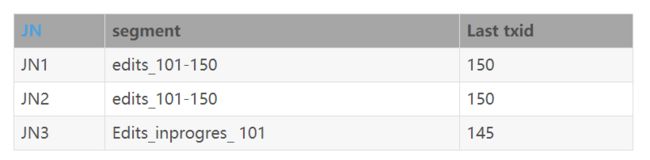
3、 如果节点间文件均是inprocess状态的文件,首先判断其epoch编号,如果epoch编号不一致,则以epoch编号大的作为候选源节点;如果epoch编号一致,则选择结束txid更大的作为源节点。