使用JMC工具对spark 程序调优(二)
上篇介绍了jmc的主要功能,下面借助笔者参与调试的一个例子,来谈谈JMC的用处。
比如,之前程序有一个bug,困扰我们很长时间,如下文所述。
一般在调优程序的时候,都尽量用多种辅助工具帮助定位和提高效率。基于cloudera的环境,我们可以查看cpu,memory,磁盘等资源使用情况,如图:



由上图可以看到,集群系统资源利用保持平稳。再来看看内存使用:
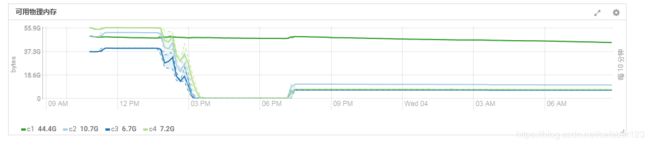
可以看到,下午开始以后,可用内存逐渐减小,中间3点到6点段,可用内存变为0.
可以看到问题所在,就是内存逐渐减小。
开始认为是系统内存不足(这个判断影响深远)。于是反复调整exectutor内存和task的数量,并且在这上面花费了很多时间。虽然结果有改善,但没有彻底解决问题。
减小时间刻度,放大图片:

图中内存波动,是由于定时强制释放内存,即便如此,内存仍然逐渐减小。
同时,spark运行日志上,报错处,程序即停止了。而且有时是c2报错,有时是c3报错;而且偶尔报的错误不一样,但可能性最大是内存溢出。如图:


这时,可以下第一个比较接近的断定了,可能是内存溢出或者GC没有调好。
内存溢出,从程序中很难找到,不确定很强,于是调整GC。调整后,内存在开始一段时间内保持稳定:

由于程序是批量作业,因此,第二天过来查看,发现内存还是在停止前的时间段减少,最终程序停止。
查看spark UI,发现批量执行过程中,情况也有改善,但最后仍然停止作业。
这种错误或者说bug,尽管检查了系统资源监控,spark UI,以及spark 运行日志,仍然没法精确定位错误地点。
于是,为了方便重现问题,执行策略一:
减小测试数据量。
由于之前测试数据量大,一次测试要花费几个到十几个小时。遂逆向思维,把测试数据量大大变小。
然后,执行策略二:
减小分配内存,至最小可用大小。
由于jconsole 可以监控分钟粒度的内存状态,因此,使用jconsole,在一个小时左右,重现问题。结果如图:
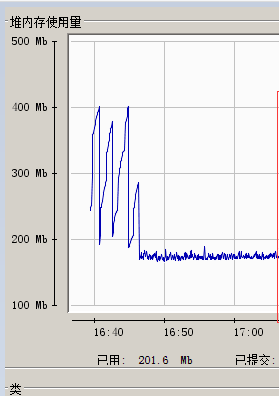
也就是说,无论系统资源多少,内存总会减少。但是,无法进一步做分析判断。
JMC派上用场
虽然仍对GC持怀疑态度,不过还是检查了代码,并用JMC 做了分析。
首先,查看了程序执行时的GC的变化情况,如图:

发现绝大多数时间,GC的年轻代和老年代变化稳定。
然后,又查看了热点方法,如图:

热点方法能看出那个方法执行的次数最多。可是这样,没有提供更多信息。
于是,又查看了堆栈跟踪:

堆栈跟踪可以查看函数的执行链,尽管如此,仍然没法定位具体问题点。
这时,就要做些分析了,
分析一:
检查内存泄漏的速度,也就是每2次释放内存之间,减少的内存。发现,内存减少速度很快。程序处理的也是文件类数据,由此,很可能是读写文件没有回收内存。如果是字符串或网络类型的内存泄漏,速度没有这么快。
分析二:
内存泄漏快,也跟某个方法执行频率很高有关。检查热点方法,以及对热点方法堆栈跟踪,同时检查代码,看是否有方法跟文件操作有关。
经过以上的分析和检查代码,终于发现某一处文件处理没有回收内存,造成内存泄漏。修复代码后,再次多次测试,内存状态稳定,如图:

至此,这个一开始原因很明显,但很难定位到具体错误点的问题,终于得到解决。