java线程池动态调整大小_调整线程池的大小
java线程池动态调整大小
我们的线程池应该有多大?
不久前,一个朋友在Skype上对我执行ping操作,问我一些关于在64路机器上运行的JVM集群的问题,该机器每天启动30个奇数线程。 在运行300,000多个线程的情况下,内核花费大量时间来管理它们,以至于应用程序完全不稳定。 很明显,此应用程序需要一个线程池,以便他们可以限制客户端,而不是让客户端限制它们。
尽管该示例是一个极端的示例,但它突出说明了为什么我们使用线程池。 但是,即使有了线程池,我们仍然可以通过丢失数据或使事务失败来给用户带来痛苦。 或者,如果该池太大或太小,我们的应用程序可能会完全不稳定。 大小合适的线程池应允许运行尽可能多的请求,以使硬件和应用程序可以轻松地支持它们。 换句话说,如果我们有能力处理请求,我们不希望它们在队列中等待,但是我们也不想启动超出我们管理能力的请求。 那么,我们的线程池应该有多大?
如果我们要遵循“不要猜测的方法”的口号,我们首先需要看一下所涉及的技术,并询问哪些测量方法有意义,以及我们如何对我们的系统进行仪器测量才能获得这些测量结果。 我们还需要介绍一些数学知识。 当我们认为线程池只是一个或多个与队列结合的服务提供者时,我们看到这是一个可以使用利特尔定律建模的系统。 让我们更深入地了解如何。
利特尔定律
利特尔定律说,系统中的请求数等于它们到达的速率乘以处理单个请求所需的平均时间。 这项法律在我们的日常生活中如此普遍,以至于直到1950年代才提出,直到1960年代才被证实。 这是实施利特尔定律的一种形式的示例。 您是否曾经站成一排,试图弄清楚要站在其中多久? 您将考虑排队的人数,然后快速浏览为排在最前面的人服务的时间。 然后,您可以将这两个值相乘,得出您排队的时间的估计值。 如果您不看线路的长度,而是观察新人加入线路的频率,然后将该值乘以服务时间,则可以知道线路中或正在接受服务的平均人数。

您可以根据利特尔定律玩许多其他类似的游戏,这些游戏会回答其他问题,例如“一个人平均要排队等待服务多少时间?” 等等。

图1.利特尔定律
同样,我们可以使用利特尔定律来确定线程池大小。 我们要做的就是测量请求到达的速度以及为它们提供服务的平均时间。 然后,我们可以将这些度量值插入利特尔定律,以计算系统中请求的平均数量。 如果该数目小于线程池的大小,则可以相应地减小线程池的大小。 另一方面,如果该数目大于线程池的大小,则事情会变得更加复杂。
在等待的请求多于被执行的情况下,我们需要确定的第一件事是系统中是否有足够的能力来支持更大的线程池。 为此,我们必须确定最有可能限制应用程序扩展能力的资源。 在本文中,我们将假定它是CPU,但请注意,在现实生活中它很有可能是其他事物。 最简单的情况是您有足够的容量来增加线程池的大小。 如果您不这样做,则必须考虑其他选择,例如调整应用程序,添加更多硬件或两者结合。
一个有效的例子
让我们通过考虑一个典型的工作流程来解压缩先前的文本,在典型的工作流程中,请求是从套接字中取出并执行的。 在执行过程中,它需要获取数据或其他资源,直到将结果返回给客户端为止。 在我们的演示中,服务器通过执行统一的工作单元来模拟此工作负载,该工作单元会在执行一些CPU密集型任务与从数据库或其他外部数据源检索数据之间进行调整。 在我们的演示中,让我们通过计算非理性数字(例如Pi或2的平方根)的小数位数来模拟CPU密集型活动。Thread.sleep用于模拟对外部数据源的调用。 线程池将用于限制服务器中活动的请求数。
要监视java.util.concurrent(juc)中的任何线程池选择,我们将不得不添加我们自己的工具。 在现实生活中,我们可以通过使用方面,ASM或另一种字节码检测技术来检测jucThreadPoolExecutor来添加此功能。 就我们的示例而言,我们将通过手动滚动jucThreadPoolExecutor扩展以包括必要的监视来避免这些主题。
public class InstrumentedThreadPoolExecutor extends ThreadPoolExecutor {
// Keep track of all of the request times
private final ConcurrentHashMap timeOfRequest =
new ConcurrentHashMap<>();
private final ThreadLocal startTime = new ThreadLocal();
private long lastArrivalTime;
// other variables are AtomicLongs and AtomicIntegers
@Override
protected void beforeExecute(Thread worker, Runnable task) {
super .beforeExecute(worker, task);
startTime.set(System.nanoTime());
}
@Override
protected void afterExecute(Runnable task, Throwable t) {
try {
totalServiceTime.addAndGet(System.nanoTime() - startTime.get());
totalPoolTime.addAndGet(startTime.get() - timeOfRequest.remove(task));
numberOfRequestsRetired.incrementAndGet();
} finally {
super .afterExecute(task, t);
}
}
@Override
public void execute(Runnable task) {
long now = System.nanoTime();
numberOfRequests.incrementAndGet();
synchronized (this) {
if (lastArrivalTime != 0L ) {
aggregateInterRequestArrivalTime.addAndGet(now - lastArrivalTime);
}
lastArrivalTime = now;
timeOfRequest.put(task, now);
}
super .execute(task);
}
}
清单1. InstrumentedThreadPoolExecutor的要点
此清单包含检测代码的重要部分,我们的服务器将使用这些部分代替ThreadPoolExecutor。 我们将通过覆盖三个关键的Executor方法来收集数据:beforeExecute,execute和afterExecute,然后使用MXBean公开该数据。 让我们看一下每种方法的工作方式。
执行程序的execute方法用于将请求传递到执行程序。 覆盖该方法使我们可以收集所有初始时间。 我们还可以利用这个机会来跟踪两次请求之间的间隔。 该计算涉及几个步骤,每个线程都会重置lastArrivalTime。 由于我们共享状态,因此该活动需要同步。 最后,我们将执行委派给超级执行器类。
顾名思义,方法executeBefore在执行请求之前立即执行。 到目前为止,请求累积的所有时间只是池中等待的时间。 这通常称为“停滞时间”。 该方法结束之后和调用afterExecute之前的时间将被视为“服务时间”,我们可以将其用于利特尔定律。 我们可以将开始时间存储在本地线程上。 afterExecute方法将完成“池中时间”,“为请求服务的时间”以及注册“请求已退回”的计算。
我们还需要一个MXBean来报告InstrumentedThreadPoolExecutor收集的性能计数器。 那将是MXBean ExecutorServiceMonitor的工作。 (请参见清单2)。
public class ExecutorServiceMonitor
implements ExecutorServiceMonitorMXBean {
public double getRequestPerSecondRetirementRate() {
return (double) getNumberOfRequestsRetired() /
fromNanoToSeconds(threadPool.getAggregateInterRequestArrivalTime());
}
public double getAverageServiceTime() {
return fromNanoToSeconds(threadPool.getTotalServiceTime()) /
(double) getNumberOfRequestsRetired();
}
public double getAverageTimeWaitingInPool() {
return fromNanoToSeconds( this .threadPool.getTotalPoolTime()) /
(double) this .getNumberOfRequestsRetired();
}
public double getAverageResponseTime() {
return this .getAverageServiceTime() +
this .getAverageTimeWaitingInPool();
}
public double getEstimatedAverageNumberOfActiveRequests() {
return getRequestPerSecondRetirementRate() * (getAverageServiceTime() +
getAverageTimeWaitingInPool());
}
public double getRatioOfDeadTimeToResponseTime() {
double poolTime = (double) this .threadPool.getTotalPoolTime();
return poolTime /
(poolTime + (double) threadPool.getTotalServiceTime());
}
public double v() {
return getEstimatedAverageNumberOfActiveRequests() /
(double) Runtime.getRuntime().availableProcessors();
}
}
清单2. ExecutorServiceMonitor,有趣的地方
在清单2中,我们可以看到非平凡的方法,这些方法将为我们提供问题的答案,即如何使用队列? 请注意,方法getEstimatedAverageNumberOfActiveRequests()是利特尔定律的实现。 在这种方法中,报废率或观察到的请求离开系统的速率乘以服务请求所需的平均时间,从而得出系统中请求的平均数量。 其他感兴趣的方法是getRatioOfDeadTimeToResponseTime()和getRatioOfDeadTimeToResponseTime()。 让我们进行一些实验,看看这些数字如何相互关联以及与CPU利用率有关。
实验1
第一个实验是故意进行的,目的是提供一种如何工作的感觉。 普通实验的设置是:将“服务器线程池大小”设置为1,并让单个客户端重复上述请求30秒钟。
(点击图片放大)
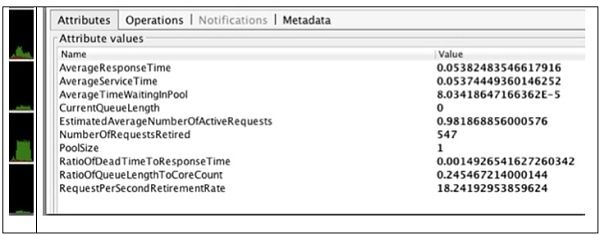
图2来自1个客户端,1个服务器线程的结果
图2中的图形是通过获取VisualVM MBean视图的屏幕截图和图形CPU利用率监视器而获得的。 VisualVM( http://visualvm.java.net/ )是一个开放源代码项目,旨在容纳性能监视和性能分析工具。 使用此工具不在本文讨论范围之内。 简而言之,MBean视图是一个可选插件,使您可以访问在PlatformMBeansServer中注册的所有JMX MBean。
返回实验,线程池大小为1。 考虑到客户端的循环行为,我们可以期望活动请求的平均数量为1。 但是,客户端确实需要一些时间来重新发出请求,因此该值应略小于1,并且0.98符合该期望。
下一个值RatioOfDeadTimeToResponseTime刚好超过0.1%。 假设只有一个活动请求且它与线程池大小匹配,则可以预期该值为0。但是,非零结果很可能是由于计时器放置和计时器精度引入的错误所致。 该值很小,因此我们可以放心地忽略它。 CPU使用率告诉我们,使用的内核少于1个,这意味着我们有足够的净空来处理更多请求。
实验2
在第二个实验中,当并发客户端请求的数量增加到10个时,我们将线程池的大小保持为一。正如预期的那样,CPU利用率没有改变,因为一次只只有一个线程在工作。 但是,我们能够撤消更多请求,这很可能是因为活动请求数为10,从而使客户端不必等待客户端重新发出。 由此可以得出结论,一个请求始终处于活动状态,并且队列长度为九。 更能说明问题的是,停滞时间与响应时间之比接近90%。 这个数字的意思是,客户端看到的总响应时间的90%可以归因于等待线程所花费的时间。 如果我们想减少延迟,那么房间里的时间就是空载时间,并且由于我们有大量的备用CPU,因此可以安全地增加池的大小以允许请求到达它。
(点击图片放大)
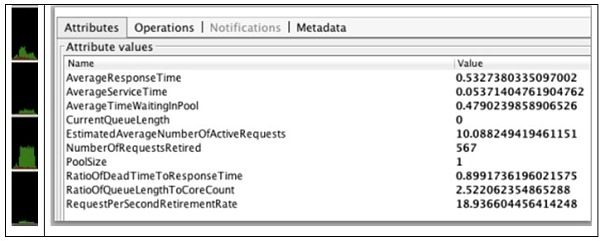
图3,来自10个客户端请求,1个服务器线程的结果
实验3
由于我们的核心数量为4,因此让我们运行相同的实验,但将线程池大小设置为4。
(点击图片放大)
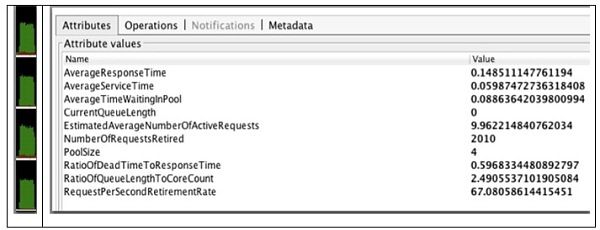
图4. 10个客户端请求,4个服务器线程的结果
再一次,我们可以看到平均请求数为10。这次的区别是,已撤消的请求数已跃升至刚刚超过2000。CPU饱和度相应增加,但仍未达到100%。 停滞时间仍然是总响应时间的60%,这意味着仍需进行一些改进。 我们可以通过再次增加线程池大小来吸收额外的CPU吗?
实验4
在此最终运行中,池已配置为八个线程。 查看结果,我们可以看到,与预期的一样,平均请求数不到10,死区时间现在不到19%,退休请求数再次健康增长,达到了3621。当CPU利用率接近100%时,看起来在这些负载条件下我们可以实现的改进已接近尾声。 它还表明八个是理想的池大小。 我们可以得出的另一个结论是,如果我们需要消除更多的死区时间,那么唯一的方法就是增加更多的CPU或提高应用程序的CPU效率。
(点击图片放大)
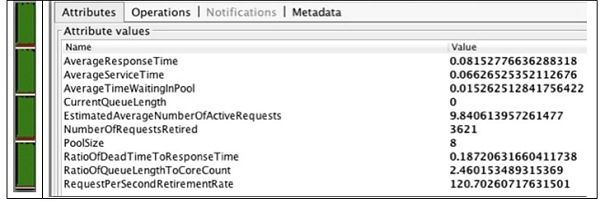
图5. 10个客户端请求,8个服务器线程的结果
理论与现实相遇
对此实验可能提出的各种批评之一是它过于简化。 大型应用程序很少只有一个线程或一个连接池。 实际上,对于每种使用的通信技术,许多应用程序都会有一个池。 例如,您的应用程序可能具有由servlet处理的HTTP请求,来自JMS的请求以及可能的JDBC连接池。 在这种情况下,您将拥有Servlet引擎的线程池。 您还将为JMS和JDBC组件提供一个连接池。 在这种情况下,要做的一件事就是将它们全部视为一个线程池。 这意味着我们将到达率与服务时间进行汇总。 通过使用利特尔定律作为汇总来研究系统,我们可以确定线程总数。 下一步是在多个线程组之间分配该数字。 分区逻辑可以使用多种技术中的一种,这当然会受到性能要求的影响。 一种技术是根据对硬件的单独需求来平衡线程池大小。 但是,相对于通过JMS发出的请求,将Web客户端优先级可能很重要,因此您可以在该方向上平衡池。 当然,在重新平衡时,您必须调整每个池的大小,以考虑所需硬件的差异。
另一个考虑因素是,这种表述着重于系统中的平均请求数。 由于许多原因,您可能想知道第90个百分位数的队列长度。 使用此值将为您提供更多的空间来应对到达率的自然波动。 达到这个数字要复杂得多,在平均值的顶部添加20%的缓冲区可能同样有效。 执行此操作时,只需确保您有足够的能力来处理那么多线程。 例如,由于在我们的示例中,八个线程使CPU耗尽,因此增加更多线程可能会开始降低性能。 最后,内核在管理线程方面比线程池有效得多。 因此,尽管我们猜测添加八个以上的线程可能没有好处,但是一项衡量指标可能告诉我们,我们的系统中确实确实存在更多可能被吸收的空间。 换句话说,请尝试超出容量(即压力测试),以查看它如何影响最终用户的响应时间和吞吐量。
结论
为线程池获取正确的配置可能并不容易,但这也不是火箭科学。 这个问题背后的数学是众所周知的,并且相当直观,因为我们在日常生活中一直都在遇到它们。 缺少的是做出合理选择所需的度量(作为jucExecutorService的见证)。 达到适当的设置会有点麻烦,因为这更像是桶式化学而不是精确的科学,但是花一点时间摆弄可以让您免去处理因超出预期工作负载而不稳定的系统的麻烦。
翻译自: https://www.infoq.com/articles/Java-Thread-Pool-Performance-Tuning/?topicPageSponsorship=c1246725-b0a7-43a6-9ef9-68102c8d48e1
java线程池动态调整大小