python批量爬取公众号文章
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 舴艋的舟
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http://t.cn/A6Zvjdun
爬取的方法多种多样,今天和大家分享一种较为简单的方法,即通过微信公众号后台的“超链接”功能进行爬取。可能有些小伙伴没有接触过微信公众号的后台,这里贴张图让大家了解一下
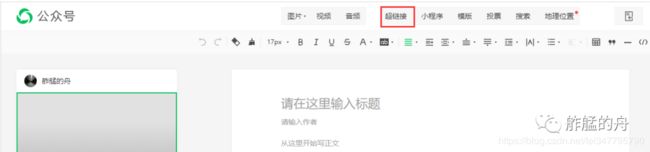
到这里有些小伙伴可能会说,我不能登录公众号后台怎么办???
没关系,虽然我们每次爬虫目的是为了得到我们想要的结果,但这并不是我们学习的重点,我们学习的重点是爬虫的过程,是我们如何去得到目标数据,所以不能登录公众号后台的小伙伴看完这篇文章可能无法获取到最终的爬取结果,但是看完这篇文章你同样会有所收获。
一、前期准备
选择爬取的目标公众号
点击超链接–进入编辑超链接界面–输入搜索我们需要爬取的目标公众号
今天我们就以爬取“数据分析”这个公众号为例为大家进行介绍
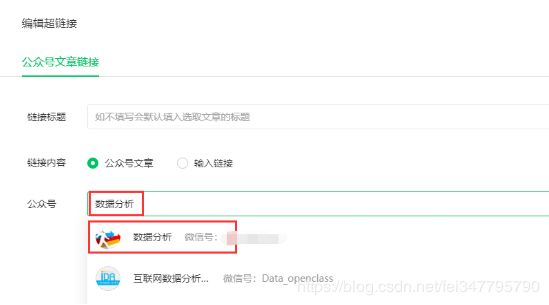
点击公众号可以看到每篇文章对应的标题信息
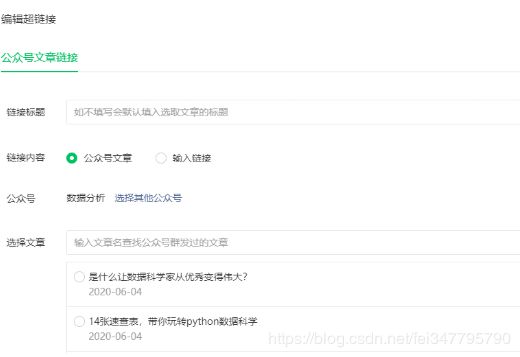
我们这次爬虫的目标就是得到文章标题以及对应的链接。
二、开始爬虫
爬虫三步曲:
- 请求网页
- 解析网页
- 保存数据
1、请求网页
首先导入我们本次爬虫需要用到的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
查找我们爬取的目标数据所在位置,点击通过查找得到的包,得到目标网址以及请求头信息
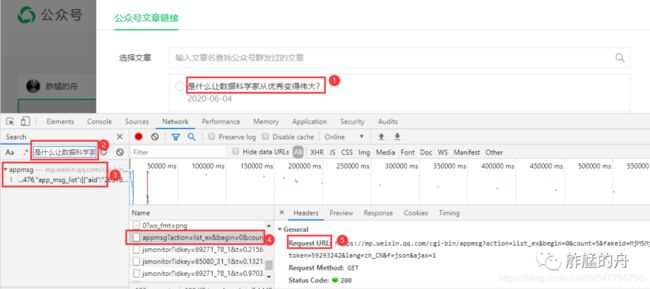
请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
这里的请求头信息必须添加上cookie的信息,否则无法得到网页信息
网页的请求结果如下图所示,红色框标出的为我们需要的文章标题以及文章链接

2、解析网页
从得到的网页响应结果中我们可以看到,每篇文章的标题和链接都分别在"title"标签和"cover"标签后面,所以我们可以采用正则表达式直接对其进行解析
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
解析后结果如下

3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到此本次的爬虫就已经完成,我们来看一下最终结果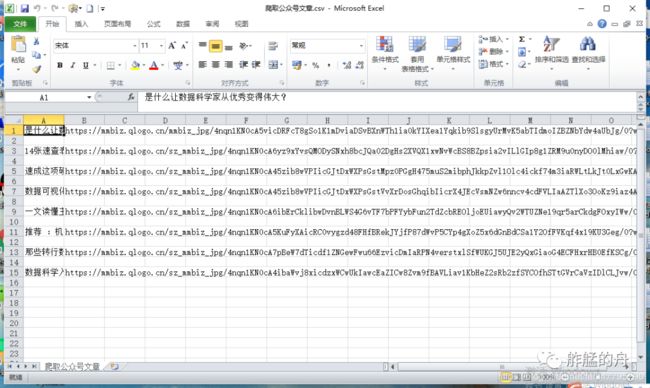
完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin='+str(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5