实验——基于pytorch的SRResNet的复现
本博文是对xintao前辈的这套代码中的SRResNet做实验时的笔记~代码如链接所示https://github.com/xinntao/BasicSR
先给出SRGAN paper的链接(https://arxiv.org/pdf/1609.04802.pdf)。作者在原文中是这样定义SRResNet的:
“We set a new state of the art for image SR with high upscaling factors (4x) as measured by PSNR and structural similarity (SSIM) with our 16 blocks deep ResNet (SRResNet) optimized for MSE.”
在本人之前的博文《学习笔记之——基于深度学习的图像超分辨率重构》也介绍过SRGAN(SRResNet),这里不对原理再做过多的描述,有兴趣者建议直接阅读原文。
代码在目录/home/guanwp/BasicSR-master/codes/下,运行以下命令实现train和test
python train.py -opt options/train/train_sr.json
python test.py -opt options/test/test_sr.json
注意下面截图

要训练SRGAN网络,应该是要用。但是本博文展示做的是SRResNet,接下来会有博文对SRGAN做补充(考虑到本人目前还没到可以训练好GAN网络的功力?,先不看SRGAN)
python train.py -opt options/train/train_esrgan.json
代码的分析
首先是setting文档(train_sr.json文件)
{
"name": "sr_resnet_baesline"//"001_RRDB_PSNR_x4_DIV2K" // please remove "debug_" during training or tensorboard wounld not work
, "use_tb_logger": true
, "model":"sr"
, "scale": 4
, "gpu_ids": [1]
, "datasets": {
"train": {
"name": "DIV2K800"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub_bicLRx4"
, "subset_file": null
, "use_shuffle": true
, "n_workers": 8
, "batch_size": 16//how many samples in each iters
, "HR_size": 192 // 128 | 192
, "use_flip": true
, "use_rot": true
}
, "val": {
"name": "val_set5"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/val_set5/Set5"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/val_set5/Set5_sub_bicLRx4"
}
}
, "path": {
"root": "/home/guanwp/BasicSR-master",
"pretrain_model_G": null
,"experiments_root": "/home/guanwp/BasicSR-master/experiments/",
"models": "/home/guanwp/BasicSR-master/experiments/sr_resnet_baesline/models",
"log": "/home/guanwp/BasicSR-master/experiments/sr_resnet_baesline",
"val_images": "/home/guanwp/BasicSR-master/experiments/sr_resnet_baesline/val_images"
}
, "network_G": {
"which_model_G": "sr_resnet"//"fsrcnn"//"sr_resnet" // RRDB_net | sr_resnet
, "norm_type": null
, "mode": "CNA"
, "nf": 64//56//64
, "nb": 23
, "in_nc": 3
, "out_nc": 3
, "gc": 32
, "group": 1
}
, "train": {
"lr_G": 1e-3//1e-3//2e-4
, "lr_scheme": "MultiStepLR"
, "lr_steps": [200000,400000,600000,800000,1000000,1500000]
, "lr_gamma": 0.5
, "pixel_criterion": "l1"//"l1"//'l2'//huber//Cross
, "pixel_weight": 1.0
, "val_freq": 5e3
, "manual_seed": 0
, "niter": 2e6//2e6//1e6
}
, "logger": {
"print_freq": 200
, "save_checkpoint_freq": 5e3
}
}
PSNR一直在十几,不上去,觉得改变一下setting看看效果
{
"name": "sr_resnet_x4_baesline"//"001_RRDB_PSNR_x4_DIV2K" // please remove "debug_" during training or tensorboard wounld not work
, "use_tb_logger": true
, "model":"sr"
, "scale": 4
, "gpu_ids": [1]
, "datasets": {
"train": {
"name": "DIV2K800"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub_bicLRx4"
, "subset_file": null
, "use_shuffle": true
, "n_workers": 8
, "batch_size": 16//how many samples in each iters
, "HR_size": 128 // 128 | 192
, "use_flip": true
, "use_rot": true
}
, "val": {
"name": "val_set5"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/val_set5/Set5"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/val_set5/Set5_sub_bicLRx4"
}
}
, "path": {
"root": "/home/guanwp/BasicSR-master",
"pretrain_model_G": null
,"experiments_root": "/home/guanwp/BasicSR-master/experiments/",
"models": "/home/guanwp/BasicSR-master/experiments/sr_resnet_baesline/models",
"log": "/home/guanwp/BasicSR-master/experiments/sr_resnet_baesline",
"val_images": "/home/guanwp/BasicSR-master/experiments/sr_resnet_baesline/val_images"
}
, "network_G": {
"which_model_G": "sr_resnet"//"fsrcnn"//"sr_resnet" // RRDB_net | sr_resnet
, "norm_type": null
, "mode": "CNA"
, "nf": 64//56//64
, "nb": 23
, "in_nc": 3
, "out_nc": 3
, "gc": 32
, "group": 1
}
, "train": {
"lr_G": 2e-4//1e-3//2e-4
, "lr_scheme": "MultiStepLR"
, "lr_steps": [200000,400000,600000,800000,1000000,1500000]
, "lr_gamma": 0.5
, "pixel_criterion": "l1"//"l1"//'l2'//huber//Cross
, "pixel_weight": 1.0
, "val_freq": 5e3
, "manual_seed": 0
, "niter": 2e6//2e6//1e6
}
, "logger": {
"print_freq": 200
, "save_checkpoint_freq": 5e3
}
}
# Generator
def define_G(opt):
gpu_ids = opt['gpu_ids']
opt_net = opt['network_G']
which_model = opt_net['which_model_G']#hear decide which model, and thia para is in .json. if you add a new model, this part must be modified
if which_model == 'sr_resnet': # SRResNet
netG = arch.SRResNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model=='fsrcnn':#FSRCNN
netG=arch.FSRCNN(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model == 'sft_arch': # SFT-GAN
netG = sft_arch.SFT_Net()
elif which_model == 'RRDB_net': # RRDB,this is ESRGAN
netG = arch.RRDBNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'],
nb=opt_net['nb'], gc=opt_net['gc'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'],
act_type='leakyrelu', mode=opt_net['mode'], upsample_mode='upconv')
else:
raise NotImplementedError('Generator model [{:s}] not recognized'.format(which_model))
if opt['is_train']:
init_weights(netG, init_type='kaiming', scale=0.1)###the weight initing. you can change this to change the method of init_weight
if gpu_ids:
assert torch.cuda.is_available()
netG = nn.DataParallel(netG)
return netG
在architecture.py文件中有SRResNst的结构
#####################SRResNet########################################################
class SRResNet(nn.Module):#read my CSDN for the nn.Module
#nn.Module is contain the forward and each layyer
def __init__(self, in_nc, out_nc, nf, nb, upscale=4, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):#the .jason file decide the mode is "CNA"
#input channels\output channels\the number of filters in the first layer\thw number of resduial block\upscale\ \relu\Conv -> Norm -> Act\
super(SRResNet, self).__init__()#for the super(),read my CSDN
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)#read the block.py.
resnet_blocks = [B.ResNetBlock(nf, nf, nf, norm_type=norm_type, act_type=act_type,\
mode=mode, res_scale=res_scale) for _ in range(nb)]#'nb' is the number of block, and there is 23 in the .jason
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)#here use the BN
if upsample_mode == 'upconv':
upsample_block = B.upconv_blcok##Deconvolution
elif upsample_mode == 'pixelshuffle':##there are 'pixelshuffle' in the network.py
upsample_block = B.pixelshuffle_block##the espcn
else:
raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
if upscale == 3:
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
else:
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*resnet_blocks, LR_conv)),\
*upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
block.py
from collections import OrderedDict
import torch
import torch.nn as nn
####################
# Basic blocks
####################
def act(act_type, inplace=True, neg_slope=0.2, n_prelu=1):
# helper selecting activation
# neg_slope: for leakyrelu and init of prelu
# n_prelu: for p_relu num_parameters
act_type = act_type.lower()
if act_type == 'relu':
layer = nn.ReLU(inplace)
elif act_type == 'leakyrelu':
layer = nn.LeakyReLU(neg_slope, inplace)
elif act_type == 'prelu':
layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)
else:
raise NotImplementedError('activation layer [{:s}] is not found'.format(act_type))
return layer
def norm(norm_type, nc):######################this is the part of normalization
# helper selecting normalization layer
norm_type = norm_type.lower()
if norm_type == 'batch':
layer = nn.BatchNorm2d(nc, affine=True)
elif norm_type == 'instance':
layer = nn.InstanceNorm2d(nc, affine=False)
else:
raise NotImplementedError('normalization layer [{:s}] is not found'.format(norm_type))
return layer
def pad(pad_type, padding):
# helper selecting padding layer
# if padding is 'zero', do by conv layers
pad_type = pad_type.lower()
if padding == 0:
return None
if pad_type == 'reflect':
layer = nn.ReflectionPad2d(padding)
elif pad_type == 'replicate':
layer = nn.ReplicationPad2d(padding)
else:
raise NotImplementedError('padding layer [{:s}] is not implemented'.format(pad_type))
return layer
def get_valid_padding(kernel_size, dilation):
kernel_size = kernel_size + (kernel_size - 1) * (dilation - 1)
padding = (kernel_size - 1) // 2
return padding
class ConcatBlock(nn.Module):
# Concat the output of a submodule to its input
def __init__(self, submodule):
super(ConcatBlock, self).__init__()
self.sub = submodule
def forward(self, x):
output = torch.cat((x, self.sub(x)), dim=1)
return output
def __repr__(self):
tmpstr = 'Identity .. \n|'
modstr = self.sub.__repr__().replace('\n', '\n|')
tmpstr = tmpstr + modstr
return tmpstr
class ShortcutBlock(nn.Module):
#Elementwise sum the output of a submodule to its input
def __init__(self, submodule):
super(ShortcutBlock, self).__init__()
self.sub = submodule
def forward(self, x):
output = x + self.sub(x)
return output
def __repr__(self):
tmpstr = 'Identity + \n|'
modstr = self.sub.__repr__().replace('\n', '\n|')
tmpstr = tmpstr + modstr
return tmpstr
def sequential(*args):
# Flatten Sequential. It unwraps nn.Sequential.
if len(args) == 1:
if isinstance(args[0], OrderedDict):
raise NotImplementedError('sequential does not support OrderedDict input.')
return args[0] # No sequential is needed.
modules = []
for module in args:
if isinstance(module, nn.Sequential):
for submodule in module.children():
modules.append(submodule)
elif isinstance(module, nn.Module):
modules.append(module)
return nn.Sequential(*modules)
def conv_block(in_nc, out_nc, kernel_size, stride=1, dilation=1, groups=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='CNA'):
'''
Conv layer with padding, normalization, activation
mode: CNA --> Conv -> Norm -> Act
NAC --> Norm -> Act --> Conv (Identity Mappings in Deep Residual Networks, ECCV16)
'''
assert mode in ['CNA', 'NAC', 'CNAC'], 'Wong conv mode [{:s}]'.format(mode)
padding = get_valid_padding(kernel_size, dilation)
p = pad(pad_type, padding) if pad_type and pad_type != 'zero' else None
padding = padding if pad_type == 'zero' else 0
c = nn.Conv2d(in_nc, out_nc, kernel_size=kernel_size, stride=stride, padding=padding, \
dilation=dilation, bias=bias, groups=groups)
a = act(act_type) if act_type else None
if 'CNA' in mode:#this was used in RESNET
n = norm(norm_type, out_nc) if norm_type else None#this is the setting of normalization, and the normalization of SRResNet is BN
return sequential(p, c, n, a)#padding, conv, normalization, active
elif mode == 'NAC':
if norm_type is None and act_type is not None:
a = act(act_type, inplace=False)
# Important!
# input----ReLU(inplace)----Conv--+----output
# |________________________|
# inplace ReLU will modify the input, therefore wrong output
n = norm(norm_type, in_nc) if norm_type else None
return sequential(n, a, p, c)
####################
# Useful blocks
####################
class ResNetBlock(nn.Module):
'''
ResNet Block, 3-3 style
with extra residual scaling used in EDSR
(Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW 17)
'''
def __init__(self, in_nc, mid_nc, out_nc, kernel_size=3, stride=1, dilation=1, groups=1, \
bias=True, pad_type='zero', norm_type=None, act_type='relu', mode='CNA', res_scale=1):
super(ResNetBlock, self).__init__()
conv0 = conv_block(in_nc, mid_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode)
if mode == 'CNA':
act_type = None
if mode == 'CNAC': # Residual path: |-CNAC-|
act_type = None
norm_type = None
conv1 = conv_block(mid_nc, out_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode)
# if in_nc != out_nc:
# self.project = conv_block(in_nc, out_nc, 1, stride, dilation, 1, bias, pad_type, \
# None, None)
# print('Need a projecter in ResNetBlock.')
# else:
# self.project = lambda x:x
self.res = sequential(conv0, conv1)
self.res_scale = res_scale
def forward(self, x):
res = self.res(x).mul(self.res_scale)
return x + res
class ResidualDenseBlock_5C(nn.Module):
'''
Residual Dense Block
style: 5 convs
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
'''
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv2 = conv_block(nc+gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv3 = conv_block(nc+2*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv4 = conv_block(nc+3*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
if mode == 'CNA':
last_act = None
else:
last_act = act_type
self.conv5 = conv_block(nc+4*gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=last_act, mode=mode)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(torch.cat((x, x1), 1))
x3 = self.conv3(torch.cat((x, x1, x2), 1))
x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
return x5.mul(0.2) + x
class RRDB(nn.Module):
'''
Residual in Residual Dense Block
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)
'''
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(RRDB, self).__init__()
self.RDB1 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB2 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB3 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
out = self.RDB3(out)
return out.mul(0.2) + x
####################
# Upsampler
####################
def pixelshuffle_block(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu'):
'''
Pixel shuffle layer
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional
Neural Network, CVPR17)
'''
conv = conv_block(in_nc, out_nc * (upscale_factor ** 2), kernel_size, stride, bias=bias, \
pad_type=pad_type, norm_type=None, act_type=None)
pixel_shuffle = nn.PixelShuffle(upscale_factor)
n = norm(norm_type, out_nc) if norm_type else None
a = act(act_type) if act_type else None
return sequential(conv, pixel_shuffle, n, a)
def upconv_blcok(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='nearest'):
# Up conv
# described in https://distill.pub/2016/deconv-checkerboard/
upsample = nn.Upsample(scale_factor=upscale_factor, mode=mode)
conv = conv_block(in_nc, out_nc, kernel_size, stride, bias=bias, \
pad_type=pad_type, norm_type=norm_type, act_type=act_type)
return sequential(upsample, conv)
整体的网络结构如下:
-------------- Generator --------------
SRResNet(
(model): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Identity +
|Sequential(
| (0): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (1): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (2): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (3): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (4): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (5): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (6): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (7): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (8): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (9): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (10): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (11): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (12): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (13): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (14): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (15): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (16): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (17): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (18): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (19): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (20): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (21): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (22): ResNetBlock(
| (res): Sequential(
| (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| (1): ReLU(inplace)
| (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
| )
| )
| (23): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
|)
(2): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): PixelShuffle(upscale_factor=2)
(4): ReLU(inplace)
(5): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): PixelShuffle(upscale_factor=2)
(7): ReLU(inplace)
(8): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace)
(10): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
原文的结果

SRResNet为32.05dB。而FSRCNN在x4时,为30.55dB(由于我之前训练时,一个多小时就可以达到原文的效果,所以没有继续训练下去了)
训练结果
结果如下图所示,包括了原实现(虽然没训练完,但是效果已经比原文要好了)

SRResNet的原文实现
(应该是原文实现,上面的采用了23个block,原文写道采用16个block)

(https://github.com/twtygqyy/pytorch-SRResNet)
参考上面代码,将关键部分重塑如下:
network.py
# Generator
def define_G(opt):
gpu_ids = opt['gpu_ids']
opt_net = opt['network_G']
which_model = opt_net['which_model_G']#hear decide which model, and thia para is in .json. if you add a new model, this part must be modified
if which_model == 'sr_resnet': # SRResNet
netG = arch.SRResNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model=='fsrcnn':#FSRCNN
netG=arch.FSRCNN(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
#############################################################################################################
elif which_model=='srresnet':#SRResNet, the Original version
netG=arch.OSRRESNET(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model == 'sft_arch': # SFT-GAN
netG = sft_arch.SFT_Net()
elif which_model == 'RRDB_net': # RRDB,this is ESRGAN
netG = arch.RRDBNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'],
nb=opt_net['nb'], gc=opt_net['gc'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'],
act_type='leakyrelu', mode=opt_net['mode'], upsample_mode='upconv')
else:
raise NotImplementedError('Generator model [{:s}] not recognized'.format(which_model))
if opt['is_train']:
init_weights(netG, init_type='kaiming', scale=0.1)###the weight initing. you can change this to change the method of init_weight
if gpu_ids:
assert torch.cuda.is_available()
netG = nn.DataParallel(netG)
return netG
在architecture.py中
##########################################################################################################
#SRResNet, the Original version
#define the residual block
class O_Residual_Block(nn.Module):
def __init__(self):
super(O_Residual_Block,self).__init__()
self.conv1=nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1=nn.BatchNorm2d(64, affine=True)
self.prelu=nn.PReLU()
self.conv2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2=nn.BatchNorm2d(64, affine=True)
def forward(self, x):
identity_data = x
output = self.prelu(self.bn1(self.conv1(x)))
output = self.bn2(self.conv2(output))
output = torch.add(output,identity_data)
return output
##############################################
class OSRRESNET(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, upscale=2, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):##play attention the upscales
super(OSRRESNET,self).__init__()
self.conv_input=nn.Conv2d(in_channels=in_nc,out_channels=nf,kernel_size=9,stride=1,padding=4,bias=False)
self.prelu=nn.PReLU()
self.residual=self.make_layer(O_Residual_Block,16)
self.conv_mid = nn.Conv2d(in_channels=nf, out_channels=nf, kernel_size=3, stride=1, padding=1, bias=False)
self.bn_mid=nn.BatchNorm2d(64, affine=True)
self.upscale4x = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2),
nn.PReLU(),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2),
nn.PReLU(),
)
self.conv_output = nn.Conv2d(in_channels=nf, out_channels=out_nc, kernel_size=9, stride=1, padding=4, bias=False)
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
def forward(self,x):
out = self.prelu(self.conv_input(x))
residual = out
out = self.residual(out)
out = self.bn_mid(self.conv_mid(out))
out = torch.add(out,residual)
out = self.upscale4x(out)
out = self.conv_output(out)
return out
##########################################################################################################################################################
setting如下
{
"name": "or_sr_resnet_x4"//"001_RRDB_PSNR_x4_DIV2K" // please remove "debug_" during training or tensorboard wounld not work
, "use_tb_logger": true
, "model":"sr"
, "scale": 4
, "gpu_ids": [2]
, "datasets": {
"train": {
"name": "DIV2K800"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub_bicLRx4"
, "subset_file": null
, "use_shuffle": true
, "n_workers": 8
, "batch_size": 16//how many samples in each iters
, "HR_size": 128 // 128 | 192
, "use_flip": true
, "use_rot": true
}
, "val": {
"name": "val_set5"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/val_set5/Set5"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/val_set5/Set5_sub_bicLRx4"
}
}
, "path": {
"root": "/home/guanwp/BasicSR-master",
"pretrain_model_G": null
,"experiments_root": "/home/guanwp/BasicSR-master/experiments/",
"models": "/home/guanwp/BasicSR-master/experiments/or_sr_resnet_x4/models",
"log": "/home/guanwp/BasicSR-master/experiments/or_sr_resnet_x4",
"val_images": "/home/guanwp/BasicSR-master/experiments/or_sr_resnet_x4/val_images"
}
, "network_G": {
"which_model_G": "srresnet"//"sr_resnet"//"fsrcnn"//"sr_resnet" // RRDB_net | sr_resnet
, "norm_type": null
, "mode": "CNA"
, "nf": 64//56//64
, "nb": 23
, "in_nc": 3
, "out_nc": 3
, "gc": 32
, "group": 1
}
, "train": {
"lr_G": 2e-4//1e-3//2e-4
, "lr_scheme": "MultiStepLR"
, "lr_steps": [200000,400000,600000,800000,1000000,1500000]
, "lr_gamma": 0.5
, "pixel_criterion": "l1"//"l1"//'l2'//huber//Cross
, "pixel_weight": 1.0
, "val_freq": 5e3
, "manual_seed": 0
, "niter": 2e6//2e6//1e6
}
, "logger": {
"print_freq": 200
, "save_checkpoint_freq": 5e3
}
}
网络结构如下
-------------- Generator --------------
OSRRESNET(
(conv_input): Conv2d(3, 64, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4), bias=False)
(prelu): PReLU(num_parameters=1)
(residual): Sequential(
(0): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(6): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(7): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(8): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(9): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(10): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(11): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(12): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(13): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(14): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(15): O_Residual_Block(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=1)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(conv_mid): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn_mid): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(upscale4x): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelShuffle(upscale_factor=2)
(2): PReLU(num_parameters=1)
(3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): PixelShuffle(upscale_factor=2)
(5): PReLU(num_parameters=1)
)
(conv_output): Conv2d(64, 3, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4), bias=False)
)
补充:
关于nn.LeakyReLU

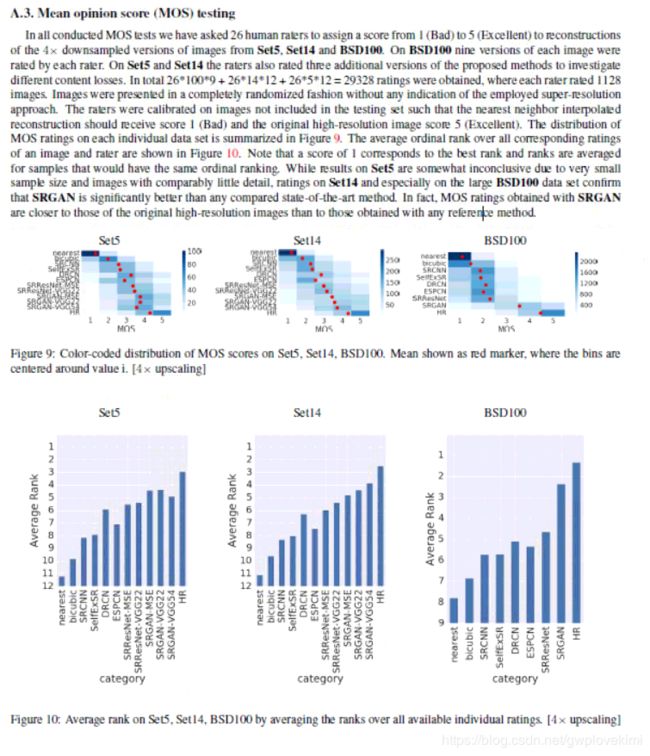
关于MOS test
给出原文的supplementary file截图如下,由于本人觉得NIQE更加有代表性,所以就不对MOS做深入的描述。接下来会有博客描述NIQE