Kaggle泰坦尼克号船难--逻辑回归预测生存率
Kaggle泰坦尼克号船难–逻辑回归预测生存率#一、题目
https://www.kaggle.com/c/titanic
二、题意分析
train.csv中有891条泰坦尼克号乘客的数据,包括这些乘客的一些特征与获救情况。
test.csv中有418条乘客的数据,包括这些乘客的一些特征但不包括获救情况。
根据train.csv中乘客的特征与获救情况,预测test.csv中乘客的获救概率。
三、编程环境准备
(一)操作系统:Win 10
(二)编程语言:Python 3.6
Win 10安装Python 3.6
(三)需要的库:numpy + pandas + matplotlib + sklearn
Win 10安装numpy、pandas、scipy、matplotlib和sklearn
Win 10系统matplotlib中文无法显示的解决方案
(四)交互式编程环境ipython notebook
Win 10基于Python 3.6安装IPython Notebook
四、数据分析
1. 查看train.csv中的数据
import pandas as pd #数据分析
import numpy as np #科学计算
from pandas import Series,DataFrame
data_train = pd.read_csv("train.csv")
data_train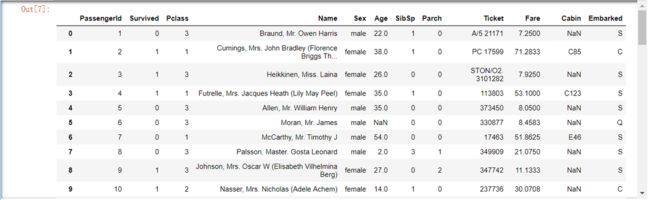
这些数据就是train.csv中的原始数据了,只不过这里是在ipython notebook环境中显示罢了。显示格式类似excel格式。
2. 查看数据的基本信息
data_train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB总共有12列数据:
PassengerId:乘客编号
Survived:是否生存,1表生存,0表示遇难
Pclass:舱位等级,分为一等舱、二等舱、三等舱
Name:乘客姓名
Sex:性别,Male或Female
Age:年龄
SibSp:兄弟姐妹、堂兄弟姐妹人数
Parch:父母与子女个数
Ticket:船票信息(上面记载着座位号)
Fare:票价
Cabin:客舱
Embarked:登船港口这12列数据中,有9列数据是完整的,即有891条记录;
Embarked这一列,数据缺失了两条;
Age这一列,差了一百多条数据;
Cabin这一列,数据很不完整,只有204条记录。
3. 查看数据的描述性统计
data_train.describe()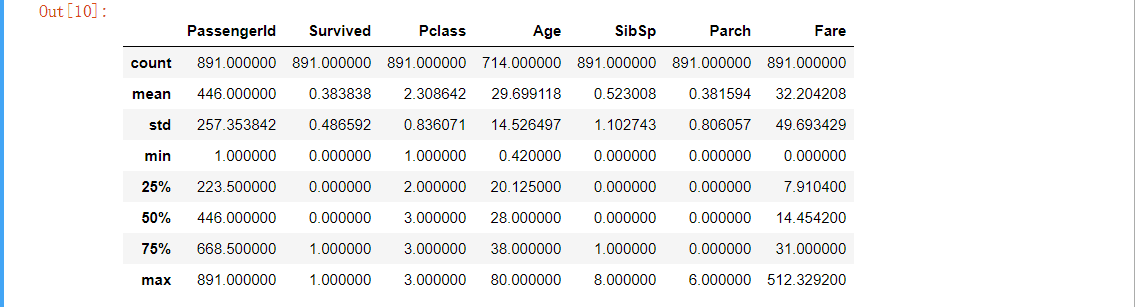
(1)总共有12列数据,这里只列出了7列,为什么呢?
因为Name、Ticket和Cabin是文本信息,Sex和Embarked是类目信息,无法统计出来。
(2)pandas中的std为样本标准差。例:x = {1, 2, 3},则平均数x’ = (1 + 2 + 3) / 3 = 2
样本方差(无偏)D = [abs(1 - 2) + abs(2 - 2) + abs(3 - 3)] / 2 = 1
样本标准差(无偏)= sqrt(D) = 1
(3)仍以 x = {1, 2, 3}为例
min值 = 0%值 = 1
25%值 = 1.5
50%值 = 2
75%值 = 2.5
max值 = 100%值 = 3
(4)计算mean的时候,会自动剔除没有记录的数据。以
x = {10, NaN, 20, NaN, 30}为例,平均值 = (10 + 20 + 30) / 3 = 20
(5)从上表结果可以看出,生存率平均值为0.383838,说明遇难人数一大半;Pclass的平均值为2.3,说明坐3等舱的乘客居多,因为通常3等舱的价格最便宜舱位最多;平均年龄29.7岁,结合表格可以看出,很多成年人带了年幼的小孩,导致平均年龄较小。
五、数据分析
(一)乘客属性分布
import matplotlib.pyplot as plt
fig = plt.figure()
fig.set_size_inches(12, 12) #设置画布尺寸
plt.subplot2grid((2,2),(0,0))
data_train.Survived.value_counts().plot(kind='bar')
plt.title(u"获救情况 (1为获救)")
plt.ylabel(u"人数")
plt.subplot2grid((2,2),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,2),(1,0))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.subplot2grid((2,2),(1,1))
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best')
plt.show()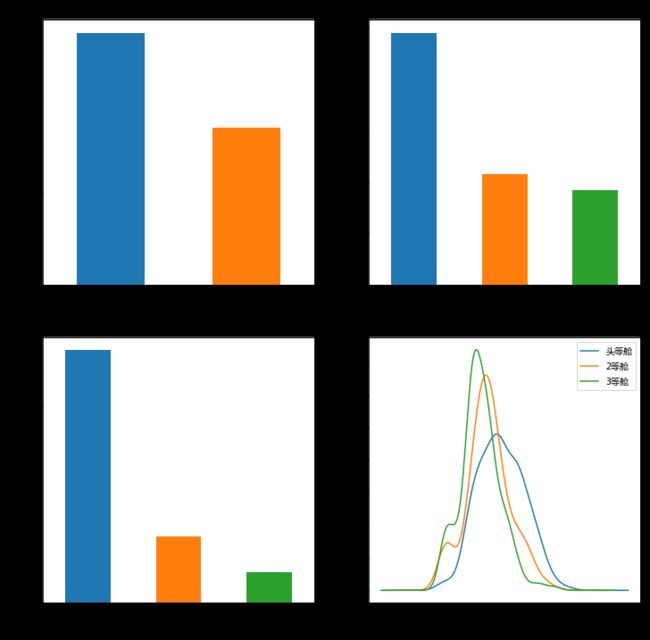
从上面的几个图可以看出:
遇难人数占一大半;
三等舱位的乘客最多,按照出行常识,应该是三等舱座位多价格便宜;
多数人从S口上船,是不是可以推测:S口就是普通登船口,C口和Q口是不是专用登船口?
三等舱人数 > 二等舱人数 > 一等舱人数,头等舱乘客年龄 > 二等舱乘客年龄 > 三等舱乘客年龄,这是因为年龄越大,财富越多,越倾向于买高档的舱位。
二、三等舱多数人的年龄介于20~40之间,并且二三等舱人数比较多,这可以和平均年龄29.7岁相呼应。
(二)获救与各属性的关联统计
1. 年龄属性与获救的关联
fig = plt.figure()
fig.set_size_inches(12, 12) # 设置画布尺寸
plt.subplot2grid((2,2),(0,0))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")
plt.show()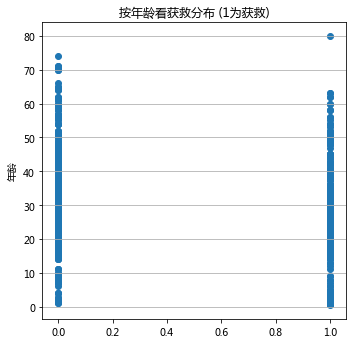
上图中蓝色的点表示有这个年龄。
可以看出,大体上,无论是获救(x = 1.0)还是未获救(x = 0.0)都有年龄分布,没有什么规律。
但是65~75岁的年龄段没有获救的人,但有遇难的人,考虑到这个年龄段的乘客数量很少,可能说明不了什么问题。
2. 舱位等级与获救的关联
# 各舱位等级的获救情况
fig = plt.figure()
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
可以看出,头等舱的获救机会 > 二等舱的获救机会 > 三等舱的获救机会。说明越有钱,买的舱位越好,获救概率越高。
3. 性别与获救的关联
#看看各性别的获救情况
fig = plt.figure()
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()
可以看出,女性的获救概率远大于男性。说明Lady first被执行得不错。
4. 舱位等级结合性别的获救情况
# 各种舱级别情况下各性别的获救情况
fig=plt.figure()
fig.set_size_inches(14, 7)
plt.title(u"根据舱等级和性别的获救情况")
ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=45)
ax1.legend([u"女性/高级舱"], loc='best')
ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=45)
plt.legend([u"女性/低级舱"], loc='best')
ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')
ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')
plt.show()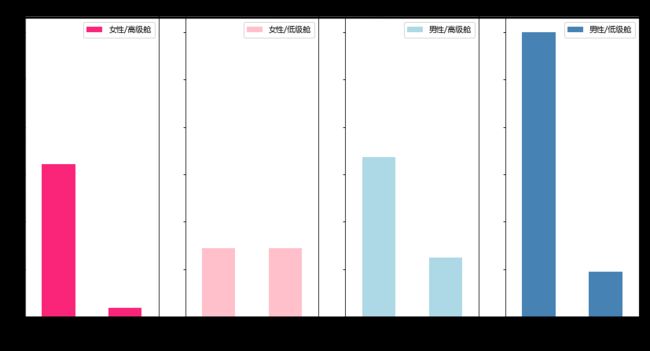
明显可以看出,坐头等舱的女性获救的概率接近100%,坐二三等舱的女生获救概率接近50%。男性无论是坐头等舱还是二三等舱,获救概率都比较低,尤其是坐二三等舱获救的概率更低。
5. 登船港口的获救情况
fig = plt.figure()
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
plt.show()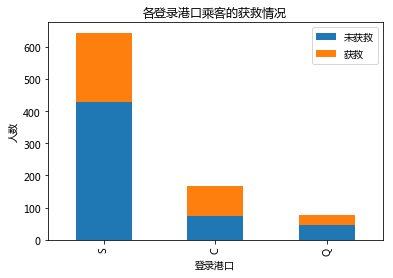
看起来,C港口获救概率要高一点,S港口和Q港口的获救概率较低。
6. (堂)兄弟姐妹与父母子女数量对获救的影响
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print (df)
g = data_train.groupby(['Parch','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print (df) PassengerId
SibSp Survived
0 0 398
1 210
1 0 97
1 112
2 0 15
1 13
3 0 12
1 4
4 0 15
1 3
5 0 5
8 0 7
PassengerId
Parch Survived
0 0 445
1 233
1 0 53
1 65
2 0 40
1 40
3 0 2
1 3
4 0 4
5 0 4
1 1
6 0 1上面的运行结果,看不出什么规律。
7. 船舱信息对获救的影响
#ticket是船票编号,应该是unique的,和最后的结果没有太大的关系,先不纳入考虑的特征范畴
#cabin只有204个乘客有值,我们先看看它的一个分布
data_train.Cabin.value_counts()G6 4
C23 C25 C27 4
B96 B98 4
F2 3
F33 3
C22 C26 3
E101 3
D 3
C83 2
C123 2
C92 2
F4 2
B77 2
D20 2
B51 B53 B55 2
C2 2
B22 2
E121 2
D35 2
E8 2
D33 2
B20 2
D36 2
B49 2
D17 2
C78 2
F G73 2
C125 2
E25 2
B28 2
..
C148 1
B69 1
E31 1
E46 1
A23 1
E58 1
C32 1
D7 1
D45 1
C111 1
E17 1
A31 1
F E69 1
D10 D12 1
A10 1
D48 1
C95 1
T 1
C106 1
C30 1
E68 1
B102 1
C101 1
D11 1
B101 1
B79 1
D15 1
C128 1
B38 1
E10 1
Name: Cabin, Length: 147, dtype: int64这些信息很不集中,很难看出问题来。并且也不知道G6, C23, C25这一类的信息是什么意思。只能做个推测:字母代表船舱(房间)号,数字代表床位(座位)号;或者字母代表楼层号,数字代表房间号。
注意Cabin只有204条记录,缺失了700多条记录。缺失的原因可能有两种:
(1)本来是有的,可能后来由于什么原因,信息丢失了
(2)本来就没有这些信息。比如可能只有一等舱二等舱有这种信息,三等舱没有这种信息(想像一个大屋,没有固定的座位,大家随便坐)
咱们从一个较粗的粒度–Cabin信息的有无来试一下:
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose()
df.plot(kind='bar', stacked=True)
plt.title(u"按Cabin有无看获救情况")
plt.xlabel(u"Cabin有无")
plt.ylabel(u"人数")
plt.show()
可以看出,有Cabin信息的获救概率明显大于无Cabin信息,这是不是意味着第二种猜测(即本来就没有这些信息)才是对的呢?
六、数据预处理
数据分析完之后,可以对部分数据进行预处理。
(一)Cabin和Age预处理
Cabin和Age缺失较多,咱们可以先对这两个字段进行处理。
Cabin可以按上面的分析,先处理成Yes和No两种类型。
对于Age,通常遇到缺值的情况,我们会有几种常见的处理方式:
(1)如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
(2)如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
(3)如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
(4)有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
本例中,后两种处理方式应该都是可行的,我们先试试按第(4)种方式拟合补全Age数据。
我们这里用scikit-learn中的随机森林方法(RandomForest)来拟合一下缺失的年龄数据
# 注意,若第二次运行本程序,会报"ValueError: Found array with 0 sample(s) (shape=(0, 4)) while a minimum of 1 is required.",
# 这是因为在上次运行本段程序时,data_train已经发生了变化
# 解决方案:不要连续运行本程序,在再次运行本程序之前,要先运行上面第一段程序,以获得原data_train的值
from sklearn.ensemble import RandomForestRegressor
### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1:])
# 用得到的预测结果填补原缺失数据
df.loc[df.Age.isnull(), 'Age'] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
data_train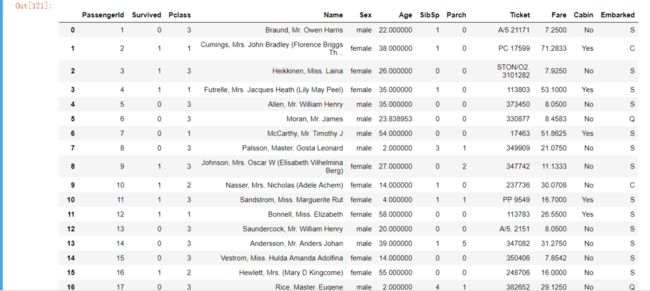
可以看到,Age和Cabin的值已处理。
(二)特征因子化
因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。
什么叫做因子化呢?举个例子:
以Cabin为例,原本它只是一个属性,因为其取值可以是[‘yes’,’no’],而将其平展开为’Cabin_yes’,’Cabin_no’两个属性
原本Cabin取值为yes的,在此处的”Cabin_yes”下取值为1,在”Cabin_no”下取值为0
原本Cabin取值为no的,在此处的”Cabin_yes”下取值为0,在”Cabin_no”下取值为1
我们使用pandas的”get_dummies”来完成这个工作,并拼接在原来的”data_train”之上,如下所示。
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
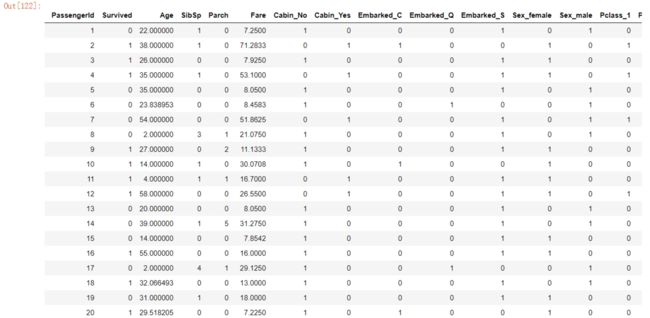
df上面的程序是将Cabin处理成Cabin_Yes和Cabin_No,Embarked处理成Embarked_C、Embarked_Q和Embarked_S,Sex处理成Sex_Male和Sex_Female,Pclass处理成Pclass_1、Pclass_2和Pclass_3;
接着用concat函数将这些新的属性连接到dataframe中,再通过drop函数将原先的Pclass、Name、Sex、Ticket、Cabin和Embarked这六个属性从dataframe中去掉。
(三)数据标准化
注意Age和Fare这两个属性的数据取值范围太大,这将对逻辑回归的收敛造成不利的影响。处理方法是将其标准化。
标准化就是将特征数据的分布调整成标准正太分布,也叫高斯分布,也就是使得数据的均值为0,方差为1。
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df['Age'].values.reshape(-1, 1))
df['Age_scaled'] = scaler.fit_transform(df['Age'].values.reshape(-1, 1), age_scale_param)
fare_scale_param = scaler.fit(df['Fare'].values.reshape(-1, 1))
df['Fare_scaled'] = scaler.fit_transform(df['Fare'].values.reshape(-1, 1), fare_scale_param)
df
至此,我们已把需要的属性值抽出来,转成scikit-learn里面LogisticRegression可以处理的格式。
七、逻辑回归建模
(一)建立模型
把需要的特征字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression来生成模型
from sklearn import linear_model
# 用正则取出我们要的属性值
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到LogisticRegression之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
clf生成的模型如下:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l1', random_state=None, solver='liblinear', tol=1e-06,
verbose=0, warm_start=False)(二)对测试数据集进行预处理
测试集预处理的过程和训练集的预处理过程一样
data_test = pd.read_csv("test.csv")
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'].values.reshape(-1, 1), age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'].values.reshape(-1, 1), fare_scale_param)
df_test
(三)预测
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("predicted_result.csv", index=False)
result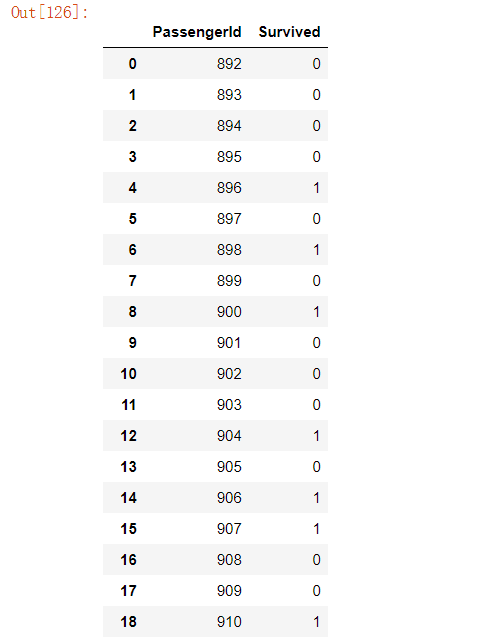
此时,在项目目录下,可观察到新生成了predicted_result.csv文件
(四)提交结果
将predicted_result.csv提交到kaggle上:
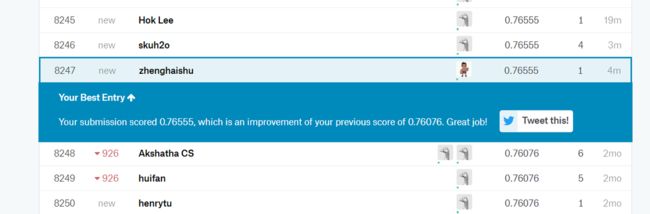
预测准确率为76.55%,因为模型比较粗糙,这个结果算是差强人意。
八、优化
(一)模型系数分析
把模型系数和特征关联起来
pd.DataFrame({"columns":list(train_df.columns)[1:], "coef":list(clf.coef_.T)})
从相关系数可以看出
(1)有Cabin信息的,获救概率会大很多。除了从有无这个较粗的维度来分析外,是否可以从Cabin信息本身来进一步挖掘比如字母和数字对获救概率的影响?
(2)若从S港口登船,获救概率会明显降低,但是C港口和Q港口的系数为0,这与上面的分析是不完全匹配。图5-6显示,S港口和Q港口获救率比较低,C口的获救率为50%左右。所以C口的相关系数为0有道理,但是Q口的相关系数为0则不太合理。另外,S、Q和C分别代表什么意思呢?所以说做数据挖掘时,熟悉业务也是很重要的。
(3)从性别来看,女性极大的提高获救率,男性较大降低获救率。
(4)从舱位等级来看,一等舱的获救率较高,而三等舱获救率大幅降低。有钱就是好啊。
(5)从年龄来看,负相关,年龄越小获救率越高,年龄越大获救率越低。年龄越小越容易获救这好理解,但是年龄越大呢?有时候遇到危险时,“小孩、妇女和老人先走”,这里年龄越大是不是有个范围呢?比如20-60岁年龄越大获救率越低,但是60岁以上的乘客获救会不会大一点?是否考虑设个系数体现两头值的影响?或者按年龄段来分析,比如每隔5岁作为一个年龄段?
(6)票价Fare也有影响。但相关系数比较低。相关系数比较低,是因为真的影响很小,还是因为挖掘的不够?按常理头等舱的票价会更贵,应该对获救概率有所影响。
(二)交叉验证
交叉验证通常是把train.csv分成两部分,一部分用于训练模型,另外一部分数据用来预测结果,然后将预测结果与实际结果比较,这样就能知道模型的预测效果。
用scikit-learn的cross_validation来完成这个工作。先看看cross validation情况下的打分:
from sklearn import cross_validation
#简单看看打分情况
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
all_data = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
X = all_data.as_matrix()[:,1:]
y = all_data.as_matrix()[:,0]
print (cross_validation.cross_val_score(clf, X, y, cv=5))[0.81564246 0.81564246 0.78651685 0.78651685 0.81355932]预测结果比先前的结果要好一点,因为用的是不同的数据集。
(三)提取bad case
做数据分割并且在原始数据集提取bad case
# 分割数据,按照 训练数据:cv数据 = 7:3的比例
split_train, split_cv = cross_validation.train_test_split(
df, test_size=0.3, random_state=0)
train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
# 生成模型
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(train_df.as_matrix()[:,1:], train_df.as_matrix()[:,0])
# 对cross validation数据进行预测
cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(cv_df.as_matrix()[:,1:])
origin_data_train = pd.read_csv("train.csv")
bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.as_matrix()[:,0]]['PassengerId'].values)]
bad_cases总共提取到50条bad case记录:
拿到bad cases之后,仔细分析,有可能会产生新的想法或思路。比如有一部分可能会印证在系数分析部分的猜测,那这些优化的想法的优先级可以放高一些。
现在有了”train_df” 和 “vc_df” 两个数据部分,前者用于训练model,后者用于评定和选择模型。可以考虑做一些优化操作,比如:
(1)Age属性不使用上面的拟合方式,而是根据名称中的“Mr”、“Mrs”、“Miss”等的平均值进行填充。
(2)Age不做成一个连续值属性,而是使用一个步长进行离散化,变成离散的类目特征。
(3)Cabin再细化一些,对于有记录的Cabin属性,我们将其分为前面的字母部分(可能是位置和船层之类的信息) 和 后面的数字部分(应该是房间号,有意思的事情是,如果你仔细看看原始数据,你会发现,这个值大的情况下,似乎获救的可能性高一些)。
(4)Pclass和Sex俩太重要了,我们试着用它们去组出一个组合属性来试试,这也是另外一种程度的细化。
(5)单加一个Child字段,Age<=12的,设为1,其余为0(你去看看数据,确实小盆友优先程度很高啊)
(6)如果名字里面有“Mrs”,而Parch>1的,我们猜测她可能是一个母亲,应该获救的概率也会提高,因此可以多加一个Mother字段,此种情况下设为1,其余情况下设为0
(7)把堂兄弟/兄妹和Parch还有自己 个数加在一起组一个Family_size字段(考虑到大家族可能对最后的结果有影响)
(8)Name是一个我们一直没有触碰的属性,我们可以做一些简单的处理,比如说男性中带某些字眼的(“Capt”, “Don”, “Major”, “Sir”)可以统一到一个Title,女性也一样。
(四)过拟合和欠拟合
在训练模型时,经常会产生过拟合或欠拟合的问题。
在统计学或机器学习中,拟合指的是逼近目标函数的远近程度。统计学或机器学习通常通过用于描述函数和目标函数逼近的吻合程度来描述拟合的好坏。
当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,我们称过拟合发生了。这意味着训练数据中的噪音或者随机波动也被当做特征被模型学习了。而问题就在于这些概念不适用于新的数据,从而导致模型泛化性能变差。
欠拟合就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据 。
当训练集和验证集准确度都很低时,则一般是欠拟合,(此时训练集和验证集损失error都比较大)
而当训练集准确度很高而验证集准确度很低时,则一般是过拟合(此时训练集损失error比较小而验证集比较大)。
一开始我们的模型往往是欠拟合的,也正是因为如此才有了优化的空间,我们需要不断的调整算法来使得模型的预测能力变得更强。但是优化到了一定程度可能会产生过拟合的问题,这时就需要解决过拟合的问题了。
(五)学习曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.gca().invert_yaxis()
plt.show()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
plot_learning_curve(clf, u"学习曲线", X, y)
从上图大致可以看出,训练集和交叉验证集上的得分曲线走势还是符合预期的。
从目前的曲线来看,我们的模型并不处于过拟合的状态(过拟合的表现一般是训练集上得分高,而交叉验证集上要低很多,中间的gap比较大)。因此我们可以再做些特征工程的工作,添加一些新产出的特征或者组合特征到模型中。
九、模型融合
先举个例子:
你和班上的某个学霸关系很好,每次作业都“模仿”他,于是大多数情况下,他做对了,你也对了。但是大神一旦做错了,你也只能跟着一起错。。
再来看看另外一个场景,你和班上的5学霸关系都很好,每次都把他们作业拿过来,对比一下,再“自己做”,如果哪天某学霸写错了,但是另外四个写对了,从概率的角度来讲,你肯定会选择另外四个学霸的答案,对吧?
模型融合也是这样的道理。
所谓模型融合,是按照不同的思路来组合基础模型,在保证准确度的同时也提升了模型防止过拟合的能力。
模型融合的方法有Voting, Averaging, Ranking, Binning, Bagging, Boosting, Stacking, Blending等。
我们现在只讲了logistic regression,如果我们还想用这个融合思想去提高我们的结果,该怎么做呢?
既然这个时候模型没得选,那咱们就在数据上动脑筋。如果模型出现过拟合,一定是在我们的训练上出现拟合过度造成的。
那我们干脆就不要用全部的训练集,每次取训练集的一个子集做训练,这样,我们虽然用的是同一个机器学习算法(逻辑回归),但是得到的模型却是不一样的;同时,因为我们没有任何一份子数据集是全的,因此即使出现过拟合,也是在子训练集上出现过拟合,而不是全体数据上,这样做一个融合,可能对最后的结果有一定的帮助。这种方法就是Bagging方法。
我们用scikit-learn里面的Bagging来完成上面的思路。
from sklearn.ensemble import BaggingRegressor
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*|Mother|Child|Family|Title')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到BaggingRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y)
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*|Mother|Child|Family|Title')
predictions = bagging_clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("predicted_bagging_result.csv", index=False)运行之后,在项目的路径下就会生成predicted_bagging_reslult.csv。
将predicted_bagging_result.csv提交到kaggle上

可以看到,预测的准确度略有提升。
虽然提升的不多,但是模型融合的思路是初学者必须掌握的。
十、Github代码下载
https://github.com/zhenghaishu/Kaggle
十一、参考资料
https://blog.csdn.net/han_xiaoyang/article/details/49797143
TopCoder & Codeforces & AtCoder交流QQ群:648202993
更多内容请关注微信公众号
