SpringIoC初始化BeanDefinition解析——Resource的定位
SpringIoC初始化BeanDefinition解析——Resource的定位
SpringIoC容器启动时会执行BeanDefinition的Resource定位、载入和注册。通过这个过程使得spring拥有了所有的bean的定义,为后续的bean的创建、自动注入和销毁提供了数据支持。本文主要说明spring如何找到所有的配置文件,即如何得到内部数据结构Resource的。
开发人员在创建spring容器的时候会传入配置文件的位置,或者是web工程中web.xml里以param的形式传入,或者在new的时候作为参数传入。总之在容器中最终会有个字符串数组表示位置文件的位置,它定义在AbstractRefreshableConfigApplicationContext中,如果你熟悉spring,相信会很熟悉这个类。它是FileSystemXmlApplicationContext、ClassPathXmlApplicationContext以及XmlWebApplicationContext的父类。为什么是字符串数组?我记得传进去的只是一个字符串呀。因为spring会自动把传入的字符串转成数组,并且数组的允许你用多个字符串表示配置文件的位置。说的有点小儿科,但是想想在自己设计系统的时候如果没有充分考虑的话,后面会出现很多问题。
接下来直入主题,以XmlWebApplicationContext为例来看看是怎么进行配置文件的读取的.下图是loadBeanDefinitions(DefaultListableBeanFactory beanFactory)方法的调用关系,可以看到这个方法会在容器refresh的时候执行。
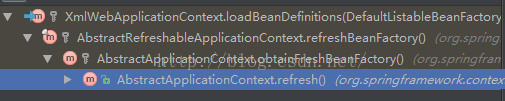
下面来看看loadBeanDefinitions都干了些什么。首先,它创建了一个XmlBeanDefinitionReader对象,一会儿会具体说明一下这个类,因为容器会委托这个类从xml配置文件中解析得到BeanDefinition;然后initBeanDefinitionReader其实是个空方法;接下来的任务就给了XmlBeanDefinitionReader。
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this); // 设置resourceLoader,传入的是容器本身
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
loadBeanDefinitions(beanDefinitionReader);
} protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws IOException {
String[] configLocations = getConfigLocations();
if (configLocations != null) {
for (String configLocation : configLocations) {
reader.loadBeanDefinitions(configLocation);
}
}
} public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int counter = 0;
for (Resource resource : resources) {
counter += loadBeanDefinitions(resource);
}
return counter;
}
public int loadBeanDefinitions(String location) throws BeanDefinitionStoreException {
return loadBeanDefinitions(location, null);
}
public int loadBeanDefinitions(String location, Set actualResources) throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");
}
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
int loadCount = loadBeanDefinitions(resources);
if (actualResources != null) {
for (Resource resource : resources) {
actualResources.add(resource);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");
}
return loadCount;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
int loadCount = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");
}
return loadCount;
}
}
AbstractApplicationContext关于资源定位的一系列相关方法:
public Resource[] getResources(String locationPattern) throws IOException {
return this.resourcePatternResolver.getResources(locationPattern);
} public AbstractApplicationContext(ApplicationContext parent) {
this.parent = parent;
this.resourcePatternResolver = getResourcePatternResolver();
this.environment = this.createEnvironment();
} protected ResourcePatternResolver getResourcePatternResolver() {
return new PathMatchingResourcePatternResolver(this);
} public Resource[] getResources(String locationPattern) throws IOException {
Assert.notNull(locationPattern, "Location pattern must not be null");
if (locationPattern.startsWith(CLASSPATH_ALL_URL_PREFIX)) {
// a class path resource (multiple resources for same name possible)
if (getPathMatcher().isPattern(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))) {
// a class path resource pattern
return findPathMatchingResources(locationPattern);
}
else {
// all class path resources with the given name
return findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()));
}
}
else {
// Only look for a pattern after a prefix here
// (to not get fooled by a pattern symbol in a strange prefix).
int prefixEnd = locationPattern.indexOf(":") + 1;
if (getPathMatcher().isPattern(locationPattern.substring(prefixEnd))) {
// a file pattern
return findPathMatchingResources(locationPattern);
}
else {
// a single resource with the given name
return new Resource[] {getResourceLoader().getResource(locationPattern)};
}
}
} protected Resource[] findPathMatchingResources(String locationPattern) throws IOException {
String rootDirPath = determineRootDir(locationPattern);
String subPattern = locationPattern.substring(rootDirPath.length());
Resource[] rootDirResources = getResources(rootDirPath);
Set result = new LinkedHashSet(16);
for (Resource rootDirResource : rootDirResources) {
rootDirResource = resolveRootDirResource(rootDirResource);
if (isJarResource(rootDirResource)) {
result.addAll(doFindPathMatchingJarResources(rootDirResource, subPattern));
}
else if (rootDirResource.getURL().getProtocol().startsWith(ResourceUtils.URL_PROTOCOL_VFS)) {
result.addAll(VfsResourceMatchingDelegate.findMatchingResources(rootDirResource, subPattern, getPathMatcher()));
}
else {
result.addAll(doFindPathMatchingFileResources(rootDirResource, subPattern));
}
}
if (logger.isDebugEnabled()) {
logger.debug("Resolved location pattern [" + locationPattern + "] to resources " + result);
}
return result.toArray(new Resource[result.size()]);
} protected Set doFindMatchingFileSystemResources(File rootDir, String subPattern) throws IOException {
if (logger.isDebugEnabled()) {
logger.debug("Looking for matching resources in directory tree [" + rootDir.getPath() + "]");
}
Set matchingFiles = retrieveMatchingFiles(rootDir, subPattern);
Set result = new LinkedHashSet(matchingFiles.size());
for (File file : matchingFiles) {
result.add(new FileSystemResource(file));
}
return result;
}
忽略掉retrieveMatchingFiles中参数检测逻辑,直接看真正的匹配逻辑
protected void doRetrieveMatchingFiles(String fullPattern, File dir, Set result) throws IOException {
if (logger.isDebugEnabled()) {
logger.debug("Searching directory [" + dir.getAbsolutePath() +
"] for files matching pattern [" + fullPattern + "]");
}
File[] dirContents = dir.listFiles();
if (dirContents == null) {
if (logger.isWarnEnabled()) {
logger.warn("Could not retrieve contents of directory [" + dir.getAbsolutePath() + "]");
}
return;
}
for (File content : dirContents) {
String currPath = StringUtils.replace(content.getAbsolutePath(), File.separator, "/");
if (content.isDirectory() && getPathMatcher().matchStart(fullPattern, currPath + "/")) {
if (!content.canRead()) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping subdirectory [" + dir.getAbsolutePath() +
"] because the application is not allowed to read the directory");
}
}
else {
doRetrieveMatchingFiles(fullPattern, content, result);
}
}
if (getPathMatcher().match(fullPattern, currPath)) {
result.add(content);
}
}
} 如上,我们在工程中设置了容器的配置文件位置或者通过编程式的方式设置,然后容器在启动的时候,把这个字符串表示的配置文件位置解析成了spring内部的Resource。接下来的文章会介绍spring是如何从Resource中读取配置,并且解析成BeanDefinition的。