本篇博客将以WordCount为例从源码上分析hadoop作业提交流程,所使用的hadoop版本为cdh4.3.0。
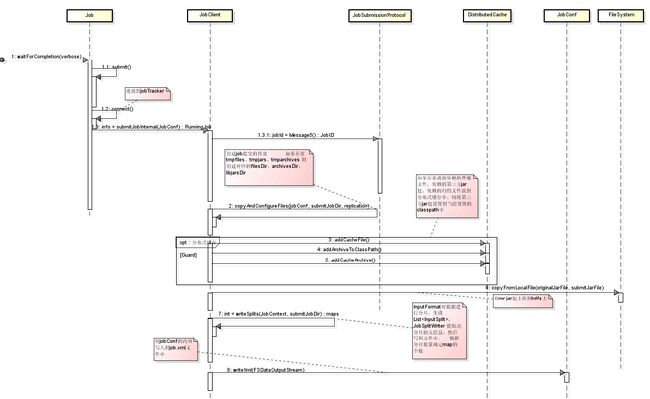
hadoop作业提交流程如下图所示:
public static void distribute() throws Exception {
/*指定Hadoop 环境的用户名称,
如果不指定会抛org.apache.hadoop.security.AccessControlException,访问受限*/
System.setProperty("HADOOP_USER_NAME", "DQ");
Configuration conf = new Configuration();
//指定执行过程中临时文件存放目录
conf.setStrings("hadoop.tmp.dir", "/home/DQ/hsh_test/");
//指定jobTracker
conf.set("mapred.job.tracker", "hadoop01:8021");
//指定作业依赖的jar在本地的路径
conf.set("tmpjars", "/home/david/workspace/haddop-test/thirdlib.jar");
//指定mr jar包在本地的路径
conf.set("mapred.jar", "/home/david/workspace/haddop-test/mr.jar");
conf.setStrings("tmpfiles", "/home/david/workspace/haddop-test/refData/dict.txt");
//指定依赖的归档文件
conf.setStrings("tmparchives", "/home/david/workspace/haddop-test/refData/archives/archives.zip");
//指定分片大小
// long splip_size = 70 * 1024 * 1024;
// conf.setLong("mapred.max.split.size", splip_size);
Job wordCountjob = Job.getInstance(conf, "wordcount");
wordCountjob.setNumReduceTasks(3); //配置reduec任务的数量
wordCountjob.setInputFormatClass(TextInputFormat.class);
wordCountjob.setMapperClass(TokenizerMapper.class);
//指定对中间数据进行合并的类
wordCountjob.setCombinerClass(IntSumReducer.class);
wordCountjob.setReducerClass(IntSumReducer.class);
wordCountjob.setOutputKeyClass(Text.class);
wordCountjob.setOutputValueClass(IntWritable.class);
// 指定输入数据在hdfs上的存放路径
Path input1 = new Path("hdfs://hadoop01:8020/user/DQ/input1.txt");
Path input2 = new Path("hdfs://hadoop01:8020/user/DQ/input2.txt");
FileInputFormat.addInputPath(wordCountjob, input1);
FileInputFormat.addInputPath(wordCountjob, input2);
//作业执行结果在hdfs上的存放路径
Path output = new Path("hdfs://hadoop01:8020/user/DQ/output/"+System.currentTimeMillis());
FileOutputFormat.setOutputPath(wordCountjob, output);
boolean flag = wordCountjob.waitForCompletion(true);
if(flag)
System.exit(1);
System.exit(0);
}
客户端代码中,distribute( )方法创建Configuration 实例conf,并将 jobTracker信息、作业的mr jar包、作业依赖的jar以及依赖的其他文件添加到conf中,然后以conf为参数创建名为wordcount的作业实例wordCountJob,并指定其执行的Mapper和Reducer以及输入输出等信息。wordCountJob调用waitForCompletion(boolean verbose)提交作业,源码如下:
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) { // 如果verbose为true 就打印作业执行信息,否则不打印
jobClient.monitorAndPrintJob(conf, info);
} else {
info.waitForCompletion();
}
return isSuccessful();
}
waitForCompletion( )方法内部判定作业处于新建状态就调用Job的submit( )来提交。submit( )源码如下:
public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
// Connect to the JobTracker and submit the job
connect();
info = jobClient.submitJobInternal(conf);
super.setJobID(info.getID());
state = JobState.RUNNING;
}
submit( )会进一步检查作业的状态是否是DEFINE,如果不是就终止提交。检查通过后调用connect( )与JobTracker建立连接,此过程会创建JobClient实例,重点在于实例的初始化方法init(JobConf conf)。
public void init(JobConf conf) throws IOException {
setConf(conf);
String tracker = conf.get("mapred.job.tracker", "local");
tasklogtimeout = conf.getInt(
TASKLOG_PULL_TIMEOUT_KEY, DEFAULT_TASKLOG_TIMEOUT);
this.ugi = UserGroupInformation.getCurrentUser();
if ("local".equals(tracker)) {
conf.setNumMapTasks(1);
this.jobSubmitClient = new LocalJobRunner(conf);
} else if (!HAUtil.isHAEnabled(conf, tracker)) {
this.jobSubmitClient = createRPCProxy(JobTracker.getAddress(conf), conf);
} else {
this.jobSubmitClient = createRPCProxy(tracker, conf);
}
JobClient的init方法中会根据配置的jobTracker来创建JobSubmissionProtocol实例jobSubmitClient,jobClient就是通过jobSubmitClient来向jobTracker提交作业的。如果用户没有配置mapred.job.tracker,其默认就为“local”,这种情况下会创建LocalJobRunner作为jobTracker,作业将会在本地而非分布式环境中执行。有关作业的本地执行,后续博客会详细介绍,本篇只介绍分布式执行。如果配置mapred.job.tracker为分布式环境中的jobTracker的地址,就创建jobTracker的rpc代理,由该代理来完成与jobTracker的交互。
至此客户端提交代码所需要的实例都已创建完成(重点是jobClient实例和他的成员jobSubmitClient),下个阶段就是数据准备阶段。Job通过对jobClient调用submitJobInternal(conf)方法来真正完成作业的提交。
public RunningJob submitJobInternal(final JobConf job) throws FileNotFoundException,
ClassNotFoundException, InterruptedException, IOException {
return ugi.doAs(new PrivilegedExceptionAction() {
public RunningJob run() throws FileNotFoundException, ClassNotFoundException,InterruptedException,IOException{
JobConf jobCopy = job;
/*jobStagingArea是所有作业提交到JobTracker的文件系统中的根目录*/
Path jobStagingArea = JobSubmissionFiles.getStagingDir(JobClient.this,jobCopy);
JobID jobId = jobSubmitClient.getNewJobId();
/*在JobTracker的文件系统上为当前提交的作业生成根目录(jobStagingArea/jobId/),该目录下存放的文件包括:
*依赖的普通文件 存放目录:jobStagingArea/jobId/files
*依赖的jar包 存放目录:jobStagingArea/jobId/libjars
*依赖的归档文件 存放目录:jobStagingArea/jobId/archives
*MR jar包 存放目录:jobStagingArea/jobId/
*/
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
jobCopy.set("mapreduce.job.dir", submitJobDir.toString());
JobStatus status = null;
try {
populateTokenCache(jobCopy, jobCopy.getCredentials());
copyAndConfigureFiles(jobCopy, submitJobDir); //文件生成、上传
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(jobCopy.getCredentials(),new Path [] {submitJobDir},jobCopy);
/* 作业配置文件job.xml文件在JobTracker的文件系统上的存放路径 */
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
/* 获取配置的reduceTask的数量,默认为1 */
int reduces = jobCopy.getNumReduceTasks();
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
job.setJobSubmitHostAddress(ip.getHostAddress());
job.setJobSubmitHostName(ip.getHostName());
}
JobContext context = new JobContextImpl(jobCopy, jobId);
jobCopy = (JobConf)context.getConfiguration();
// Check the output specification
/* 通过OutputFormat检查作业输出目录是否有效 */
if (reduces == 0 ? jobCopy.getUseNewMapper() :
jobCopy.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat output =
ReflectionUtils.newInstance(context.getOutputFormatClass(),jobCopy);
output.checkOutputSpecs(context);
} else {
jobCopy.getOutputFormat().checkOutputSpecs(fs, jobCopy);
}
// Create the splits for the job
FileSystem fs = submitJobDir.getFileSystem(jobCopy);
LOG.debug("Creating splits at " + fs.makeQualified(submitJobDir));
/* 对输入进行分片,并将分片信息和分片源信息上传到JobTracker的文件系统中的submitJobDir目录下,
* 最后返回分片数作为MapTask的数量
*/
int maps = writeSplits(context, submitJobDir);
jobCopy.setNumMapTasks(maps);
// write "queue admins of the queue to which job is being submitted" to job file.
String queue = jobCopy.getQueueName();
AccessControlList acl = jobSubmitClient.getQueueAdmins(queue);
jobCopy.set(QueueManager.toFullPropertyName(queue,QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
/* 至此所有需要写到job.xml文件中的配置信息都已经写了,
* 此处将最终配置文件上传到JobTracker的文件系统中
*/
FSDataOutputStream out = FileSystem.create(fs, submitJobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(jobCopy);
try {
jobCopy.writeXml(out);
} finally {
out.close();
}
/*
* 至此准备阶段完成,接下来由jobTracker代理通过RPC正式提交作业到集群
*/
printTokens(jobId, jobCopy.getCredentials());
status = jobSubmitClient.submitJob(jobId, submitJobDir.toString(), jobCopy.getCredentials());
if (status != null) {
return new NetworkedJob(status);
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (fs != null && submitJobDir != null)
fs.delete(submitJobDir, true);
}
}
}
});
}
本过程中,JobTracker的代理jobSubmitClient首先向jobTracker申请作业信息提交到jobTracker文件系统上的根目录和jobId,然后将作业依赖的各类文件(jar,普通文件、分档文件、job.xml等)提交到各自在jobTracker文件系统中的目录里面。依赖文件的处理在copyAndConfigureFiles (JobConf job, Path submitJobDir, short replication)中进行,源码如下:
private void copyAndConfigureFiles(JobConf job, Path submitJobDir, short replication) throws IOException, InterruptedException {
if (!(job.getBoolean("mapred.used.genericoptionsparser", false))) {
LOG.warn("Use GenericOptionsParser for parsing the arguments. " +
"Applications should implement Tool for the same.");
}
String files = job.get("tmpfiles");
String libjars = job.get("tmpjars");
String archives = job.get("tmparchives");
//
// Figure out what fs the JobTracker is using. Copy the
// job to it, under a temporary name. This allows DFS to work,
// and under the local fs also provides UNIX-like object loading
// semantics. (that is, if the job file is deleted right after
// submission, we can still run the submission to completion)
//
// Create a number of filenames in the JobTracker's fs namespace
FileSystem fs = submitJobDir.getFileSystem(job);
LOG.debug("default FileSystem: " + fs.getUri());
if (fs.exists(submitJobDir)) {
throw new IOException("Not submitting job. Job directory " + submitJobDir
+" already exists!! This is unexpected.Please check what's there in" +
" that directory");
}
submitJobDir = fs.makeQualified(submitJobDir);
FsPermission mapredSysPerms = new FsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION);
FileSystem.mkdirs(fs, submitJobDir, mapredSysPerms);
Path filesDir = JobSubmissionFiles.getJobDistCacheFiles(submitJobDir);
Path archivesDir = JobSubmissionFiles.getJobDistCacheArchives(submitJobDir);
Path libjarsDir = JobSubmissionFiles.getJobDistCacheLibjars(submitJobDir);
// add all the command line files/ jars and archive
// first copy them to jobtrackers filesystem
//在jobTracker的文件系统中为tmpfiles创建目录,从本地将文件上传到该目录,并将其放到分布式缓存中。
if (files != null) {
FileSystem.mkdirs(fs, filesDir, mapredSysPerms);
String[] fileArr = files.split(",");
for (String tmpFile: fileArr) {
URI tmpURI;
try {
tmpURI = new URI(tmpFile);
} catch (URISyntaxException e) {
throw new IllegalArgumentException(e);
}
Path tmp = new Path(tmpURI);
Path newPath = copyRemoteFiles(fs,filesDir, tmp, job, replication);
try {
URI pathURI = getPathURI(newPath, tmpURI.getFragment());
DistributedCache.addCacheFile(pathURI, job);
} catch(URISyntaxException ue) {
//should not throw a uri exception
throw new IOException("Failed to create uri for " + tmpFile, ue);
}
DistributedCache.createSymlink(job);
}
}
//在jobTracker的文件系统中为作业依赖的jar包创建目录,从本地将jar上传到该目录,并将其放到分布式缓存中。
if (libjars != null) {
FileSystem.mkdirs(fs, libjarsDir, mapredSysPerms);
String[] libjarsArr = libjars.split(",");
for (String tmpjars: libjarsArr) {
Path tmp = new Path(tmpjars);
Path newPath = copyRemoteFiles(fs, libjarsDir, tmp, job, replication);
DistributedCache.addFileToClassPath(
new Path(newPath.toUri().getPath()), job, fs);
}
}
//在jobTracker的文件系统中为作业依赖的归档文件创建目录,从本地将归档文件上传到该目录,并将其放到分布式缓存中。
if (archives != null) {
FileSystem.mkdirs(fs, archivesDir, mapredSysPerms);
String[] archivesArr = archives.split(",");
for (String tmpArchives: archivesArr) {
URI tmpURI;
try {
tmpURI = new URI(tmpArchives);
} catch (URISyntaxException e) {
throw new IllegalArgumentException(e);
}
Path tmp = new Path(tmpURI);
Path newPath = copyRemoteFiles(fs, archivesDir, tmp, job, replication);
try {
URI pathURI = getPathURI(newPath, tmpURI.getFragment());
DistributedCache.addCacheArchive(pathURI, job);
} catch(URISyntaxException ue) {
//should not throw an uri excpetion
throw new IOException("Failed to create uri for " + tmpArchives, ue);
}
DistributedCache.createSymlink(job);
}
}
TrackerDistributedCacheManager.validate(job);
TrackerDistributedCacheManager.determineTimestampsAndCacheVisibilities(job);
TrackerDistributedCacheManager.getDelegationTokens(job, job.getCredentials());
//将作业的mr jar包上传到jobTracker的文件系统中
String originalJarPath = job.getJar();
if (originalJarPath != null) {
if ("".equals(job.getJobName())){
job.setJobName(new Path(originalJarPath).getName());
}
Path originalJarFile = new Path(originalJarPath);
URI jobJarURI = originalJarFile.toUri();
// If the job jar is already in fs, we don't need to copy it from local fs
if (jobJarURI.getScheme() == null || jobJarURI.getAuthority() == null
|| !(jobJarURI.getScheme().equals(fs.getUri().getScheme())
&& jobJarURI.getAuthority().equals(
fs.getUri().getAuthority()))) {
Path submitJarFile = JobSubmissionFiles.getJobJar(submitJobDir);
job.setJar(submitJarFile.toString());
fs.copyFromLocalFile(originalJarFile, submitJarFile);
fs.setReplication(submitJarFile, replication);
fs.setPermission(submitJarFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
}
} else {
LOG.warn("No job jar file set. User classes may not be found. "+
"See JobConf(Class) or JobConf#setJar(String).");
}
}
该方法执行完之后,jobTracker文件系统中将添加如下文件:

submitJobInternal( )方法在处理完以上文件之后会创建OutputFormat实例来验证输出路径是否合法,验证通过之后就开始处理输入数据分片。
首先jobClient调用其方法writeNewSplits(JobContext job, Path jobSubmitDir) ,该方法通过反射创建InputFormat实例(这里使用的是FileInputFormat),然后用该实例创建分片,对分片排序之后会将分片信息写入文件上传到jobTracker的文件系统中,源码如下:
privateint writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = job.getConfiguration(); //通过反射创建InputFormat实例 InputFormat input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf); //InputFormat实例创建分片 List splits = input.getSplits(job); T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]); //对分片按照大小降序排序,这样可以保证数据量大的分片现行被处理 Arrays.sort(array, new SplitComparator()); //将分片信息写入文件中 JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array); //返回split数量作为mapTask的数量 return array.length; }
InputFormat实例创建好分片信息后,由JobSplitWriter负责写分片信息到文件中,源码如下:
public staticvoid createSplitFiles(Path jobSubmitDir, Configuration conf, FileSystem fs, T[] splits) throws IOException, InterruptedException { //写分片源数据信息到文件job.spilt中并创建分片元数据信息 FSDataOutputStream out = createFile(fs, JobSubmissionFiles.getJobSplitFile(jobSubmitDir), conf); SplitMetaInfo[] info = writeNewSplits(conf, splits, out); out.close(); //写分片元数据信息到文件job.splitmetainfo中 writeJobSplitMetaInfo(fs,JobSubmissionFiles.getJobSplitMetaFile(jobSubmitDir), new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION), splitVersion, info); }
分片信息文件(job.split 和 job.splitmetainfo)会被上传到JobTracker的文件系统中,目录结构如下:

job.split文件记录了每个分片的源数据信息:分片的数据结构(本例中就是FileSplit)和输入文件在hdfs上的逻辑位置。job.splitmetainfo文件记录了每个分片的元数据。两个文件的内容如下:
![]()
最后作业需要的所有配置信息都已经配置到JobConf(jobCopy)中了,该配置对象包含的所有信息会被写到jobTracker文件系统中的job.xml文件中。
到此所有数据准备完毕,jobSubmitClient调用submitJob( )方法将作业提交给jobTracker,作业提交完成,接下来作业的调度就交由jobTracker完成。