Delta Lake - 走进 Databricks
今天笔者带大家走进 Databricks,基于 Databricks Cloud 社区版本进行实验,并在 Databricks Notebook 中对 Delta Lake 商业版本进行实战操作。
Databricks 版图
关于 Databricks 的故事,使用过 Apache Spark 的读者应该都比较了解,这里略作补充。
Databricks 是 Apache Spark 的商业化公司,致力于提供基于 Spark 的云服务,用于数据集成和数据管道等服务。
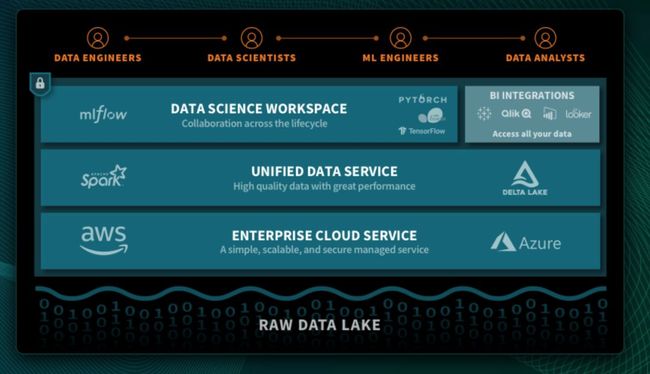
我们通过上面的一张图便可初步知其貌:
Databricks 提供统一的数据分析平台,一个用于大规模数据工程和协作的数据科学的云平台。
从上图可知,Databricks 统一的数据分析平台由三部分组成:
数据科学工作台平台
协作的 Notebooks
机器学习 Runtime
托管的 MLflow
统一的数据服务
Delta Lake
Databricks Runtime
企业云服务
企业安全,使用统一的数据安全方法保护用户的大数据和 ML 工作流。
Databricks 涉及技术包括 Apache Spark、Delta Lake、Tensorflow、MLflow 和 R。
关于 Databricks 感兴趣的读者可以访问 databricks 官网进一步学习。
Try Databricks
Databricks 云平台提供了企业版本和社区版本。
对于企业版本,提供了 14 天的全部特性的试用功能,但是不包含云费用(比如 AWS、Azure),其实这块费用很低。
Databricks 社区版本提供的功能有:
存储限制为 6GB 的单个集群,没有 worker 节点
没有协作功能,提供基本的 notebook
限制最多 3 个用户使用
公共环境分享用户的工作
笔者在本篇文章中主要会以 Databricks 社区版本给大家讲解 Delta Lake 商业版本的使用,读者可以参考之前学过的 Delta Lake 开源版本。
1. 创建运行环境
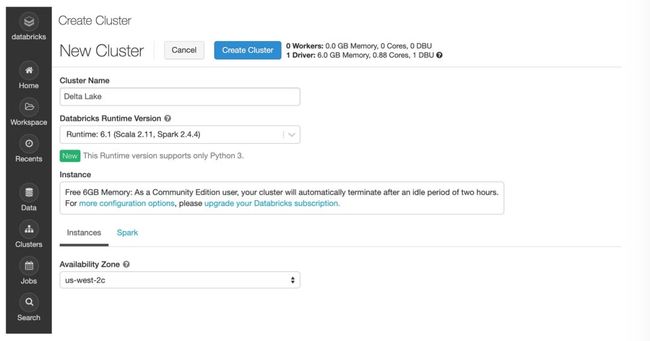
笔者创建一个 Databricks Runtime 版本为:Runtime: 6.1 其中 Scala 版本为 2.11,Spark 版本为 2.4.4。

2. 创建 Notebook
创建的 Notebook 可以在集群中找到,如下:
3. Databricks 数据集
笔者本来准备了一些数据集,但是 Databricks 在 DBFS 分布式存储系统(可以当作 HDFS)上存储了各种数据集,可以使用这些数据集来学习 Apache Spark 或测试算法。
Databricks 文件系统(DBFS)是安装在 Databricks 工作区中的分布式文件系统,可在Databricks 集群上使用。DBFS 具有以下优点:
允许载存储对象,以便无需凭据即可无缝访问数据。
允许使用目录和文件而不是存储 URL 与对象存储进行交互。
将文件保留到对象存储中,因此在终止集群后不会丢失数据。
查看 Databricks 提供的数据集:
%python
display(dbutils.fs.ls("/databricks-datasets"))
使用 Python 访问 README 数据:
%python
with open("/dbfs/databricks-datasets/README.md") as f:
x = ''.join(f.readlines())
print(x)
4. 创建表
使用 CSV 格式的数据文件来创建 Spark 表:
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING CSV OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header "true")
5. 查询表
查询上面在 Spark 中创建的 diamonds 表:
SELECT color, avg(price) AS price FROM diamonds GROUP BY color ORDER BY COLOR
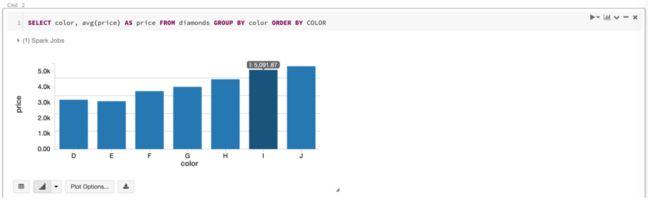
到此,笔者简单介绍了在 Databricks 中使用 Spark,然后回到我们的主题 Delta Lake。
Databricks Delta Lake
接下来笔者讲解在 Databricks 服务中使用 Delta Lake,主要以 Spark SQL 方式,Scala 和 Python 编程语言之前文章中涉及很多。
1. 创建 Delta 表
DROP TABLE IF EXISTS events;
CREATE TABLE events
USING delta
PARTITIONED BY (date)
SELECT action, from_unixtime(time, 'yyyy-MM-dd') as date
FROM json.`/databricks-datasets/structured-streaming/events/`;
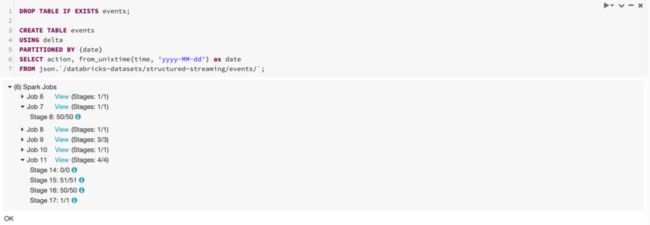
可以点击上图 Spark Jobs 中的 View,查看 Spark Jobs 执行的日志:
2. 查看 Delta 表数据
2.1 查询表明细:
SELECT * FROM events
输出结果:
2.2 总数:
SELECT count(*) FROM events
输出结果:

2.3 汇总并可视化现实结果:
SELECT date, action, count(action) AS action_count FROM events GROUP BY action, date ORDER BY date, action
输出结果:
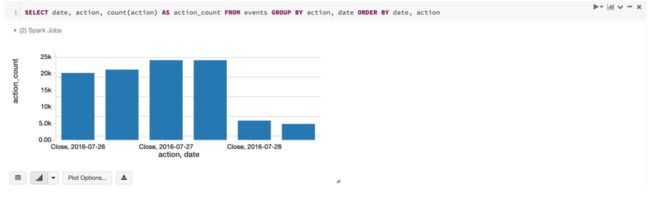
Databricks Notebook 中提供了十几种常用的可视化数据展示图表。
3. 生成历史数据
为了生成历史数据,可以将原始数据的日期后移2天,即:
INSERT INTO events
SELECT action, from_unixtime(time-172800, 'yyyy-MM-dd') as date
FROM json.`/databricks-datasets/structured-streaming/events/`;
3.1 查询总数
SELECT count(*) FROM events
输出结果:

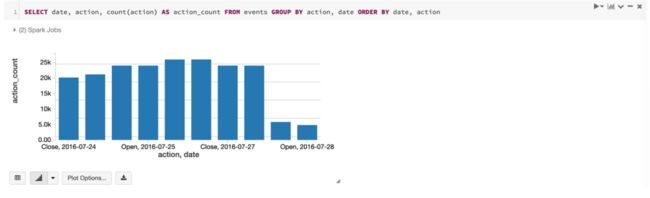
3.2 汇总并可视化展示
SELECT date, action, count(action) AS action_count FROM events GROUP BY action, date ORDER BY date, action
输出结果:
4. 查看指定分区的信息
DESCRIBE EXTENDED events PARTITION (date='2016-07-25')
输出结果:
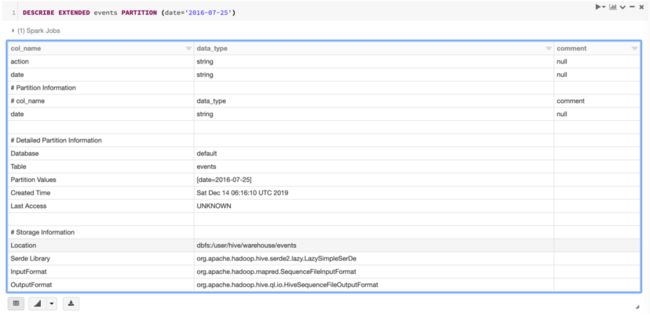
根据 # Storage Information 展示的内容,events 其实就是存储在 default 数据库下面的表。
5. 优化表
OPTIMIZE events
输出表的统计信息:

6. 查看表的操作历史
笔者在前面的文章中介绍过,对于 Delta 表的操作,都是有历史版本记录,便于查询指定版本的历史数据。
查看表历史记录:
DESCRIBE HISTORY events
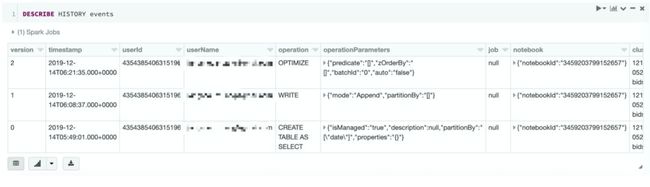
可以看出笔者共执行三次操作:
使用 create table as select 方式创建 Delta 表并插入数据
执行 insert 插入数据
执行 optimize 优化表
7. 查看表详细信息
DESCRIBE DETAIL events

8. 查看表格式
DESCRIBE FORMATTED events
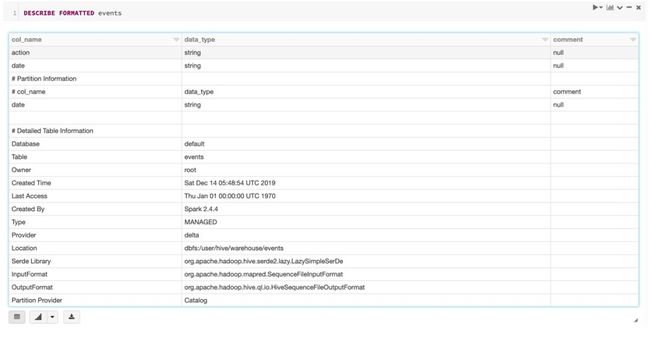
Vacuum
VACUUM [db_name.]table_name|path [RETAIN num HOURS] [DRY RUN]
通过在 Delta 表上运行 vacuum 命令,递归与表关联的目录,并删除不再处于该表的事务日志的最新状态且早于保留阈值的文件。默认保留阈值为7天。Delta 表上的 VACUUM 操作不会自动触发。
如果在 Delta 表上运行VACUUM,则可能无法恢复到默认的7天数据保留期之前的版本。
为了删除当前快照之外的所有文件,需要在执行 Vaccum 时指定一个很小的值,因为 Delta Lake 默认的保留时长是7天。比如:
VACUUM events RETAIN 0 HOURS
但是提交执行后,发现报错,信息如下:
Error in SQL statement: IllegalArgumentException: requirement failed: Are you sure you would like to vacuum files with such a low retention period? If you have
writers that are currently writing to this table, there is a risk that you may corrupt the
state of your Delta table.
If you are certain that there are no operations being performed on this table, such as
insert/upsert/delete/optimize, then you may turn off this check by setting:
spark.databricks.delta.retentionDurationCheck.enabled = false
If you are not sure, please use a value not less than "168 hours".
设置之前创建的集群环境,配置 Spark 参数:spark.databricks.delta.retentionDurationCheck.enabled = false
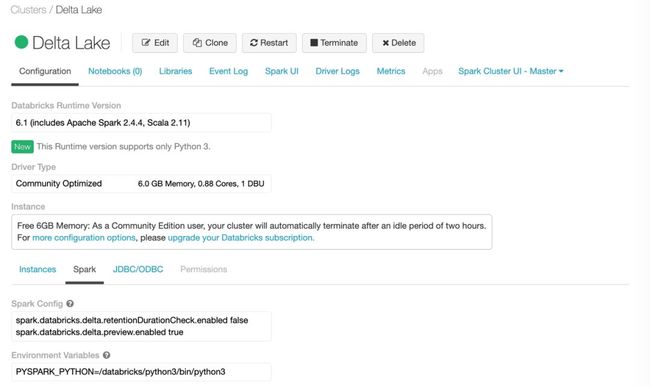
然后重启集群后,再次执行即可。
Delta Lake 0.5.0
值得高兴的是,昨天发布了 Delta Lake 0.5.0 版本,该版本引入了对 Presto/Athena 的支持并提高了并发性。该版本的主要功能包括:
支持使用 manifest 文件的其他处理引擎 现在可以使用 manifest 文件从 Presto 和 Amazon Athena 查询 Delta 表,使用 Scala、Java、Python 和 SQL API 生成 manifest 文件。
改进了所有 Delta Lake 操作的并发性
改进了对文件压缩的支持
改进了 insert-only merge 的性能
Convert-to-Delta 的 SQL 支持 现在可以使用 SQL 将 Parquet 表转换为 Delta,0.4.0 版本中已支持 Scala、Java 和 Python。
-- Convert unpartitioned parquet table at path 'path/to/table'
CONVERT TO DELTA parquet.`path/to/table`
-- Convert partitioned parquet table at path 'path/to/table' and partitioned by integer column named 'part'
CONVERT TO DELTA parquet.`path/to/table` PARTITIONED BY (part int)
对 Snowflake 和 Redshift Spectrum 的实验支持 可以从 Snowflake 和 Redshift Spectrum 中查询 Delta 表。
总结
Databricks Delta Lake 商业版本的功能相对开源版本来说,还是比较全面的,比如对 Spark SQL 的支持以及一些工具使用。Delta Lake 开源社区也在快速迭代更新和引入新的功能,0.5.0 版本的发布更是提升了操作并发性和压缩性能。