hive中NULL值问题
问题描述
源端数据oracle数据库,通过cdm迁移工具将数据迁移到目标端hive。在oracle中的NULL值迁移到hive中后有的字段表现为NULL,有的字段表现为空串“”(即两个引号中间为空)。观察发现字符型的数据字段为空串,非字符型的字段为NULL。
整个链路涉及到了oracle、cdm、hive,分析问题的原因就从这三个产品着手。首先我们知道oracle中没有空串,当插入空串时写入的是NULL。很明显hive与oracle不同,hive中可以写入空串也可以写入NULL,空串和NULL在hive中是两个不同的概念。
你可能不了解cdm,它是华为云的云数据迁移(Cloud Data Migration,简称CDM)工具。
hive中什么数据会为NULL
hive中表的存储格式为file类型(如textfile、rcfile),它们在HDFS中会把NULL值存储为‘\N’
| CREATE TABLE `test_rcfile`( `id` int, `name` string) STORED AS rcfile;
insert into test_rcfile select 1,'abc' union all select '','abc' union all select 3,'' union all select '\\N','\\N' union all select '\N','\N' union all select 'NULL','NULL' union all select 7,NULL; |
| select * from test_rcfile; |
| select * from test_rcfile where id is NULL;
|
| select * from test_rcfile where name is NULL;
|
| 看一下在HDFS中存储的数据(这是按列存储的)
|
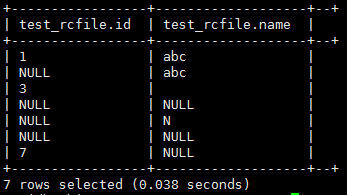
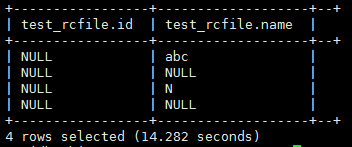


解释一下上面执行结果:
在insert操作的时候hive会对字段类型进行模式匹配,不符合类型的数据会插入NULL值。对于int类型的id字段,当插入的是字符串或者空串的时候它都不符合int类型,所以插入的就是NULL,在HDFS中存储的就是‘\N’。
当插入的是字符类型的字段时,空串被当做一个字符对待,所以hive中完全可以存储空串,空串并不会作为NULL值处理,空串在HDFS中就是存储的空串“”。
| CREATE TABLE `test_textfile`( `id` int, `name` string) STORED AS textfile;
insert into test_textfile select 1,'abc' union all select '','abc' union all select 3,'' union all select '\\N','\\N' union all select '\N','\N' union all select 'NULL','NULL' union all select 7,NULL; |
| select * from test_rcfile; select * from test_rcfile where id is NULL; select * from test_rcfile where name is NULL 查询结果和rcfile一样。 |
| 看一下HDFS中存储的数据
|
| 如果是load导入数据会怎样,先看一下文本数据
将数据上传HDFS:hdfs dfs -put test /tmp/.testHDFS/t 在hive中执行load导入数据到表:load data inpath '/tmp/.testHDFS/t' overwrite into table test_rcfile; 看下HDFS中存的数据
查询数据:select * from test_textfile where id is null;
|

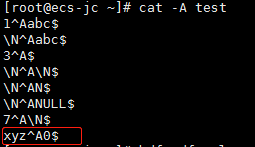

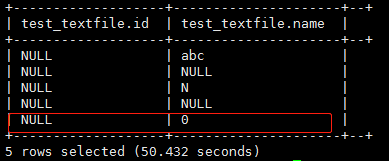
解释一下为什么存储和查询不一样:
load导入数据是不会检查数据的类型是否匹配的,它只是简单的转移数据操作,所以速度很快。它会在select的时候检查数据类型模式。所以虽然HDFS中id字段存储的是“xyz”,查询出来却是NULL,而且where条件可以筛选出来。
而对于字符型的数据类型,它可以涵盖其他类型的数据,就像是隐式转换这种概念一样,其他类型可以转换成字符型的。
| CREATE TABLE `test_orc`( `id` int, `name` string) STORED AS orc;
insert into test_orc select 1,'abc' union all select '','abc' union all select 3,'' union all select '\\N','\\N' union all select '\N','\N' union all select 'NULL','NULL' union all select 7,NULL; |
| select * from test_orc;
|
| select * from test_orc where id is null;
|
| select * from test_orc where name is null;
|


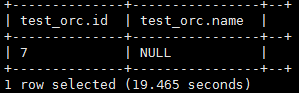
orc格式和file类型对NULL是不同的。file类型会把NULL在HDFS中写成“\N”,orc格式并非如此,orc格式中“\N”就是普通的字符串。
总结一下:
1、file格式中NULL在HDFS中以“\N”形式存储。orc格式中并不是这样。
2、load方式导入数据时不会检查数据类型,数据以原有形式存储。它会在查询的时候检查字段类型是否匹配,不匹配的为NULL。
3、insert方式插入数据时就会检查数据字段类型是否匹配,会将不匹配的数据以NULL值存储。
如何让hive中的空串变成NULL
| ALTER TABLE test_rcfile SET SERDEPROPERTIES('serialization.null.format' = ''); |
| select * from test_rcfile;
|
| select * from test_rcfile where name is null;
|
| select * from test_rcfile where name='';
|



修改表的配置,使得原来NULL以“\N”存储变成了以空串存储。此时在HDFS中存储的“\N”会被以字符串的形式打印,空串也会被解析成NULL。如果新insert的数据为空串或者NULL,在HDFS中将以空(字段分隔符中间什么也没有)存储。
textfile格式同rcfile情况一样。orc格式却不同,即使修改'serialization.null.format' = ''也没有变化,它并不是以空串存储也不是以“\N”存储。
需要注意的是这个参数只能在表级修改,在database级、hive产品级别并没有相似的参数。所以如果通过修改参数达到所有空串解析为NULL的效果,就得对需要的所有表进行修改。
总结一下:
1、通过修改参数我们把file格式的空串解析成NULL,orc格式不会改变。
2、修改参数后用空串作为查询条件查询结果为空。因为空串被解析成NULL了。
3、这个参数只能表级修改。
通过修改hive端的参数解决空串问题并不是那么理想:它要单张表修改参数,维护成本高;只能改变file格式的问题,orc格式问题仍旧存在。
那可不可以在cdm写入hive端的时候进行操作呢。
cdm可以插入NULL值吗
在sqoop中可以采用两个参数设置:
--null-string '\\N' (把所有string类型的空值转成hive的null值'\N')
--null-non-string '\\N' (把非string类型的空值转换成hive的null值'\N')
通过上面这两个参数会把字符类型和非字符类型的空串转换成‘\N’写入到hive表中,然后所查询的数据就没有空串了,源端是NULL值的在hive的数据也是NULL。
sqoop可以通过参数设置,那么cdm可以吗?非常遗憾cdm并没有此类参数,虽然cdm底层是sqoop。并不是cdm做不到,而是因为cdm出于产品安全的考虑,它为了避免参数注入问题就不提供参数设置功能。
cdm针对hive不同格式会有怎样的迁移过程呢。测试情况如下。
| 源端数据库为oracle数据库。源端数据为:
|
| 目标端表分别为上面用到过的test_textfile、test_rcfile、test_orc; 分别创建相应的cdm迁移作业。 |
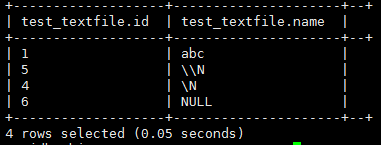
| select * from test_textfile;
目标端少了2条数据:存在NULL值的数据没有迁移。 cdm日志中记录:java.lang.NullPointerException: NULL |
| select * from test_rcfile;
|
| select * from test_orc; 结果同查询test_rcfile相似,数据相同,只是顺序不同。 |

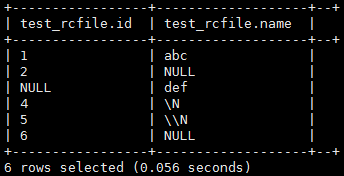
看上去rcfile和orc格式的表通过cdm迁移可以保持NULL不变空串。至于textfile格式中的空指针问题是cdm的bug,可以打补丁处理,不必过多关注textfile类型。
非分区表情况下rcfile和orc格式可以解决NULL值问题,那么hive分区表又有怎样的情况呢?我们测试下hive中分区表是否一样可行。
| CREATE TABLE `test_textfile_par`(`id` int,`name` string) partitioned by (rfq char(8)) STORED AS textfile;
CREATE TABLE `test_rcfile_par`(`id` int,`name` string) partitioned by (rfq char(8)) STORED AS rcfile
CREATE TABLE `test_orc_par`(`id` int,`name` string) partitioned by (rfq char(8)) STORED AS orc; |
| 创建cdm作业 |
| select * from test_textfile_par;
|
| select * from test_rcfile_par; 查询结果和textfile查询结果相同。 |
| select * from test_orc_par;
|


这种情况和直接用insert插入时的效果差不多。cdm在迁移到hive分区表时并没有解决NULL值问题。
解释一下:
cdm在处理hive的分区表和非分区表的时候是不同的。非分区表采用的是MapReduce中的map操作,分区表时采用的是map+reduce操作。
非分区表在map阶段可以直接调用HDFS的write接口将数据写入相应地址中。
hive分区表中分区会存储在相应文件目录中,hive会构建分区级别的目录。分区表需要根据分区字段的值合并(分区字段值相同的记录在物理上存放在相同的目录中),所以需要有reduce阶段。同时有map和reduce操作,中间数据就会有落地的操作,它为了防止出现空指针问题把NULL转成了空串处理。
问题解决了吗
总结一下:
问题涉及到的三个产品:oracle、cdm、hive。这个问题根本原因是因为oracle中无法存储空串,将空串视为NULL。而hive中可以存储空串,将空串视为一个字符。
oracle端我们无法更改,源端无法做处理。
目标端hive可以通过修改参数把NULL以空串存储,但这只适用于file格式,对orc格式不适用。另外修改参数是表级的,需要涉及的所有表进行修改,维护成本剧增。
cdm迁移过程中针对不同的hive格式和是否分区会有不同的迁移实现。目前非分区表的rcfile和orc格式可以成功写入NULL值。但是hive为分区表时写入的是空串。
解决方案
方案1:
所有表创建为rcfile格式的分区表,并设置NULL以空串形式存储。这样cdm迁移时会把NULL值全部转换为空串存储,而hive会把空串解析为NULL。
这种方案需要为每张表做参数修改。维护成本较高。
方案2:
在hive中字符类型的数据才会存在空串问题,非字符类型数据空串会被解析成NULL。可以在hiveSQL加工处理的时候进行数据清洗,将所有的空串转换为NULL。
这种方案会为每次加工时做处理,加入了一层数据清洗的工作。
建议:
这是oracle和hive的产品特性不同造成的问题,而且cdm在中间没有协调好。建议采用方案2。这可以看成一个脏数据问题,通过数据清洗就可以很好的解决问题。而方案1维护成本太高,非常容易出现开发不规范问题,即使出现问题也不易察觉。