Spark——Java和Scala混编Maven开发:WordCount
文章目录
- 1 运行环境
- 2 Maven
- 2.1 Windows下Maven配置
- 2.2 IDEA创建Maven 项目
- 3 实现代码
- 3.1 Scala具体实现
- 3.2 scala简化实现
- 3.3 Java实现
1 运行环境
- 操作系统:
WIN10 64位 - JDK版本:
1.8.0_161 - Scala版本:
2.11.2 - Meven版本:
3.2.5 - 开发工具:
IntellJ IDEA2018.3.3
2 Maven
2.1 Windows下Maven配置
- 下载安装包并解压,修改
conf/settings.xml中配置项Maven本地仓库localRepository

- 配置环境变量

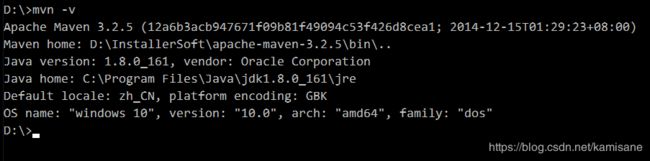
mvn -v查看版本,检查环境变量是否配置成功
2.2 IDEA创建Maven 项目
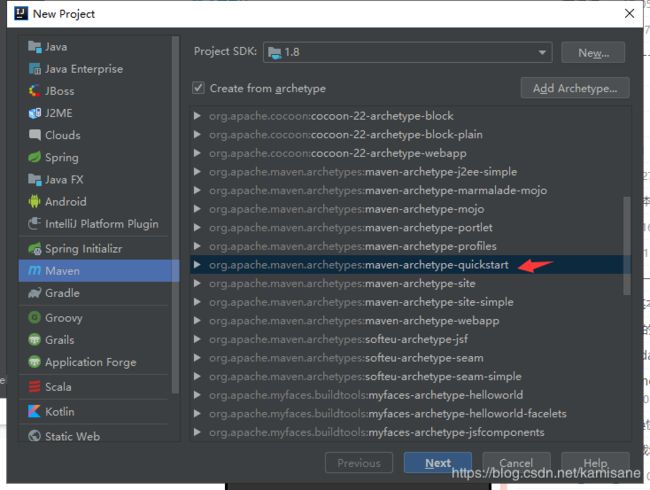
- 创建选择 maven-archetype-quickstart
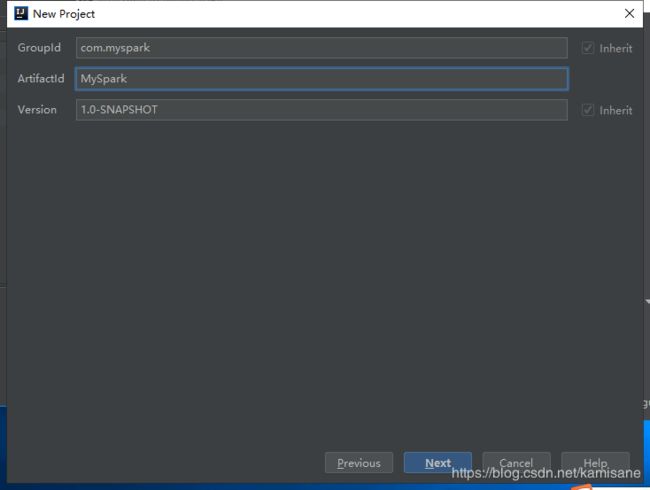
- 配置名称,点击next
- 配置Maven及本地Maven仓库地址

- 配置项目名称和位置,创建即可
- 更新替换Maven
pom.xml文件
注意groupId,artifactId,version不要更新替换
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.mysparktestgroupId>
<artifactId>MySparkTestartifactId>
<version>1.0-SNAPSHOTversion>
<name>MySparkTestname>
<url>http://www.example.comurl>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.3.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.3.1version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>2.11.7version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-compilerartifactId>
<version>2.11.7version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-reflectartifactId>
<version>2.11.7version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
dependency>
<dependency>
<groupId>com.google.collectionsgroupId>
<artifactId>google-collectionsartifactId>
<version>1.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<version>2.4version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>com.bjsxt.scalaspark.core.examples.ExecuteLinuxShellmainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>assemblygoal>
goals>
execution>
executions>
plugin>
plugins>
build>
project>
-
启用自动导入等待jar包下载完成(或者手动将所有jar包放入maven本地仓库)

-
在main目录下创建java和scala并指定为源目录


3 实现代码
3.1 Scala具体实现
package com.myjavacode;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class SparkWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
// 运行模式设置为本地运行
conf.setMaster("local").setAppName("SparkWordCount");
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文件
JavaRDD<String> lines = sc.textFile("./data/words");
// 切分,flatMap--进一条数据出多条数据
// new FlatMapFunction()
// 第一个值String对应读进来的一行一行数据line,第二个值对应读出的一个一个的单词
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
// 在java中,如果想要某个RDD转换成K,V格式,使用xxxToPair
// K,V格式的RDD是:JavaPairRDD,而不是JavaPairRDD>
// new PairFunction()
// 第一个值String对应读进来的单词word,第二,三个值分别对应读出的key和value(Tuple2里的k,v)
JavaPairRDD<String, Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
});
// reduceByKey先将相同的key分组,再对每一组的key对应的value按照逻辑进行处理
// new Function2()
// 第一个值对应v1,第二个值代表v2,第三个值代表返回的Integer
JavaPairRDD<String, Integer> reduce = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 翻转
JavaPairRDD<Integer, String> swap = reduce.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple2) throws Exception {
// return new Tuple2<>(tuple2._2, tuple2._1);
return tuple2.swap();
}
});
// 排序
JavaPairRDD<Integer, String> sort = swap.sortByKey(false);
// 重新翻转,得到最后结果
JavaPairRDD<String, Integer> result = sort.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple2) throws Exception {
return tuple2.swap();
}
});
// 遍历输出
result.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple2) throws Exception {
System.out.println(tuple2);
}
});
// 释放spark对象
sc.stop();
}
}
3.2 scala简化实现
package com.myscalacode
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("sparkwordcount2")
val sc = new SparkContext(conf)
sc.textFile("./data/words").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).sortBy(_._2, false).foreach(println)
sc.stop()
}
}
3.3 Java实现
package com.myjavacode;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class SparkWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
// 运行模式设置为本地运行
conf.setMaster("local").setAppName("SparkWordCount");
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文件
JavaRDD<String> lines = sc.textFile("./data/words");
// 切分,flatMap--进一条数据出多条数据
// new FlatMapFunction()
// 第一个值String对应读进来的一行一行数据line,第二个值对应读出的一个一个的单词
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
// 在java中,如果想要某个RDD转换成K,V格式,使用xxxToPair
// K,V格式的RDD是:JavaPairRDD,而不是JavaPairRDD>
// new PairFunction()
// 第一个值String对应读进来的单词word,第二,三个值分别对应读出的key和value(Tuple2里的k,v)
JavaPairRDD<String, Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
});
// reduceByKey先将相同的key分组,再对每一组的key对应的value按照逻辑进行处理
// new Function2()
// 第一个值对应v1,第二个值代表v2,第三个值代表返回的Integer
JavaPairRDD<String, Integer> reduce = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 翻转
JavaPairRDD<Integer, String> swap = reduce.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple2) throws Exception {
// return new Tuple2<>(tuple2._2, tuple2._1);
return tuple2.swap();
}
});
// 排序
JavaPairRDD<Integer, String> sort = swap.sortByKey(false);
// 重新翻转,得到最后结果
JavaPairRDD<String, Integer> result = sort.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple2) throws Exception {
return tuple2.swap();
}
});
// 遍历输出
result.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple2) throws Exception {
System.out.println(tuple2);
}
});
// 释放spark对象
sc.stop();
// idea可以按住Alt+Enter根据提将代码改成lambda表达式
}
}