人工智能 5.搜索树求解
简单搜索:AI作为内核(算法、算力、大数据)。包括输入、输出、训练、搜索好坏评价。
自然语言处理是搜索引擎最核心的基础技术。
包括了输入和输出,每一次的搜索行为都可以看做是对搜索引擎的一次训练,用户的点击来告诉搜索结果的好坏,从而展示出相对应的搜索排名。在这个过程中,搜索引擎不仅提高了推荐的准确性,还越来越懂得判断所收录结果的好与坏,渐渐学会了像人类一样去分辨网页。
在求解一个问题时,涉及到两个方面:
问题的表示。
相对合适的求解方法。(搜索法、归纳法、归结法、推理法和产生式等)。
5.1 搜索的概念
5.2 状态空间的搜索策略
5.3 盲目的图搜索策略(Uninformed Search)
5.4 启发式图搜索策略( Informed Search )
补:其他搜索策略(局部搜索法、爬山搜索法、局部剪枝搜索、模拟退火法等)
搜索中需要解决的基本问题:
(1)是否一定能找到一个解。——完备性
(2)找到的解是否是最佳解。——最优性
(3)时间与空间复杂性如何。
(4)是否终止运行或是否会陷入一个死循环。
搜索的主要过程(三要素):
(1)状态空间 (state space)
从初始或目的状态出发,并将它作为当前状态。(双向?)
(2) 后继函数(successor function with actions and costs)
扫描操作算子集,将适用当前状态的一些操作算子作用于当前状态而得到新的状态,并建立指向其父结点的指针 。
(3) 初始状态和目标测试(start state and goal test)
解 是一个行动序列,将初始状态转换成目标状态
搜索问题是对原问题的建模!
扩展出潜在的行动 (tree nodes)
维护所考虑行动的边缘(fringe)节点
试图扩展尽可能少的树节点
搜索策略:
1. 搜索方向:
(1) 数据驱动:从初始状态出发的正向搜索。用给定数据中约束知识指导搜索
(2) 目的驱动:从目的状态出发的逆向搜索。哪些操作算子能产生该目的,产生目的时需要哪些条件
(3)双向搜索:直到两条路径在中间的某处汇合为止。
2. 盲目搜索与启发式搜索:
(1)盲目搜索:在不具有对特定问题的任何有关信息的条件下,按固定的步骤(依次或随机调用操作算子)进行的搜索。
(2)启发式搜索:考虑可应用的知识,动态地确定调用操作算子的步骤,优先选择较适合的操作算子,尽量减少不必要的搜索,以求尽快地到达结束状态。
状态空间的搜索策略
状态空间表示法
状态空间的图描述
状态:表示系统状态、事实等叙述型知识的一组变量或数组.(环境细节)![]()
操作:表示引起状态变化的过程型知识的关系或函数:![]()
Problem: Pathing
States: (x,y) location
Actions: NSEW
Successor: update location
Goal test: is (x,y)=END
Problem: Eat-All-Dots
States: {(x,y), dot booleans}
Actions: NSEW
Successor: update location and dot boolean
Goal test: dots all false
状态空间:利用状态变量和操作符号,表示系统或问题的有关知识的符号体系,状态空间四元组: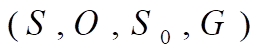
S :状态集合。
O :操作算子的集合。
S0 :包含问题的初始状态是 S的非空子集。
G:若干具体状态或满足某些性质的路径信息描述。
求解路径:从S0结点到G结点的路径。
状态空间的一个解:一个有限的操作算子序列。
八数码问题的状态空间。

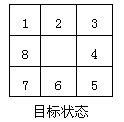
状态集S:所有摆法9!
操作算子:4
将空格向上移Up
将空格向左移Left
将空格向下移Down
将空格向右移Right
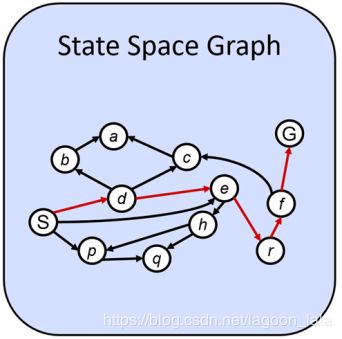
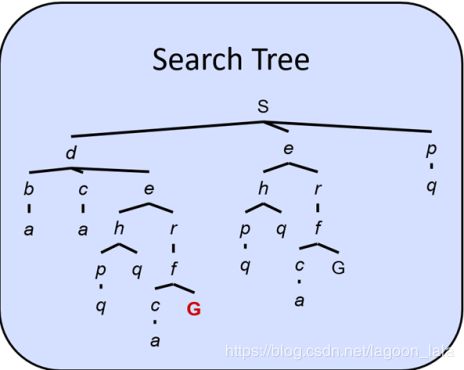
状态空间的图描述

状态空间的有向图描述(搜索树)
状态空间图中,每个状态只出现一次!(搜索树可出现多次)
几乎不在内存中构建完整的状态空间图(太大了),但是有用的。
盲目的图搜索策略
回溯策略
宽度优先搜索策略
深度优先搜索策略
带回溯策略的搜索:
从初始状态出发寻找路径,直到它到达目的或“不可解结点”为止。若它遇到不可解结点就回溯到路径中最近的父结点上,查看该结点是否还有其他的子结点未被扩展。如果找到目标,就成功退出搜索,返回解题路径。
回溯搜索的算法
(1) PS(path states)表:保存当前搜索路径上的状态。如果找到了目的,PS就是解路径上的状态有序集。
(2) NPS(new path states)表:新的路径状态表。它包含了等待搜索的状态,其后裔状态还未被搜索到,即未被生成扩展 。
(3) NSS(no solvable states)表:不可解状态集,列出了找不到解题路径的状态。如果在搜索中扩展出的状态是它的元素,则可立即将之排除,不必沿该状态继续搜索。
图搜索算法(深度优先、宽度优先、最好优先搜索等)的回溯思想:
(1)用未处理状态表(NPS)使算法能返回(回溯)到其中任一状态。 ?
(2)用一张“死胡同”状态表(NSS)来避免算法重新搜索无解的路径。
(3)在PS 表中记录当前搜索路径的状态,当满足目的时可以将它作为结果返回。
(4)为避免陷入死循环必须对新生成的子状态进行检查,看它是否在该三张表中 。
宽度优先搜索策略
open表(NPS表):已经生成出来但其子状态未被搜索的状态。(FIFO)
closed表( PS表和NSS表的合并):记录了已被生成扩展过的状态。
操作算子为MOVE(X,Y):把积木X搬到Y(积木或桌面)上面。
操作算子可运用的先决条件:
(1)被搬动积木的顶部必须为空。
(2)如果 Y 是积木,则积木 Y 的顶部也必须为空。
(3)同一状态下,运用操作算子的次数不得多于一次。

生成扩展完N层的所有结点后才转向N+1层,总能找到最好的解。
当图分支数太多,即状态的后裔数平均值较大,这种组合爆炸会使算法耗尽资源。

为了保证找到解,应选择合适的深度限制值,或采取不断加大深度限制值的办法,反复搜索,直到找到解。
深度优先搜索并不能保证第一次搜索到的是到这个状态的最短路径。
如果路径的长度对解题很关键的话,当算法多次搜索到同一个状态时,它应该保留最短路径。
Open表是一个堆栈结构,使搜索偏向最后生成状态。
特点:
深度优先搜索在搜索有大量分支的状态空间时有高效率,不需要把某层上所有结点进行扩展。
但会找不到通向目的的更短路径或陷入不通往目的的无限长的路径中。
所有的搜索算法都是相同的,除了对边缘的处理策略
从概念上说,所有的边缘是优先队列 (即附加优先级的节点集合)
对于DFS, BFS,可以通过使用栈或队列代替优先队列,从而减少log(n) 的开支
结合DFS的空间优势与BFS的时间优势——迭代深入搜索
启发式图搜索策略(图知识表示、图搜索)
启发式策略
“启发”(heuristic):关于发现和发明操作算子及搜索方法的研究。
在状态空间搜索中,启发式被定义成一系列操作算子,并能从状态空间中选择最有希望到达问题解的路径。
启发式策略:利用与问题有关的启发信息进行搜索。按照什么顺序考察状态空间图的节点。
启发式搜索应用于博弈、机器学习、数据挖掘和智能检索等。
在状态空间搜索中,启发式被定义成一系列操作算子,并能从状态空间中选择最有希望到达问题解的路径。
启发式策略:利用与问题有关的启发信息进行搜索。按照什么顺序考察状态空间图的节点。
运用启发式策略的两种基本情况:
(1)由于问题陈述和数据获取方面固有的模糊性(模糊理论),可能会使它没有一个确定的解。
(2)虽然一个问题可能有确定解,但是其状态空间特别大,搜索中生成扩展的状态数会随着搜索的深度呈指数级增长。(穷尽式搜索、无解)
(3)两部分:启发方法(剪枝)和搜索状态空间的算法。
启发式策略的运用:剪枝(棋盘对称性)以减少状态空间的大小。
棋局走法 9!—— 3*8!(第一步3种走法)——3+12*7!
启发性知识:与被求解问题自身特性相关的知识,包括被求解问题的解特性、解分布规律和实际求解问题的经验和技巧等,对应问题求解的控制性知识。
启发函数:实现启发式搜索,需要把启发性知识函数表示,通过函数计算评价选择价值大小,指导搜索过程。
求解问题中能利用的大多是非完备的启发信息
启发信息的分类:
(1)陈述性启发信息:精准描述状态,缩小问题状态空间。
(2)过程性启发信息:以规律性知识构造操作算子。
(3)控制性启发信息:搜索策略、控制结构等知识。
利用控制性的启发信息的情况:
(1)没有任何控制性知识作为搜索的依据,因而搜索的每一步完全是随意的。
(2)有充分的控制知识作为依据,因而搜索的每一步选择都是正确的,但这是不现实的。
启发函数的设计:
在实际设计过程中,启发函数是用来估计搜索树节点x与目标节点接近程度的一种函数,通常记为h(x)。启发函数可以是:
(1)一个结点到目标结点的某种距离或差异的量度;
(2)一个结点处在最佳路径上的概率;
启发式搜索:用启发函数来导航,其搜索算法就要在状态图一般搜索算法基础上再增加启发函数值的计算与传播过程,并且由启发函数值来确定节点的扩展顺序。分为全局择优搜索和局部择优搜索。
全局择优搜索基本思想:
在OPEN表中保留所有已生成而未考察的节点,并用启发函数h(x)对它们全部进行估价,从中选出最优节点进行扩展,而不管这个节点出现在搜索树的什么地方。
局部(子节点)择优搜索基本思想:
在启发性知识导航下的深度优先搜索,在OPEN表中保留所有已生成而未考察的结点,对其中新生成的每个子结点x计算启发函数,从全部子结点中选出最优结点进行扩展,其选择下一个要考察结点的范围是刚刚生成的全部子结点.
步1 把附有f( S0 )的初始结点S0放入OPEN表中;
步2 若OPEN表为空,则搜索失败,退出;
步3 否则,移出OPEN表中第一个结点N放入CLOSED表中,顺序编号n;
步4 若目标结点Sg=N,则搜索成功,利用CLOSED表中的返回指针找出S0到N的路径即为所求解,退出。
步5 若N不可扩展,则转步2;
6 扩展N,计算N的每个子结点x的函数值,并将N所有子结点x配以指向N的返回指针后放入OPEN表中,依据启发函数对结点的计算,再对OPEN表中所有结点/子结点按其启发函数值的大小以升序排列,转步2。移出OPEN表中第一个结点N放入CLOSED表中
在全局择优和局部择优搜索算法中,没有考虑从初始结点到当前结点已经付出的实际代价。在很多实际问题中,已经付出的实际代价是必须考虑的,如TSP问题等。将两者同时考虑,用于指导搜索的算法称为A算法和A*算法。
启发信息和估价函数:估价函数的任务就是估计待搜索结点的“有希望”程度,并依次给它们排定次序(在open表中)。
从初始结点经过n结点到达目的结点的路径的最小代价估计值
![]()
g(n)代价函数表示从初始结点到n结点的实际代价,越小越靠近初始结点,利于搜索的横向发展,可提高搜索完备性,但影响搜索效率。
h(n)启发函数表示从n 结点到目的结点的最佳路径的估计代价,越小越靠近目标结点,利于搜索的纵向,可提高搜索效率,影响完备性。
一般地,在f(n)中,g的比重越大,越倾向于宽度优先搜索方式,而h的比重越大,表示启发性能越强。f(n)=g(n)+w h(n),调整w的值,使结果偏重效率或完备性
对估价函数
f(x) =g(x)+h(x)
令其中h(x)=0时,得到代价树的非启发式搜索算法。
按对节点的考察范围不同,可分为两种搜索策略:
分支界限法
将全局择优搜索算法中的h(x)替换为g(x),可得到分支界限法。
瞎子爬山法
将局部择优搜索算法中的h(x)替换为g(x) , 可得到瞎子爬山法
A搜索算法
启发式图搜索法的基本特点:如何寻找并设计一个与问题有关的h(n)及构出f(n)=g(n)+ h(n),, 然后以f(n)的大小来排列待扩展状态的次序,每次选择 f(n)值最小者进行扩展。
open表:保留所有已生成而未扩展的状态。
closed表:记录已扩展过的状态。
进入open表的状态是根据其估值的大小插入到表中合适的位置,每次从表中优先取出启发估价函数值最小的状态加以扩展。
open:=[start];closed:=[ ];f(s):=g(s)+h(s); *初始化
while open≠[ ] do
begin
从open表中删除第一个状态,称之为n;
if n=目的状态 then return(success);
生成n的所有子状态;
if n没有任何子状态 then continue;
for n的每个子状态do
case子状态is not already on open表or closed表;
begin
计算该子状态的估价函数值;
将该子状态加到open表中;
end;
case子状态is already on open表:
if该子状态是沿着一条比在open表已有的更短路径而到达
then 记录更短路径走向及其估价函数值;
case子状态is already on closed表:
if该子状态是沿着一条比在closed表已有的更短路径而到达then
begin
将该子状态从closed表移到open表中;
记录更短路径走向及其估价函数值;
end;
case end;
将n放入closed表中;
根据估价函数值,从小到大重新排列open表;
end; *open表中结点已耗尽
return(failure);
end.
八数码:以“不在位”的将牌数作为启发信息的度量。
h*(n):为状态 到目的状态的最优路径的代价
A*搜索算法及其特性分析:
如果某一问题有解,那么利用A*搜索算法对该问题进行搜索则一定能搜索到解,并且一定能搜索到最优的解而结束。
上例中的八数码A搜索树也是A*搜索树,所得的解路(s,B,E,I,K,L)为最优解路,其步数为状态L(5)上所标注的5 。
1. 可采纳性
当一个搜索算法在最短路径存在时能保证找到它,就称它是可采纳的。
2. 单调性
搜索算法的单调性:在整个搜索空间都是局部可采纳的。一个状态和任一个子状态之间的差由该状态与其子状态之间的实际代价所限定。
3. 信息性
在两个A*启发策略的h1h2中,如果对搜索空间中的任一状态n都有h1(n)<=h2(n),就称策略h1有更多的信息性。