Spark性能调优:使用Kryo序列化库、RDD的压缩
使用Kryo序列化的原因
默认情况下,Spark内部是通过Java序列化(默认的序列化方式)形成一个二进制字节数组,大大减少了数据在内存、硬盘中占用的空间,减少了网络数据传输的开销,并且可以精确的推测内存使用情况,降低GC频率。
这种默认序列化机制的好处在于:处理起来比较方便,也不需要我们手动去做什么事情,只是在算子里面使用的变量必须是实现Serializable接口的,可序列化即可。
但是缺点在于:默认的序列化机制的效率不高,序列化的速度比较慢;序列化以后的数据,占用的内存空间相对还是比较大。
可以手动进行序列化格式的优化,Spark支持使用Kryo序列化机制。Kryo序列化机制比默认的Java序列化机制速度要快,序列化后的数据要更小,大概是Java序列化机制的1/10。所以Kryo序列化优化以后,可以让网络传输的数据变少,在集群中耗费的内存资源大大减少。
Kryo序列化生效位置
在Spark的架构中,在网络中传递的或者缓存在内存、硬盘中的对象需要进行序列化操作,序列化的作用主要是利用时间换空间:
1、算子函数中使用到的外部变量 ,会序列化,这时可以是用Kryo序列化机制;[广播变量]
2、持久化 RDD 时进行序列化,比如StorageLevel.MEMORY_ONLY_SER,可以使用 Kryo 进一步优化序列化的效率和性能;
3、进行shuffle时,比如在进行stage间的task的shuffle操作时,节点与节点之间的task会互相大量通过网络拉取和传输文件,此时,这些数据既然通过网络传输,也是可能要序列化的,就会使用Kryo。
4、分发给Executor上的Task。
默认对Task使用Java序列化
由于 Spark2.1.0默认对Task使用Java序列化(该序列化方式不允许修改,源码如下):
/**
* SparkEnv.scala
* Helper method to create a SparkEnv for a driver or an executor.
*/
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER
......
val serializer = instantiateClassFromConf[Serializer](
"spark.serializer", "org.apache.spark.serializer.JavaSerializer")
logDebug(s"Using serializer: ${serializer.getClass}")
......
}Kryo序列化库主要参数介绍
先介绍几个相关的配置:
| Property Name | Default | Meaning |
|---|---|---|
| spark.kryo.classesToRegister | (none) | 如果您使用Kryo序列化,请给出一个以逗号分隔的自定义类名称list列表,以向Kryo注册。有关更多细节,请参阅调优指南[tuning guide]。 |
| spark.kryo.referenceTracking | true | 跟踪对同一个对象的引用情况,这对发现有循环引用或同一对象有多个副本的情况是很有用的。设置为false可以提高性能 |
| spark.kryo.registrationRequired | false | 是否需要在Kryo登记注册?如果为true,则序列化一个未注册的类时会抛出异常 |
| spark.kryo.registrator | (none) | 为Kryo设置这个类去注册你自定义的类。最后,如果你不注册需要序列化的自定义类型,Kryo也能工作,不过每一个对象实例的序列化结果都会包含一份完整的类名,这有点浪费空间 |
| spark.kryo.unsafe | false | 是否使用基于不安全的Kryo序列化器。使用不安全的IO可以大大加快速度。 |
| spark.kryoserializer.buffer.max | 64m | 允许使用序列化buffer的最大值 |
| spark.kryoserializer.buffer | 64k | 每个Executor中的每个core对应着一个序列化buffer。如果你的对象很大,可能需要增大该配置项。其值不能超过spark.kryoserializer.buffer.max |
| spark.serializer | org.apache.spark. serializer.JavaSerializer | 序列化时用的类,需要申明为org.apache.spark.serializer.KryoSerializer。这个设置不仅控制各个worker节点之间的混洗数据序列化格式,同时还控制RDD存到磁盘上的序列化格式及广播变量的序列化格式。 |
TIPS : 更多的Kryo配置及使用细节,参考文末的链接
实现Kryo序列化步骤
java
1、设置序列化使用的库
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"); //使用Kryo序列化库2、在该库中注册用户定义的类型
conf.set("spark.kryo.registrator", toKryoRegistrator.class.getName());
//在Kryo序列化库中注册自定义的类集合3、在自定义类中实现KryoRegistrator接口的registerClasses方法
//外部变量
static class Tmp1 implements java.io.Serializable {
public int total_;
public int num_;
}
public static class toKryoRegistrator implements KryoRegistrator {
@Override
public void registerClasses(Kryo kryo) {
//在Kryo序列化库中注册自定义的类
kryo.register(Tmp1.class,new FieldSerializer(kryo,Tmp1.class));
}
}scala
// 创建SparkConf对象。
val conf = new SparkConf().setMaster(...).setAppName(...)
// 设置序列化器为KryoSerializer。
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册要序列化的自定义类型。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))Java实战代码解析
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.serializer.KryoRegistrator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.serializers.FieldSerializer;
import org.apache.spark.storage.StorageLevel;
/**
* User:leen
* Date:2017/12/5 0005
* Time:17:08
*/
public class JavaKryoSerializer {
static class Tmp1 implements java.io.Serializable {
public int total_;
public int num_;
}
public static class toKryoRegistrator implements KryoRegistrator {
@Override
public void registerClasses(Kryo kryo) {
kryo.register(Tmp1.class, new FieldSerializer(kryo, Tmp1.class));
}
}
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf().setAppName("JavaKryoSerializer").setMaster("local");
//使用Kryo序列化库,如果要使用Java序列化库,需要把该行屏蔽掉
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//在Kryo序列化库中注册自定义的类集合,如果要使用Java序列化库,需要把该行屏蔽掉
conf.set("spark.kryo.registrator", toKryoRegistrator.class.getName());
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD lines = sc.textFile("hdfs://leen:8020/black03.txt");
JavaRDD words = lines.flatMap(new FlatMapFunction() {
@Override
public Iterable call(String line) throws Exception {
return Arrays.asList(line.split("\\\t"));
}
});
JavaRDD wordsLength = words.map(new Function() {
@Override
public Integer call(String word) {
return word.length();
}
});
JavaRDD res = wordsLength.map(new Function() {
@Override
public Tmp1 call(Integer x) {
//只是为了将rdd4中的元素类型转换为Tmp1类型的对象,没有实际的意义
Tmp1 a = new Tmp1();
a.total_ += x;
a.num_ += 1;
return a;
}
});
//将rdd4以序列化的形式缓存在内存中,因为其元素是Tmp1对象,所以使用Kryo的序列化方式缓存
res.persist(StorageLevel.MEMORY_ONLY_SER());
System.out.println("the count is " + res.count());
//调试命令,只是用来将程序挂住,方便在Driver 4040的WEB UI中观察rdd的storage情况
while (true) {
}
//sc.stop();
}
}
1、使用默认的Java序列化库的情况:缓存后的 rdd4占用内存空间192.5MB

2、使用Kryo序列化库的情况:缓存后的 rdd4占用内存空间53.4MB
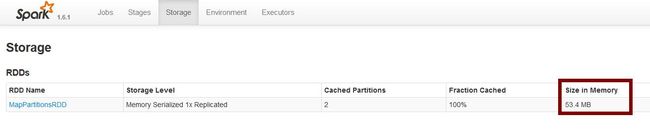
可以看出,使用了Kryo序列化库后,rdd4在内存中占用的空间从192.5MB降低到53.4MB,比使用Java序列化库节省了4倍左右的空间(如果使用其他更适合压缩的对象类型,应该能达到官方的所说的提升10倍的压缩比)
拓展RDD的压缩
如果想进一步的节省内存、硬盘的空间,减少网络传输的数据量,可以配合的使用Spark支持的压缩方式(目前默认是lz4),广播变量、shuffle过程中的数据都默认使用压缩功能。(注意,RDD默认是不压缩的)
| Property Name | Default | Meaning |
|---|---|---|
| spark.io.compression.codec | lz4 | 压缩用于压缩内部数据,如RDD分区、事件日志、广播变量和shuffle输出。默认情况下,Spark提供三个压缩方式:lz4、lzf和snappy。您还可以使用完全限定的类名来指定编解码器。org.apache.spark.io.LZ4CompressionCodec, org.apache.spark.io.LZFCompressionCodec, org.apache.spark.io.SnappyCompressionCodec. |
| spark.broadcast.compress | true | 是否在发送之前压缩广播变量。默认压缩 |
| spark.shuffle.compress | true | shuffle中map的输出文件默认是压缩的 |
| spark.shuffle.spill.compress | true | 在shuffles中的切片数据默认是压缩的 |
| spark.rdd.compress | false | 是否压缩序列化的RDD分区数据,可以节省大量的空间以节省额外的CPU时间【默认不压缩】 (例如:在Java和scala中的StorageLevel.MEMORY_ONLY_SER 或者 在Python中的StorageLevel.MEMORY_ONLY) |
RDD持久化操作时使用压缩机制(注意,只有序列化后的RDD才能使用压缩机制)
//SparkConf 增加下面的配置
conf.set("spark.rdd.compress", "true");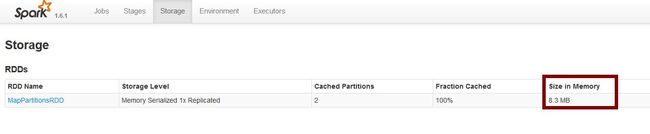
效果很显著吧!rdd4持久化后在内存中占用的空间降低到8.3MB!
不过使用压缩机制,也会增加额外的开销,也会影响到性能,这点需要注意。
参考
[Spark Configuration] : http://spark.apache.org/docs/latest/configuration.html
[Turn Guide]:http://spark.apache.org/docs/latest/tuning.html
[Kryo]:https://github.com/EsotericSoftware/kryo