CondenseNet:可学习分组卷积,原作对DenseNet的轻量化改造 | CVPR 2018
CondenseNet特点在于可学习分组卷积的提出,结合训练过程进行剪枝,不仅能准确地剪枝,还能继续训练,使网络权重更平滑,是个很不错的工作
来源:晓飞的算法工程笔记 公众号
论文:Neural Architecture Search with Reinforcement Learning

- 论文地址:https://arxiv.org/abs/1711.09224
- 论文代码:https://github.com/ShichenLiu/CondenseNet
Introduction

DenseNet基于特征复用,能够达到很好的性能,但是论文认为其内在连接存在很多冗余,早期的特征不需要复用到较后的层。为此,论文基于可学习分组卷积提出CondenseNet,能够在训练阶段自动稀疏网络结构,选择最优的输入输出连接模式,并在最后将其转换成常规的分组卷积分组卷积结构。
CondenseNets

分组卷积能够有效地降低网络参数,对于稠密的网络结构而言,可以将 3 × 3 3\times 3 3×3卷积变为 3 × 3 3\times 3 3×3分组卷积。然而,若将 1 × 1 1\times 1 1×1卷积变为 1 × 1 1\times 1 1×1分组卷积,则会造成性能的大幅下降,主要由于 1 × 1 1\times 1 1×1卷积的输入一般有其内在的联系,并且输入有较大的多样性,不能这样硬性地人为分组。随机打乱能够一定程度地缓解性能的降低,但从实验来看还不如参数较少的DenseNet。
另外,论文认为稠密连接虽然有利于特征复用,但是存在较大的冗余性,但很难定义哪个特征对当前层是有用的。为此,论文引入了可学习的分组卷积来解决上述问题。
-
Learned Group Convolution

分组卷积的学习包含多个阶段,如图3和图4所示,前半段训练过程包含多个condensing阶段,结合引导稀疏化的正则化方法来反复训练网络,然后将不重要的filter剪枝。后半部分为optimization阶段,这个阶段对剪枝固定后的网络进行学习。实现细节如下:
- Filter Groups,卷积分组
将标准卷积进行分组,比如 1 × 1 1\times 1 1×1卷积的核大小为 O × R O\times R O×R矩阵 F \mathbb{F} F,将该卷积核分为 G G G组,标记为 F 1 , F 2 , ⋯ , F G \mathbb{F}^1,\mathbb{F}^2,\cdots,\mathbb{F}^G F1,F2,⋯,FG,每个 F g \mathbb{F}^g Fg大小为 O G × R \frac{O}{G}\times R GO×R, F i , j g \mathbb{F}_{i,j}^g Fi,jg代表 g g g组内处理 i i i输入和 j j j输出的卷积核,注意这里没有对输入进行对应的分组。
- Condensation Criterion,压缩标准
在训练的过程逐步剔除每个组中权重较低的输入特征子集, i i i输入特征对于 g g g组的重要程度通过求和组内所有对应的权值获得 ∑ i = 1 O / G ∣ F i , j g ∣ {\sum}_{i=1}^{O/G} |\mathbb{F}_{i,j}^g| ∑i=1O/G∣Fi,jg∣,将 F g \mathbb{F}^g Fg中重要程度较小的输入特征对应的列置为零,从而将卷积层稀疏化。
- Group Lasso
一般而言,为了减少剪枝带来的准确率影响,可以通过使用L1正则方法引导权值尽量稀疏。由于分组卷积的特性,CondenseNets需要更严格的列稀疏来引导组内的卷积尽量使用相同的输入子集,因此采用group级别的稀疏性,论文提出group-lasso正则化:

根号内的项由列中最大的元素主宰,group-lasso能够引导稀疏的 F g F^g Fg列趋向完全为0。
- Condensation Factor
可学习分组卷积不仅能够自动发现最优的输入输出连接模式,而且更灵活。组内使用的输入特征数不一定为 1 G \frac{1}{G} G1倍,而是根据定义condensation factor C C C(不一定等于 G G G),允许每组选择 ⌊ R C ⌋ \lfloor \frac{R}{C} \rfloor ⌊CR⌋个输入。
- Condensation Procedure
CondenseNet的剪枝在训练过程中进行,如图3所示,在每个 C − 1 C-1 C−1condensing阶段,会剪除 1 C \frac{1}{C} C1权重,在训练的最后,仅保留每个卷积组内的 1 C \frac{1}{C} C1权重。每个condensing阶段的训练周期设为 M 2 ( C − 1 ) \frac{M}{2(C-1)} 2(C−1)M, M M M为总的训练周期,所有condensing阶段共占训练的一半。
需要注意,训练阶段并没有真正地将权重去除,而是使用二值tensor作为掩膜进行element-wise相乘,这样的实现在GPU上仍是高效的,不会带来太多额外的耗时。
- Learning rate

训练使用cosine学习率退火,训练过程如图4所示,中间的损失突然上升是由于最后的condensing阶段后剪枝了一半的权重(最后的condensing阶段内仅 2 C \frac{2}{C} C2权重)导致的,但从图中可以看出,训练很快就恢复了。
- Index Layer
在训练后,需要去除剪枝的权重转换为常规的网络结构,这样不仅能够降低网络参数,还能保证在计算能耗有限的设备上高效运行。为此CondenseNet在发布时需要加入Index层,该层的原理如图3最右所示,根据剪枝后的剩余权重对输入特征进行重排,将可学习分组卷积的剩余权重转换成分组卷积,训练阶段到测试阶段的转换如图1。
需要注意,论文对 1 × 1 1\times 1 1×1分组卷积的输出进行了重排,这样做的原因是为了让后面的分组卷积能够地使用到前面分组卷积提取的属性。
Architecture Design

除了可学习分组卷积,论文还对原来的DenseNet结构进行了修改,如图5所示,共包含两点修改:
- Exponentially increasing growth rate(IGR),Densenet每层增加 k k k个新的特征图, k k k称为增长率。而论文发现越深的层实际更依赖较高维的特征,因此需要增强与当前层较近的特征连接,通过逐渐增加增长率来实现。设置增长率为 k = 2 m − 1 k 0 k=2^{m-1}k_0 k=2m−1k0, m m m为dense block下标, k 0 k_0 k0为常数,这样能够增加较后层输出的特征的占比。
- Fully dense connectivity(FDC),为了更多的特征重用,将所有的层进行了连接,并为不同的层提供了不同的下采样操作。
Experiments

验证论文提出的改进方法的效果。

CIFAR-10上的轻量级网络性能对比。
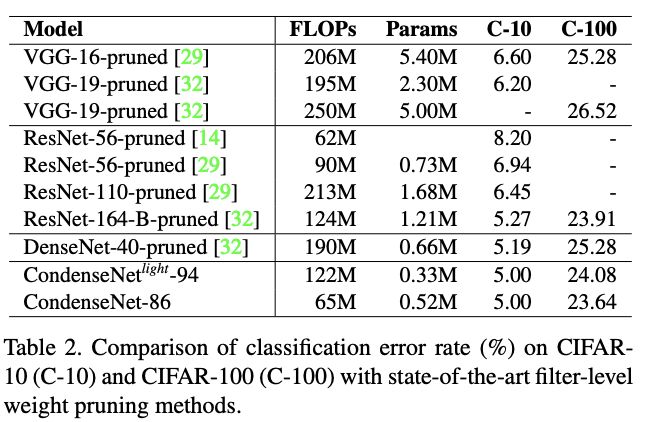
CIFAR-10和CIFAR-100上的剪枝SOTA网络性能对比。


ImageNet上的轻量级网络性能对比。

ImageNet上的SOTA网络推理耗时对比。

对不同超参进行了对比实验。
CONCLUSION
CondenseNet特点在于可学习分组卷积的提出,整体的结构设计十分巧妙。以往的剪枝工作都是在网络训练后进行的,导致精度有较大的下降,而可学习分组卷积结合训练过程进行剪枝,不仅能准确地剪枝,还能继续训练,使网络权重更平滑,是个很不错的工作。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
