【Paper】CTC Introduce
Connectionist Temporal Classification, an algorithm used to train deep neural networks in speech recognition, handwriting recognition and other sequence problems.
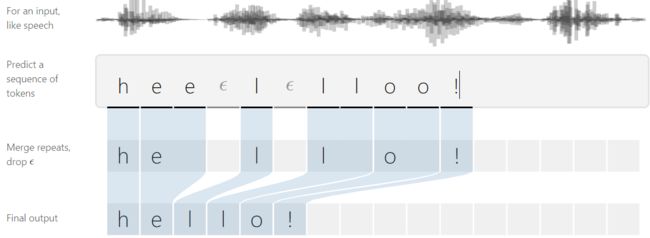
1. Problem
- don’t know the characters in the transcript align to the audio when having a dataset of audio clips and corresponding transcripts.
- people’s rates of speech vary.
- hand-align takes lots of time.
- Speech recognition, handwriting recognition from images, sequences of pen strokes, action labelling in videos.
2. Question Define
when mapping input sequences X = [ x 1 , x 2 , … , x T ] X = [x_1, x_2, \ldots, x_T] X=[x1,x2,…,xT], such as audio, to corresponding output sequences Y = [ y 1 , y 2 , … , y U ] Y = [y_1, y_2, \ldots, y_U] Y=[y1,y2,…,yU], such as transcripts. We want to find an accurate mapping from X ′ s X's X′s to Y ′ s Y's Y′s.
- Both X X X and Y Y Y can vary in length.
- The ratio of the lengths of X X X and Y Y Y can vary.
- we don’t have an accurate alignment(correspondence of the elements) of X X X and Y Y Y.
The CTC algorithm, for a given X X X it gives us an output distribution over all possible Y ′ s Y's Y′s, we can use this distribution either to infer a likely output or to assess the probability of a given output.
- Loss Function: maximize the probability it assigns to the right answer, compute the conditional probability p ( Y ∣ X ) p(Y|X) p(Y∣X);
- Inference: infer a likely Y Y Y given an X X X, Y ∗ = a r g m a x p ( Y ∣ X ) Y^*=argmaxp(Y|X) Y∗=argmaxp(Y∣X);
3. Alignment
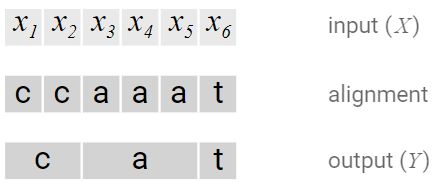
- Often, it doesn’t make sense to force every input step to align to some output. In speech recognition, for example, the input can have stretches of silence with no corresponding output.
- We have no way to produce outputs with multiple characters in a row. Consider the alignment [h, h, e, l, l, l, o]. Collapsing repeats will produce “helo” instead of “hello”.

- the allowed alignments between X X X and Y Y Y are monotonic
- the alignment of X X X to Y Y Y is many-to-one.
- the length of Y Y Y cannot be greater than the length of X X X.
4. Searching Methods



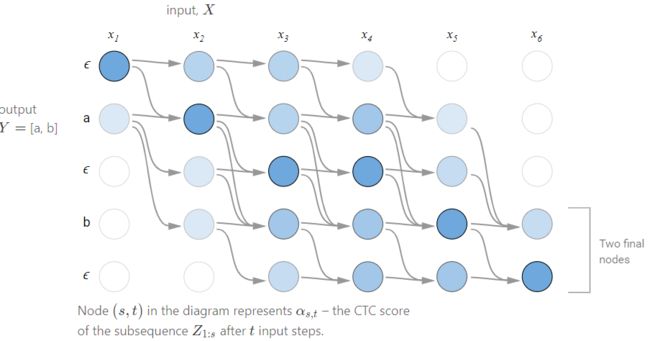
Z = [ ϵ , y 1 , ϵ , y 2 , … , ϵ , y U , ϵ ] Z=[ϵ, y_1, ϵ, y_2, …, ϵ, y_U, ϵ] Z=[ϵ,y1,ϵ,y2,…,ϵ,yU,ϵ]
- Case 1: can’t jump over z s − 1 z_{s-1} zs−1, the previous token in Z Z Z.
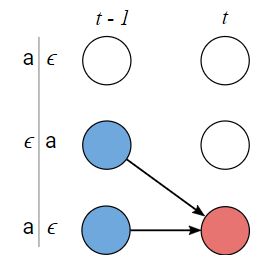

- Case 2: allowed to skip the previous token in Z Z Z.
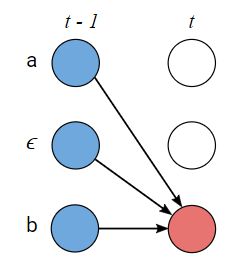
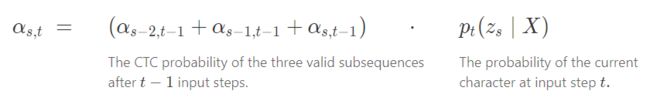
- Loss Function: for a training set D, the model’s parameters are tuned to minimize the negative log-likelihood instead of maximizing the likelihood directly.
∑ ( X , Y ) ϵ D − l o g P ( Y ∣ X ) \sum_{(X,Y)\epsilon D}-logP(Y|X) (X,Y)ϵD∑−logP(Y∣X)
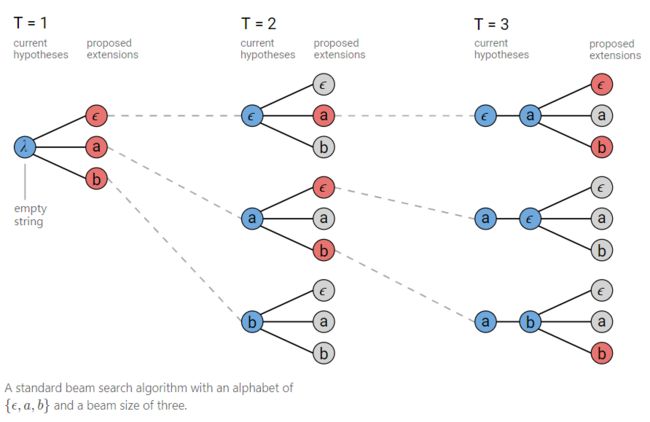
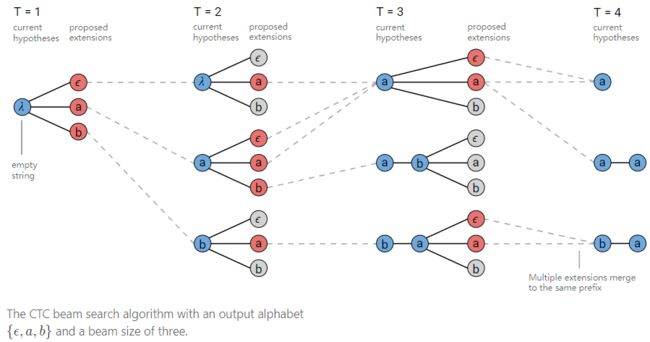
- Inference: (3) don’t take into account the fact that a single output can have many alignments.
Y ∗ = a r g m a x Y p ( Y ∣ X ) A ∗ = a r g m a x A ∏ t = 1 T p t ( a t ∣ X ) Y^*=argmax_Yp(Y|X)\\ A^*=argmax_A\prod_{t=1}^Tp_t(a_t|X) Y∗=argmaxYp(Y∣X)A∗=argmaxAt=1∏Tpt(at∣X)
5. Properties of CTC
- Conditional Independence
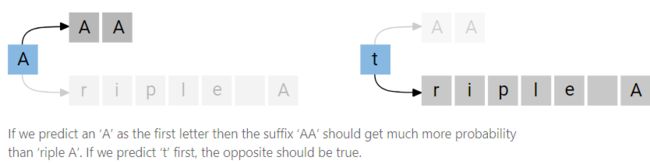
- Alignment Properties
CTC only allows monotonic alignments. In problems such as speech recognition this may be a valid assumption. For other problems like machine translation where a future word in a target sentence can align to an earlier part of the source sentence, this assumption is a deal-breaker.
6. Usage
- Baidu Research has open-sourced warp-ctc. The package is written in C++ and CUDA. The CTC loss function runs on either the CPU or the GPU. Bindings are available for Torch, TensorFlow and PyTorch.
- TensorFlow has built in CTC loss and CTC beam search functions for the CPU.
- Nvidia also provides a GPU implementation of CTC in cuDNN versions 7 and up.
to normalize the α \alpha α’s at each time-step to deal with CTC loss numerically unstable problem.
A common question when using a beam search decoder is the size of the beam to use. There is a trade-off between accuracy and runtime.
**From:**https://distill.pub/2017/ctc/