机器学习-Kaggle竞赛-Digit recognizer
第一次接触Kaggle比赛。从练习区开始~~~
做了一个最简单的手写数字识别练习(Digit Recognizer)。
尝试了用KNN,bayes,Logistic Regression,svm。
首页拿到练习数据,digit-recognizer-data
下载train.csv test.csv文件
train.csv
train.csv里面是42000*785的数据
每一行代表一个图片~,由784个像素组成(0~255)。
第0列是真实的数字值。
test.csv
train.csv里面是28000*784的数据
比训练数据少了第0列。所以要拿来预测~
KNN
首先将每个图片的像素值都变成010010010形式,即像素值大于0的变成1.
将train.csv变成42000*784的矩阵。
def csv2vector(filename,index=0):
fr = open(filename)
filelines = fr.readlines()
del filelines[0]
lenlines = len(filelines)
returnVect = zeros((lenlines,784))
labellist = [0]*lenlines
for i in range(lenlines):
lineStr = filelines[i]
linearr = lineStr.split(',')
if len(linearr)< 784:
continue
labellist[i] = linearr[0]
for j in range(index,len(linearr)):
if linearr[j] != '0':
returnVect[i,j-index] = 1
else:
returnVect[i,j-index] = 0
fr.close()
return returnVect,labellist然后拿一部分训练数据当测试数据,测试下正确率有多少。
>>> trainSet,trainlabel = knn.csv2vector(“train.csv”,1)
>>> knn.testrun(trainSet[20000:30000],trainlabel[20000:30000],trainSet[0:20000],trainlabel[0:20000])
这里选取2w做训练数据,1w当测试数据,查看效果~。
这里要跑好一会的~。如果效果还可以,然后就可以直接上 test.csv数据,然后提交结果。(如何提交下面再讲)。
def testknn(testSet,testlabel,trainSet,trainlabel):
start = time.clock()
num=0
for i in range(len(testSet)):
tmp = classify0(testSet[i],trainSet,trainlabel,3)
if tmp != testlabel[i]:
num = num + 1
print tmp,",",testlabel[i]
print "error:",num
print "error percent:%f" % (float(num)/len(testSet))
end = time.clock()
print "time cost: %f s" % (end - start)
print "end"
def classify0(inx,dataSet,labels,k):
datanum=dataSet.shape[0]
inxtemp=tile(inx,(datanum,1))-dataSet #矩阵相减
sqinxtemp=inxtemp**2
sqdistance=sqinxtemp.sum(axis=1)
distance=sqdistance**0.5
sortdist=distance.argsort()
classset={}
for i in range(k):
labeltemp = labels[sortdist[i]]
classset[labeltemp]=classset.get(labeltemp,0)+1
sortedclassset=sorted(classset.iteritems(),key=lambda d:d[1],reverse=True)#对字典中的数据排序
return sortedclassset[0][0]正确率
最终我拿train.csv的2w数据,直接跑test.csv。花了70多分钟~~
机器配置:ubuntu15.04虚拟机~
正确率:0.95543
这个数字看起来还可以的样子,实际排名很差的。。。(没脸上图了-.-
如果把42000全部数据来跑,效果可能会更好点,但是要很长时间。。。再看看别的算法效果。
Bayes
def trainNB0(trainMatrix,trainclass):
numpics = len(trainMatrix) #record numbers
numpix = len(trainMatrix[0])#pix numbers
pDic={}
for v in trainclass:
pDic[v] = pDic.get(v,0)+1
for k,v in pDic.items():
pDic[k]=v/float(numpics)#p of every class
pnumdic={}
psumdic={}
for k in pDic.keys():
pnumdic[k]=ones(numpix)
for i in range(numpics):
pnumdic[trainclass[i]] += trainMatrix[i]
psumdic[trainclass[i]] = psumdic.get(trainclass[i],2) + sum(trainMatrix[i])
pvecdic={}
for k in pnumdic.keys():
pvecdic[k]=log(pnumdic[k]/float(psumdic[k]))
return pvecdic,pDic
def classifyNB(vec2class,pvecdic,pDic):
presult={}
for k in pDic.keys():
presult[k]=sum(vec2class*pvecdic[k])+log(pDic[k])
tmp=float("-inf")
result=""
for k in presult.keys():
if presult[k]>tmp:
tmp= presult[k]
result=k
return result
def testNB():
print "load train data..."
trainSet, trainlabel=csv2vector("train.csv",1)
print "load test data..."
testSet,testlabel = csv2vector("test.csv")
print "start train..."
pvecdic,pDic=trainNB0(trainSet, trainlabel)
start = time.clock()
print "start test..."
result="ImageId,Label\n"
for i in range(len(testSet)):
tmp = classifyNB(testSet[i],pvecdic,pDic)
result += str(i+1)+","+tmp+"\n"
#print tmp
savefile(result,"result_NB.csv")
end = time.clock()
print "time cost: %f s" % (end - start)第一次提交的时候,想到knn跑起来太慢了,于是想试试朴素贝叶斯。不过效果并不理想。
正确率:0.81左右
Logistic Regression
逻辑回归一般用于2分类问题,但是这里有0-9,10类情况~。这里需要转化下,对一个未知数字识别的时候作10次判断, 0和非0、1和非1…9和非9。
因此需要获得10组的回归系数~~。
为了加快速度,开启了10个线程来计算。
def train(data,labels):
print "train start"
start = time.clock()
threads = []
for i in range(10):#开启10个线程计算
t = threading.Thread(target=trainweight,args=(data,labels,i))
threads.append(t)
for i in range(len(threads)):
threads[i].start()
print "thread",i," start"
for i in range(len(threads)):
threads[i].join()
print "thread",i," end"
print "train end"
end = time.clock()
print "train time cost: %f s" % (end - start)
return g_we_listg_we_list=[0,0,0,0,0,0,0,0,0,0]
def trainweight(data,labels,tag):
we = getweight(data,labels,str(tag))
g_we_list[tag]=we
def getlabels(labels,tag):
labels_ = list(labels)
for i in range(len(labels_)):
if labels_[i] ==tag:
labels_[i]=1
else:
labels_[i]=0
return labels_
def getweight(testdata,testlabels,tag):
labels=getlabels(testlabels,tag)
we = stocalcgrand1(testdata,labels)
we = mat(we).transpose()
return we
def stocalcgrand1(dataMatin,labelMatin,numiter=100):
m,n=shape(dataMatin)
alpha=0.01
weight=ones(n)
for i in range(numiter):
dataIndex=range(m)
for j in range(m):
alpha=0.005/(1.0+i)+0.005
randIndex=int(random.uniform(0,len(dataIndex)))
h=sigmod(sum(dataMatin[randIndex]*weight))
error=labelMatin[dataIndex[randIndex]]-h
weight=weight+alpha*error*dataMatin[randIndex]
del(dataIndex[randIndex])
return weight测试效果:
def test(testData,testlabel,we_list):
error = 0
for i in range(len(testData)):
#for j in range(len(we_list)):
rec = classfy(testData[i],we_list)
if testlabel[i] != str(rec):
error = error+1
print testlabel[i],",",rec
print "error=",error
print "error percent:%f" % (float(error)/len(testData))
def classfy(testData,we_list):
tmp=0
labels = -1
for i in range(len(we_list)):#根据sigmod的值大小来确定是哪一类
sg = sigmod(testData*we_list[i])
if sg>tmp:
tmp = sg
labels = i
return labels
正确率:0.90左右
3w的数据来训练回归系数。效果也一般最终也没提交~(没信心了~~ -.-
最后~~尝试一把站在巨人肩膀上的感觉~
svm
使用scikit-learn的svm包来验证下效果~。
scikit-learn包是python的一套机器学习包,包含了很多现成的机器学习算法。官网有很多的例子~用起来很方便。
直接上代码~就知道有多方便了。
import numpy as np
from sklearn.svm import SVC
def train(testdata,testlabels):
clf=SVC()
clf.fit(testdata,testlabels)
print "svn train success."
return clf
def test(clf,test,label):
testsize=len(test)
num=0
for i in range(testsize):
tmp = clf.predict(test[i])
if label[i] != tmp[0]:
num = num +1
print label[i],",",tmp[0]
print "error:",num
print "error percent:%f" % (float(num)/testsize)使用默认的参数~
训练3w数据,测试1w
效果是0.94,而且训练速度很快,几分钟就够了。
提交结果
点击这里的 Make a submission
然后 点击 click or … 提交你的结果文件.
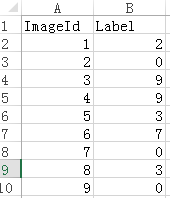
这里的文件形式需要 csv格式。
内容形式是
最后看成绩。
总结
看了网上很多的文章,要达到0.99的正确率,还是要做大量的工作的,简单的用下某个算法还是不太行~。
继续改算法……-.-
参考
http://scikit-learn.org/
Kaggle项目实战1——Digit Recognizer——排名Top10%
Digit Recognizer (Kaggle)
大数据竞赛平台——Kaggle 入门