基于Python3 防止中文乱码的XML读取分析方式实现
1. XML文件格式简述
XML(Extensible Markup Language)中文意思为可扩展标记语言,标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言
通常情况下XML 文档的第一行是一个 XML 声明,这是文件的可选部分,它将文件识别为 XML 文件,有助于工具和人类识别 XML(不会误认为是 SGML 或其他标记)。可以将这个声明简单地写成 ,或包含 XML 版本(),甚至包含字符编码,比如针对 Unicode 的
XML文件核心区域主要包括根元素、命名元素、嵌套元素以及元素的属性,本文中使用的文件内容如下所示
2. 文件编码和内容编码
用UtraEdit创建新文件,内容填上如上所示的内容,并保存文件为类型为xml的文件。默认文件格式为Unicode。xml文件格式支持如下的几种类型
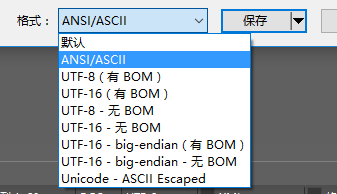
2.1 以ANSI方式存储
如果文件格式为ANSI/ASCII,则需要将Unicode转化成为ANSI方式以及指定为中文GBK字符集。
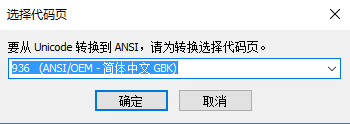
但是这不意味着xml描述部分要写成,如果写成这个样子文件正文内的中文部分反而变成了乱码,正确的方式是
2.2 以UTF-8方式存储
如果文件存储方式改成utf-8的方式,则无论xml首部的内容写成还是对于文件内的中文部分都不是太影响。
概况起来两种文件方式和两种编码方式的组合结果如下:
| 文件格式 |
encoding编码格式 |
中文是否乱码 |
| ANSI |
Gb2312 |
是 |
| utf-8 |
否 |
|
| UTF-8 |
Gb2312 |
否 |
| utf-8 |
否 |
3. python对于含有中文的xml解析思路
从笔者在处理文件过程中遇到的问题来看应该有两个方面的原因会造成处理异常现象。一种是在采用 标记xml文件时,如果是直接用xml.dom.minidom加载处理的话会出现异常,另外一种是即使是encoding为utf-8,如果中文字符过长也存在问题。
对于第一种方式有网友解释采用先解码再编码为utf8,最终通过替换为utf8的方式实现,
Utf_xml = xmlcontext.decode('gb2312').encode('utf-8'),
Dest_xml = Utf_xml.replace('gb2312', 'utf-8')
但是这种方式说实在是太累赘,不好用,经过笔者摸索,发现采用如下的方式就可以很容易的实现含有中文字符的任意格式的xml读取。
l 采用二进制的方式读取文件正文,
l 读取的正文为byte类型,通过bytes.decode()函数转化成字符串。
l 用xml.dom.minidom和 parseString函数加载xml正文字符串即可实现无论是gb2312还是utf8的方式中文内容读取
4. 代码实现
import abc import os import xml.dom.minidom as xml class XmlReader(object): __metaclass__ = abc.ABCMeta def __init__(self): pass def read_content(self,filename): content = None if (False == os.path.exists(filename)): return content filehandle = None try: filehandle = open(filename,'rb') except FileNotFoundError as e: print(e.strerror) try: content = filehandle.read() except IOError as e: print(e.strerror) if (None != filehandle): filehandle.close() if(None != content): return bytes.decode(content) return content @abc.abstractmethod def load(self,filename): pass
class XmlTester(XmlReader): def __init__(self): XmlReader.__init__(self) def load(self, filename): filecontent = XmlReader.read_content(self,filename) if None != filecontent: dom = xml.parseString(filecontent) root = dom.getElementsByTagName('root')[0] items = root.getElementsByTagName('Item') for item in items: value = item.getAttribute('Value') print(value)
if __name__=='__main__': reader = XmlTester() reader.load('d:/ansi_utf.xml') reader.load('d:/utf_utf.xml') reader.load('d:/utf_gbk.xml')
输出结果:
这是一个测试
This is a test
这是一个测试
This is a test
这是一个测试
This is a test