mysql explain执行计划 type 和 extra 字段说明
参考文章:如何利用工具,迅猛定位低效SQL? | 1分钟系列
同一个SQL语句,为啥性能差异咋就这么大呢?(1分钟系列
1.type字段
explain结果中的type字段代表什么意思?

MySQL的官网解释非常简洁,只用了3个单词:连接类型(the join type)。它描述了找到所需数据使用的扫描方式。
最为常见的扫描方式有:
-
system:系统表,少量数据,往往不需要进行磁盘IO;
-
const:常量连接;
-
eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描;
-
ref:非主键非唯一索引等值扫描;
-
range:范围扫描;
-
index:索引树扫描;
-
ALL:全表扫描(full table scan);
画外音:这些是最常见的,大家去explain自己工作中的SQL语句,95%都是上面这些类型。
上面各类扫描方式由快到慢:
system > const > eq_ref > ref > range > index > ALL
下面一一举例说明。
一、system

explain select * from mysql.time_zone;
上例中,从系统库mysql的系统表time_zone里查询数据,扫码类型为system,这些数据已经加载到内存里,不需要进行磁盘IO。
这类扫描是速度最快的。

explain select * from (select * from user where id=1) tmp;
再举一个例子,内层嵌套(const)返回了一个临时表,外层嵌套从临时表查询,其扫描类型也是system,也不需要走磁盘IO,速度超快。
二、const
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');

const扫描的条件为:
(1)命中主键(primary key)或者唯一(unique)索引;
(2)被连接的部分是一个常量(const)值;
explain select * from user where id=1;
如上例,id是PK,连接部分是常量1。
画外音:别搞什么类型转换的幺蛾子。
这类扫描效率极高,返回数据量少,速度非常快。
三、eq_ref
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
create table user_ex (
id int primary key,
age int
)engine=innodb;
insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);
eq_ref扫描的条件为,对于前表的每一行(row),后表只有一行被扫描。
再细化一点:
(1)join查询;
(2)命中主键(primary key)或者非空唯一(unique not null)索引;
(3)等值连接;
explain select * from user,user_ex where user.id=user_ex.id;
如上例,id是主键,该join查询为eq_ref扫描。
这类扫描的速度也异常之快。
四、ref
数据准备:
create table user (
id int,
name varchar(20) ,
index(id)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
create table user_ex (
id int,
age int,
index(id)
)engine=innodb;
insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);

如果把上例eq_ref案例中的主键索引,改为普通非唯一(non unique)索引。
explain select * from user,user_ex where user.id=user_ex.id;
就由eq_ref降级为了ref,此时对于前表的每一行(row),后表可能有多于一行的数据被扫描。

explain select * from user where id=1;
当id改为普通非唯一索引后,常量的连接查询,也由const降级为了ref,因为也可能有多于一行的数据被扫描。
ref扫描,可能出现在join里,也可能出现在单表普通索引里,每一次匹配可能有多行数据返回,虽然它比eq_ref要慢,但它仍然是一个很快的join类型。
五、range
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
insert into user values(4,'wangwu');
insert into user values(5,'zhaoliu');
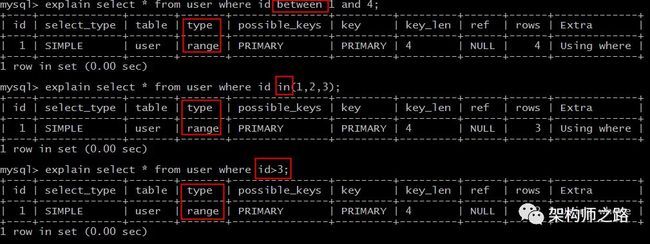
range扫描就比较好理解了,它是索引上的范围查询,它会在索引上扫码特定范围内的值。
explain select * from user where id between 1 and 4;
explain select * from user where idin(1,2,3);
explain select * from user where id>3;
像上例中的between,in,>都是典型的范围(range)查询。
画外音:必须是索引,否则不能批量"跳过"。
六、index

index类型,需要扫描索引上的全部数据。
explain count (*) from user;
如上例,id是主键,该count查询需要通过扫描索引上的全部数据来计数。
画外音:此表为InnoDB引擎。
它仅比全表扫描快一点。
七、ALL
数据准备:
create table user (
id int,
name varchar(20)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
create table user_ex (
id int,
age int
)engine=innodb;
insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);

explain select * from user,user_ex where user.id=user_ex.id;
如果id上不建索引,对于前表的每一行(row),后表都要被全表扫描。
今天这篇文章中,这个相同的join语句出现了三次:
(1)扫描类型为eq_ref,此时id为主键;
(2)扫描类型为ref,此时id为非唯一普通索引;
(3)扫描类型为ALL,全表扫描,此时id上无索引;
2.Extra字段
explain结果中还有一个Extra字段,对分析与优化SQL有很大的帮助,今天花1分钟简单和大家聊一聊。
数据准备:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
insert into user values(1, 'shenjian','no');
insert into user values(2, 'zhangsan','no');
insert into user values(3, 'lisi', 'yes');
insert into user values(4, 'lisi', 'no');
数据说明:
用户表:id主键索引,name普通索引(非唯一),sex无索引;
四行记录:其中name普通索引存在重复记录lisi;
实验目的:
通过构造各类SQL语句,对explain的Extra字段进行说明,启发式定位待优化低性能SQL语句。
一、【Using where】
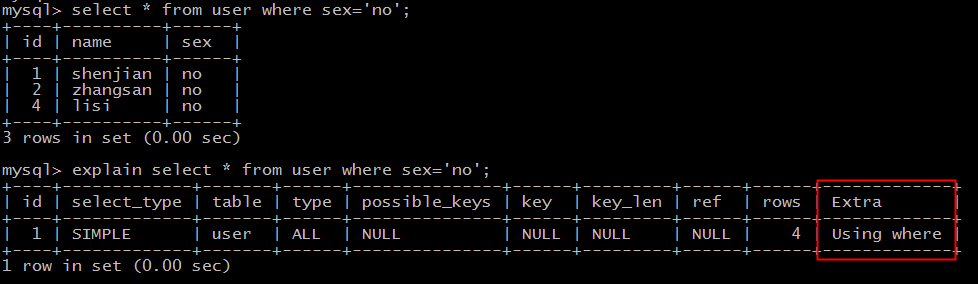
实验语句:
explain select * from user where sex='no';
结果说明:
Extra为Using where说明,SQL使用了where条件过滤数据。
需要注意的是:
(1)返回所有记录的SQL,不使用where条件过滤数据,大概率不符合预期,对于这类SQL往往需要进行优化;
(2)使用了where条件的SQL,并不代表不需要优化,往往需要配合explain结果中的type(连接类型)来综合判断;
画外音:join type在《同一个SQL语句,为啥性能差异咋就这么大呢?》一文中有详细叙述,本文不再展开。
本例虽然Extra字段说明使用了where条件过滤,但type属性是ALL,表示需要扫描全部数据,仍有优化空间。
常见的优化方法为,在where过滤属性上添加索引。
画外音:本例中,sex字段区分度不高,添加索引对性能提升有限。
二、【Using index】
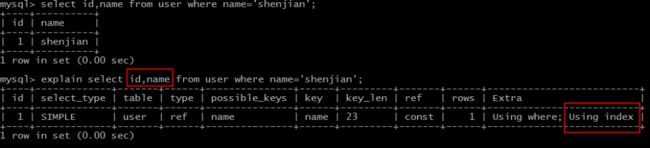
实验语句:
explain select id,name from user where name='shenjian';
结果说明:
Extra为Using index说明,SQL所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录。
画外音:The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row.
这类SQL语句往往性能较好。
官网说明:
仅使用索引树中的信息从表中检索列信息,而不必进行其他查找以读取实际行。当查询仅使用属于单个索引的列时,可以使用此策略。
问题来了,什么样的列数据,会包含在索引树上呢?
三、【Using index condition】

实验语句:
explain select id,name,sex from user
where name='shenjian';
画外音:该SQL语句与上一个SQL语句不同的地方在于,被查询的列,多了一个sex字段。
结果说明:
Extra为Using index condition说明,确实命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录。
画外音:聚集索引,普通索引的底层实现差异,详见《1分钟了解MyISAM与InnoDB的索引差异》。
这类SQL语句性能也较高,但不如Using index。
官网说明:
通过访问索引元组并首先对其进行测试以确定是否读取完整的表行来读取表。这样,除非有必要,否则索引信息将用于延迟(“ 下推 ”)读取整个表行。
问题来了,如何优化为Using index呢?
四、【Using filesort】
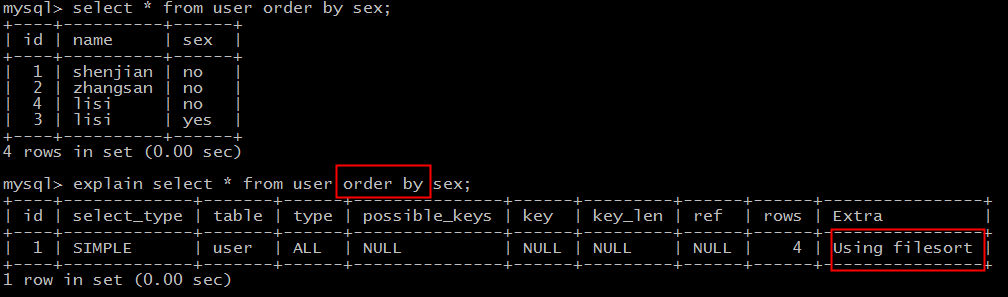
实验语句:
explain select * from user order by sex;
结果说明:
Extra为Using filesort说明,得到所需结果集,需要对所有记录进行文件排序。
也可以是用 order by null 告诉mysql不需要排序
这类SQL语句性能极差,需要进行优化。
典型的,在一个没有建立索引的列上进行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,避免每次查询都全量排序。
官网说明:
MySQL必须额外进行一遍,以找出如何按排序顺序检索行。排序是通过根据联接类型遍历所有行并存储与该WHERE子句匹配的所有行的排序键和指向该行的指针来完成的。然后对键进行排序,并按排序顺序检索行
五、【Using temporary】
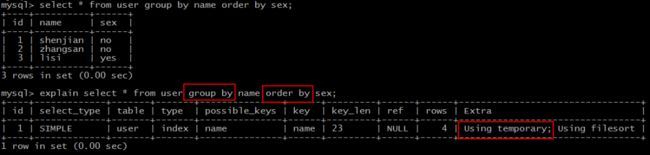
实验语句:
explain select * from user group by name order by sex;
结果说明:
Extra为Using temporary说明,需要建立临时表(temporary table)来暂存中间结果。
这类SQL语句性能较低,往往也需要进行优化。
典型的,group by和order by同时存在,且作用于不同的字段时,就会建立临时表,以便计算出最终的结果集。
官网说明:
为了解决该查询,MySQL需要创建一个临时表来保存结果。如果查询包含GROUP BY和 ORDER BY子句以不同的方式列出列,通常会发生这种情况
六、【Using join buffer (Block Nested Loop)】

实验语句:
explain select * from user where id in(select id from user where sex='no');
结果说明:
Extra为Using join buffer (Block Nested Loop)说明,需要进行嵌套循环计算。
画外音:内层和外层的type均为ALL,rows均为4,需要循环进行4*4次计算。
这类SQL语句性能往往也较低,需要进行优化。
典型的,两个关联表join,关联字段均未建立索引,就会出现这种情况。常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。
结尾:
explain是SQL优化中最常用的工具,搞定type和Extra,explain也就基本搞定了