手把手教你使用Python网络爬虫获取菜谱信息
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
一腔热血勤珍重,洒去犹能化碧涛。
/1 前言/
在放假时 ,经常想尝试一下自己做饭,下厨房这个网址是个不错的选择。
下厨房是必选的网址之一,主要提供各种美食做法以及烹饪技巧。包含种类很多。
今天教大家去爬取下厨房的菜谱 ,保存在world文档,方便日后制作自己的小菜谱。
/2 项目目标/
获取菜谱,并批量把菜 名、 原 料 、下 载 链 接 、下载保存在world文档。
/3 项目准备/
软件:PyCharm
需要的库:requests、lxml、fake_useragent、time
网站如下:
https://www.xiachufang.com/explore/?page={}
点击下一页时,每增加一页page自增加1,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。
/4 反爬措施的处理/
主要有两个点需要注意:
1、直接使用requests库,在不设置任何header的情况下,网站直接不返回数据
2、同一个ip连续访问多次,直接封掉ip,起初我的ip就是这样被封掉的。
为了解决这两个问题,最后经过研究,使用以下方法,可以有效解决。
1)获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。
2)使用 fake_useragent ,产生随机的UserAgent进行访问。
/5 项目实现/
1、定义一个class类继承object,定义init方法继承self,主函数main继承self。导入需要的库和网址,代码如下所示。
import requests
from lxml import etree
from fake_useragent import UserAgent
import time
class kitchen(object):
def __init__(self):
self.url = "https://www.xiachufang.com/explore/?page={}"
def main(self):
pass
if __name__ == '__main__':
imageSpider = kitchen()
imageSpider.main()
2、随机产生UserAgent。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求 获取响应, 页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、xpath解析一级页面数据,获取二级页面网址。
def parse_page(self, html):
parse_html = etree.HTML(html)
image_src_list = parse_html.xpath('//li/div/a/@href')
5、for遍历,定义一个变量food_info保存,获取到二级页面对应的菜 名、 原 料 、下 载 链 接。
for i in image_src_list:
url = "https://www.xiachufang.com/" + i
# print(url)
html1 = self.get_page(url) # 第二个发生请求
parse_html1 = etree.HTML(html1)
# print(parse_html1)
num = parse_html1.xpath('.//h2[@id="steps"]/text()')[0].strip()
name = parse_html1.xpath('.//li[@class="container"]/p/text()')
ingredients = parse_html1.xpath('.//td//a/text()')
food_info = '''
第 %s 种
菜 名 : %s
原 料 : %s
下 载 链 接 : %s,
=================================================================
''' % (str(self.u), num, ingredients, url)
6、保存在world文档 。
f = open('下厨房/菜谱.doc', 'a', encoding='utf-8') # 以'w'方式打开文件
f.write(str(food_info))
f.close()
7、调用方法,实现功能。
html = self.get_page(url)
self.parse_page(html)
8、项目优化
1)方法一:设置时间延时。
time.sleep(1.4)
2)方法二:定义一个变量u,for遍历,表示爬取的是第几种食物。(更清晰可观)。
u = 0
self.u += 1;
/6 效果展示/
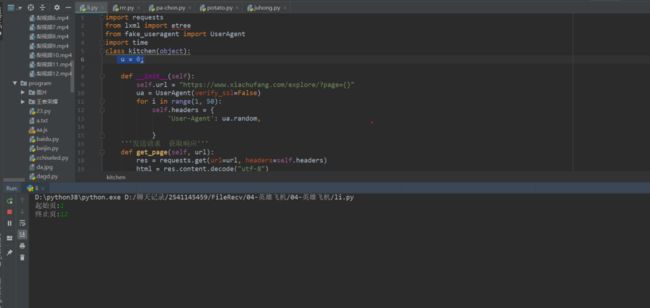
1、点击绿色小三角运行输入起始页,终止页。
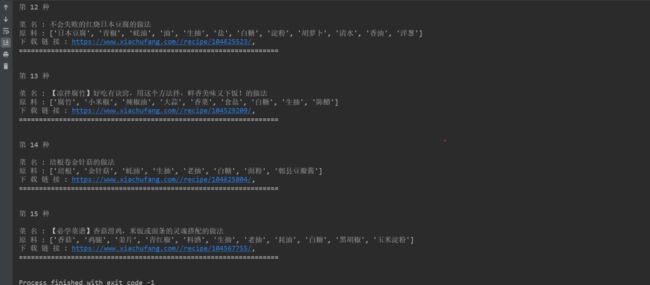
2、运行程序后,结果显示在控制台,如下图所示。
3、将运行结果保存在world文档中,如下图所示。

4、双击文件,内容如下图所示。

/7 小结/
1、本文章基于Python网络爬虫,获取下厨房网站菜谱信息,在应用中出现的难点和重点,以及如何防止反爬,做出了相对于的解决方案。
2、介绍了如何去拼接字符串,以及列表如何进行类型的转换。
3、代码很简单,希望能够帮到你。
4、欢迎大家积极尝试,有时候看到别人实现起来很简单,但是到自己动手实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。
5、可以选择自己喜欢的分类,获取自己喜欢的菜谱,每个人都是厨师。
6、如果需要本文源码的话,请在公众号后台回复“厨房”两个字进行获取,觉得不错,记得给个star噢。
------------------- End -------------------
往期精彩文章推荐:
手把手用Python教你如何发现隐藏wifi
手把手教你用Python做个可视化的“剪刀石头布”小游戏
手把手教你使用Python批量创建复工证明

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两个您使用过的Python库~~