一、前言
目前做Android开发在网络框架上,大公司一般都维护着有自己的网络框架,而一般的应用都在使用Volley或者OkHttp,或者封装了OkHttp的Retrofit,那么为何还要来分析Android自带的网络框架呢。当然,Android大部分是来自于Java本身的库,只不过针对移动端做了更改和简化。自带网络框架虽然被大家所诟病,但其实是复杂的,庞大的,很多情况下都是非常贴近 HTTP 协议以及TCP/IP协议的。所谓越原始往往越接近真相。整个分析下来相信会有不错的收获。原生框架是一份不错的学习资料。
这里的Android原生网络框架的分析是基于 4.3 的,想必了解的人都知道了。Android从4.4开始就引入OkHttp但还不是作为唯一底层框架,而在5.0之后完全以OkHttp为底层网络框架了。
原生的网络框架有好几个包,关系上看起来有乱:
java.net:主要就是简单的HTTP协议实现,包括URL,HttpUrlConnection等,也是最基础的部分
java.security:安全相关,Http协议的实现,证书校验等
javax.crypto:加解密相关
javax.net:主要有 ssl 相关
javax.security: 也是安全相关的。与 **java.security **有什么关系呢?又有什么不同呢?各自负责的职责是什么?
ibcore.net:算是网络库的中间层封装
org.apache.harmony.xnet.provider.jsse: apache的包?有什么用?
这些是否有内在联系?带着这些疑问,开始Android原生网络库的分析之旅吧。
还是以网络连接、通信与断开为线索进行分析。
二、Http连接
1.示例
先来看一段官方通信示例代码。
// 1.打开 URLConnection
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
try {
// 2.设置参数
urlConnection.setDoOutput(true);
urlConnection.setChunkedStreamingMode(0);
// 3.获取输出流
OutputStream out = new BufferedOutputStream(urlConnection.getOutputStream());
// 4.写入参数
writeStream(out);
// 5.获取读入流
InputStream in = new BufferedInputStream(urlConnection.getInputStream());
// 6.读取数据
readStream(in);
} finally {
// 7.断开连接
urlConnection.disconnect();
}
代码很简单,但如注释时所述,共分了7个小步骤。但代码虽然短,可这里却有不少的疑问:
(1)可以注意到有disconnect()调用,但却没有connect()调用。那么openConnection()发起了真正的网络连接了吗?到底什么时候执行的TCP三次握手呢?
(2)disconnect()调用后,底层的TCP执行了4次挥手协议了吗?
带着这些疑问,先从 openConnection()看起吧。
2.openConnection()打开连接
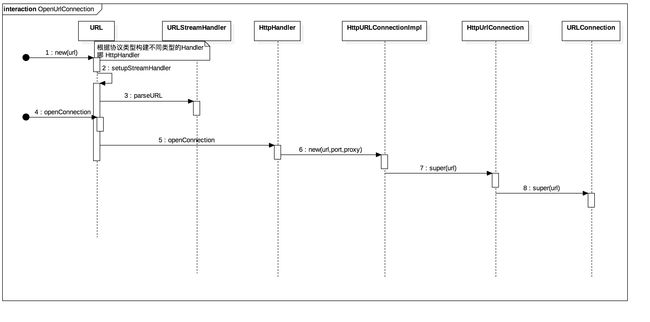
URL的构建函数重载的比较多,这里只是简单传入一个url,最终会调用到如下这个版本的构建函数。
public URL(URL context, String spec, URLStreamHandler handler) throws MalformedURLException {
153 if (spec == null) {
154 throw new MalformedURLException();
155 }
156 if (handler != null) {
157 streamHandler = handler;
158 }
159 spec = spec.trim();
160 // 1.先解析出协议头,确定协议
161 protocol = UrlUtils.getSchemePrefix(spec);
162 int schemeSpecificPartStart = protocol != null ? (protocol.length() + 1) : 0;
163
164 // If the context URL has a different protocol, discard it because we can't use it.
165 if (protocol != null && context != null && !protocol.equals(context.protocol)) {
166 context = null;
167 }
168
169 // Inherit from the context URL if it exists.
170 if (context != null) {
171 set(context.protocol, context.getHost(), context.getPort(), context.getAuthority(),
172 context.getUserInfo(), context.getPath(), context.getQuery(),
173 context.getRef());
174 if (streamHandler == null) {
175 streamHandler = context.streamHandler;
176 }
177 } else if (protocol == null) {
178 throw new MalformedURLException("Protocol not found: " + spec);
179 }
180
181 if (streamHandler == null) {
// 2.关键调用。根据协议设置用来干活的 Handler
182 setupStreamHandler();
183 if (streamHandler == null) {
184 throw new MalformedURLException("Unknown protocol: " + protocol);
185 }
186 }
187
188 // Parse the URL. If the handler throws any exception, throw MalformedURLException instead.
189 try { // 解析url的全部部分,handler解析完成后,最后会通过URL#set()方法将port,filepath,userinfo等都传回来的
190 streamHandler.parseURL(this, spec, schemeSpecificPartStart, spec.length());
191 } catch (Exception e) {
192 throw new MalformedURLException(e.toString());
193 }
194 }
如代码中的关键注释,构建函数的主要作用是确定协议,端口,文件路径,以用于处理实际事务的handler。这里就假设就是HTTP协议,那么其确定下来的Handler就是HttpHandler.
URLStreamHandler是一个抽象类,HttpHandler是其子类。parseURL这类公共操作在父类URLStreamHandler中完成,openConnection()因为会发生不同的行为,所以其在子类HttpHandler中完成。
public URLConnection openConnection() throws IOException {
471 return streamHandler.openConnection(this);
472 }
URL#openConnection()非常简单就是进一步调用相应Handler的openConnection(),这里调用的是HttpHandler#openConnection()
@Override protected URLConnection openConnection(URL url, Proxy proxy) throws IOException {
33 if (url == null || proxy == null) {
34 throw new IllegalArgumentException("url == null || proxy == null");
35 }
36 return new HttpURLConnectionImpl(url, getDefaultPort(), proxy);
37 }
这里最终构建了一个具体的实现类HttpURLConnectionImpl,它继承自HttpURLConnection,而HttpURLConnection又继承自URLConnection。构建函数并没有做什么特殊的事情,而是一级一级将url向父类传递直到URLConnection,并最终记录在URLConnection。同时这里还有一个需要提一下的是,这里还确定了默认端口为 80。
3.参数设置
setDoOutput(),setChunkedStreamingMode(),setDoInput()等这些只是设置一些参数,也并没有真正发起网络请求。稍微提一下setChunkedStreamingMode(),用来设置body的分块大小,系统建议默认值,即为 1024。
除了这些基础的参数可以进行设置,还一个关键的HTTP的request header参数的添加。
@Override public final void addRequestProperty(String field, String value) {
511 if (connected) {
512 throw new IllegalStateException("Cannot add request property after connection is made");
513 }
514 if (field == null) {
515 throw new NullPointerException("field == null");
516 }
517 rawRequestHeaders.add(field, value);
518 }
添加的field-value(通常描述是key-value)会被记录到rawRequestHeaders中,它所属的类是RawHeaders。另外一个要注意的是,它必须在连接之前就设置好,否则会引发异常。那么什么时候进行连接的呢,进一步看getOutputStream吧。
4.getOutputStream
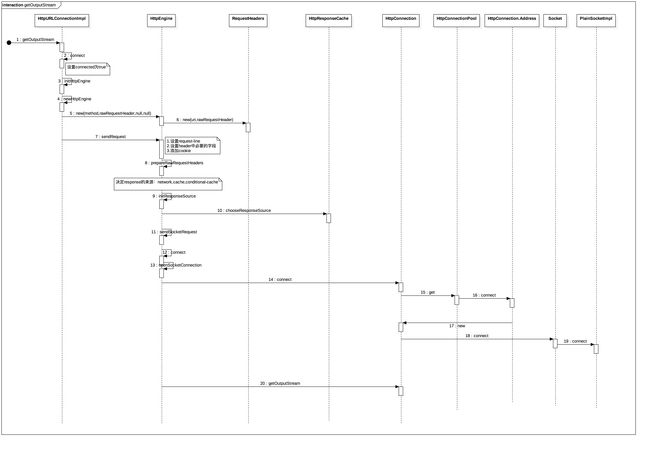
过程有点长,画的也有点细,分了20步,需要耐着点性子看,不要畏难也不要怕麻烦,其实挺简单的。
下面还是来分步骤更详细的了解其是如何建立起连接的。
@Override public final OutputStream getOutputStream() throws IOException {
197 connect();
198
199 OutputStream result = httpEngine.getRequestBody();
200 if (result == null) {
201 throw new ProtocolException("method does not support a request body: " + method);
202 } else if (httpEngine.hasResponse()) {
203 throw new ProtocolException("cannot write request body after response has been read");
204 }
205
206 return result;
207 }
根据前面的分析,getOutputStream调用的是HttpURLConnectionImpl的方法。在这里调用了内部方法 connect()
78 @Override public final void connect() throws IOException {
79 initHttpEngine();
80 try {
81 httpEngine.sendRequest();
82 } catch (IOException e) {
83 httpEngineFailure = e;
84 throw e;
85 }
86 }
这里仅有两个关键调用,initHttpEngine()以及httpEngine.sendRequest()先来看initHttpEngine()方法。
private void initHttpEngine() throws IOException {
235 if (httpEngineFailure != null) {
236 throw httpEngineFailure;
237 } else if (httpEngine != null) {
238 return;
239 }
240 // 记录 connected 状态为 true,记住不能再设置/添加Header参数了
241 connected = true;
242 try {
243 if (doOutput) { // 设置了 doOutput 且为 GET 方法的会被自动校正为 POST方法
244 if (method == HttpEngine.GET) {
245 // they are requesting a stream to write to. This implies a POST method
246 method = HttpEngine.POST;
247 } else if (method != HttpEngine.POST && method != HttpEngine.PUT) {
248 // If the request method is neither POST nor PUT, then you're not writing
249 throw new ProtocolException(method + " does not support writing");
250 }
251 }
// 该方法的关键,调用 newHttpEngine()
252 httpEngine = newHttpEngine(method, rawRequestHeaders, null, null);
253 } catch (IOException e) {
254 httpEngineFailure = e;
255 throw e;
256 }
257 }
这里的关键是记录了connected状态以及进一步调用 newHttpEngine()方法初始化HttpEngine实例。
259 /**
260 * Create a new HTTP engine. This hook method is non-final so it can be
261 * overridden by HttpsURLConnectionImpl.
262 */
263 protected HttpEngine newHttpEngine(String method, RawHeaders requestHeaders,
264 HttpConnection connection, RetryableOutputStream requestBody) throws IOException {
265 return new HttpEngine(this, method, requestHeaders, connection, requestBody);
266 }
newHttpEngine是一个可重载的方法,不同协议会有自己的 Engine。这里仅仅是构建了一个HttpEngine的具体对象实例,另外需要注意的关键点是 connection 是传入的 null。继续看 HttpEngine的构建函数。
187 public HttpEngine(HttpURLConnectionImpl policy, String method, RawHeaders requestHeaders,
188 HttpConnection connection, RetryableOutputStream requestBodyOut) throws IOException {
189 this.policy = policy;
190 this.method = method;
191 this.connection = connection;
192 this.requestBodyOut = requestBodyOut;
193
194 try {
195 uri = policy.getURL().toURILenient();
196 } catch (URISyntaxException e) {
197 throw new IOException(e);
198 }
199
200 this.requestHeaders = new RequestHeaders(uri, new RawHeaders(requestHeaders));
201 }
构建函数只是简单的记录相应的参数。但这里有几个重要的类是需要关注一下的,下面说说几个重要的类。
HttpEngine
它在这里是一个管理类,HTTP等协议相关的如发起连接,获取结果,断开连接等都通过该类来完成。此外,还有一个最重要的任务也是在这里完成,即生成请求行以及包装请求头,都在这里完成。
RequestHeaders、RawHeaders
RawHeaders记录的是比较原始的数据,如协议版本号,请求行以及请求Header参数的fieldname-value。可以看成就是个暂时记录数据的地方。
RequestHeaders是对RawHeaders的进一步解析,也是HTTP协议相关的。来看看其构造函数。
public RequestHeaders(URI uri, RawHeaders headers) {
65 this.uri = uri;
66 this.headers = headers;
67
68 HeaderParser.CacheControlHandler handler = new HeaderParser.CacheControlHandler() {
69 @Override public void handle(String directive, String parameter) {
70 if (directive.equalsIgnoreCase("no-cache")) {
71 noCache = true;
72 } else if (directive.equalsIgnoreCase("max-age")) {
73 maxAgeSeconds = HeaderParser.parseSeconds(parameter);
74 } else if (directive.equalsIgnoreCase("max-stale")) {
75 maxStaleSeconds = HeaderParser.parseSeconds(parameter);
76 } else if (directive.equalsIgnoreCase("min-fresh")) {
77 minFreshSeconds = HeaderParser.parseSeconds(parameter);
78 } else if (directive.equalsIgnoreCase("only-if-cached")) {
79 onlyIfCached = true;
80 }
81 }
82 };
83
84 for (int i = 0; i < headers.length(); i++) {
85 String fieldName = headers.getFieldName(i);
86 String value = headers.getValue(i);
87 if ("Cache-Control".equalsIgnoreCase(fieldName)) {
88 HeaderParser.parseCacheControl(value, handler);
89 } else if ("Pragma".equalsIgnoreCase(fieldName)) {
90 if (value.equalsIgnoreCase("no-cache")) {
91 noCache = true;
92 }
93 } else if ("If-None-Match".equalsIgnoreCase(fieldName)) {
94 ifNoneMatch = value;
95 } else if ("If-Modified-Since".equalsIgnoreCase(fieldName)) {
96 ifModifiedSince = value;
97 } else if ("Authorization".equalsIgnoreCase(fieldName)) {
98 hasAuthorization = true;
99 } else if ("Content-Length".equalsIgnoreCase(fieldName)) {
100 try {
101 contentLength = Integer.parseInt(value);
102 } catch (NumberFormatException ignored) {
103 }
104 } else if ("Transfer-Encoding".equalsIgnoreCase(fieldName)) {
105 transferEncoding = value;
106 } else if ("User-Agent".equalsIgnoreCase(fieldName)) {
107 userAgent = value;
108 } else if ("Host".equalsIgnoreCase(fieldName)) {
109 host = value;
110 } else if ("Connection".equalsIgnoreCase(fieldName)) {
111 connection = value;
112 } else if ("Accept-Encoding".equalsIgnoreCase(fieldName)) {
113 acceptEncoding = value;
114 } else if ("Content-Type".equalsIgnoreCase(fieldName)) {
115 contentType = value;
116 } else if ("Proxy-Authorization".equalsIgnoreCase(fieldName)) {
117 proxyAuthorization = value;
118 }
119 }
120 }
非常的长,但不要畏难或者被吓到。其实就是解析RawHeader中的Header字段,说白了就是处理数据,只不过处理的协议头的参数罢了。
到这里,终于构建好了 HttpEngine 类了,Header的参数也解析好了。下面就可以发请求了。好,来看 HttpEngine#sendRequest()。
207 /**
208 * Figures out what the response source will be, and opens a socket to that
209 * source if necessary. Prepares the request headers and gets ready to start
210 * writing the request body if it exists.
211 */
212 public final void sendRequest() throws IOException {
213 if (responseSource != null) {
214 return;
215 }
216 //1. 准备请求头的参数
217 prepareRawRequestHeaders();
// 2.初始化响应资源
218 initResponseSource();
219 if (responseCache instanceof ExtendedResponseCache) {
220 ((ExtendedResponseCache) responseCache).trackResponse(responseSource);
221 }
222
223 /*
224 * The raw response source may require the network, but the request
225 * headers may forbid network use. In that case, dispose of the network
226 * response and use a GATEWAY_TIMEOUT response instead, as specified
227 * by http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9.4.
228 */
229 if (requestHeaders.isOnlyIfCached() && responseSource.requiresConnection()) {
230 if (responseSource == ResponseSource.CONDITIONAL_CACHE) {
231 IoUtils.closeQuietly(cachedResponseBody);
232 }
233 this.responseSource = ResponseSource.CACHE;
234 this.cacheResponse = GATEWAY_TIMEOUT_RESPONSE;
235 RawHeaders rawResponseHeaders = RawHeaders.fromMultimap(cacheResponse.getHeaders());
236 setResponse(new ResponseHeaders(uri, rawResponseHeaders), cacheResponse.getBody());
237 }
238
239 if (responseSource.requiresConnection()) {
// 3.发起 socket 请求
240 sendSocketRequest();
241 } else if (connection != null) {
242 HttpConnectionPool.INSTANCE.recycle(connection);
243 connection = null;
244 }
245 }
这里有三个的关键调用,在注释中有描述。下面一个一个来看吧。先看 prepareRawRequestHeaders()方法。
prepareRawRequestHeaders()
693 /**
694 * Populates requestHeaders with defaults and cookies.
695 *
696 * This client doesn't specify a default {@code Accept} header because it
697 * doesn't know what content types the application is interested in.
698 */
699 private void prepareRawRequestHeaders() throws IOException {
700 requestHeaders.getHeaders().setStatusLine(getRequestLine());
701
702 if (requestHeaders.getUserAgent() == null) {
703 requestHeaders.setUserAgent(getDefaultUserAgent());
704 }
705
706 if (requestHeaders.getHost() == null) {
707 requestHeaders.setHost(getOriginAddress(policy.getURL()));
708 }
709
710 if (httpMinorVersion > 0 && requestHeaders.getConnection() == null) {
711 requestHeaders.setConnection("Keep-Alive");
712 }
713
714 if (requestHeaders.getAcceptEncoding() == null) {
715 transparentGzip = true;
716 requestHeaders.setAcceptEncoding("gzip");
717 }
718
719 if (hasRequestBody() && requestHeaders.getContentType() == null) {
720 requestHeaders.setContentType("application/x-www-form-urlencoded");
721 }
722
723 long ifModifiedSince = policy.getIfModifiedSince();
724 if (ifModifiedSince != 0) {
725 requestHeaders.setIfModifiedSince(new Date(ifModifiedSince));
726 }
727
728 CookieHandler cookieHandler = CookieHandler.getDefault();
729 if (cookieHandler != null) {
730 requestHeaders.addCookies(
731 cookieHandler.get(uri, requestHeaders.getHeaders().toMultimap()));
732 }
733 }
这里设置了请求行:如 GET url HTTP/1.1,设置UA,设置Host,设置 Connection 为 keep-alive,设置 accept-encoding 为gzip。设置 content-type 为 "application/x-www-form-urlencoded",设置 if-Modified-Since,添加发送给服务器的 cookie。
准备好了请求参数,下面来看一看initResponseSource()方法。
initResponseSource
private void initResponseSource() throws IOException {
// 默认为是从网络获取
252 responseSource = ResponseSource.NETWORK;
253 if (!policy.getUseCaches() || responseCache == null) {
254 return;
255 }
256 // 查看是否有缓存
257 CacheResponse candidate = responseCache.get(uri, method,
258 requestHeaders.getHeaders().toMultimap());
259 if (candidate == null) {
260 return;
261 }
262 // 有缓存的情况下取出响Header与body
263 Map> responseHeadersMap = candidate.getHeaders();
264 cachedResponseBody = candidate.getBody();
// 对于不接受的缓存类型直接关掉被返回
265 if (!acceptCacheResponseType(candidate)
266 || responseHeadersMap == null
267 || cachedResponseBody == null) {
268 IoUtils.closeQuietly(cachedResponseBody);
269 return;
270 }
271 // 缓存可接受,从responseHeadersMap解析出RawHeaders,这个类在上面的分析中已经讲过了。现在看来它也同时用于记录 Response 的 Header
272 RawHeaders rawResponseHeaders = RawHeaders.fromMultimap(responseHeadersMap);
// 构建 ResponseHeaders
273 cachedResponseHeaders = new ResponseHeaders(uri, rawResponseHeaders);
274 long now = System.currentTimeMillis();
// 最后的 response 的实际来源
275 this.responseSource = cachedResponseHeaders.chooseResponseSource(now, requestHeaders);
276 if (responseSource == ResponseSource.CACHE) {//如果是cache,把刚才的 request 以及 response 包装成Response,这也是要返回给上层用户的结果。
277 this.cacheResponse = candidate;
278 setResponse(cachedResponseHeaders, cachedResponseBody);
279 } else if (responseSource == ResponseSource.CONDITIONAL_CACHE) {//条件缓存
280 this.cacheResponse = candidate;
281 } else if (responseSource == ResponseSource.NETWORK) {//网络则直接关闭缓存
282 IoUtils.closeQuietly(cachedResponseBody);
283 } else {
284 throw new AssertionError();
285 }
286 }
287
initResponseSource的主要作用决定请求的结果是由哪里来的。共有三种情况:网络,缓存,条件缓存。网络没什么好解释的,缓存被禁用或者没有自然就是要发起网络请了。
缓存,相应的类是ResponseCache,这是一个接口,其具体的子类为HttpResponseCache。关于这个类的细节实现没有必要再进一步分析,因为其和Volley还算比较深入的分析中的缓存差不太多,缓存算法也是 DiskLruCache,但这里的key有点差别,用的是 url 的md5编码,既安全又节省资源大小。
条件缓存,与Http协议的缓存密切相关。在chooseResponseSource()中最后会根据request的请求头参数来确定是否为条件缓存。
280 public boolean hasConditions() {
281 return ifModifiedSince != null || ifNoneMatch != null;
282 }
而它们所对应的字段就是"If-None-Match"和"If-Modified-Since"。
假设缓存里没有吧,那就要发起真正的网络请了。来看看 sendSocketRequest()方法。
sendSocketRequest
private void sendSocketRequest() throws IOException {
289 if (connection == null) {
290 connect();
291 }
292
293 if (socketOut != null || requestOut != null || socketIn != null) {
294 throw new IllegalStateException();
295 }
296
297 socketOut = connection.getOutputStream();
298 requestOut = socketOut;
299 socketIn = connection.getInputStream();
300
301 if (hasRequestBody()) {
302 initRequestBodyOut();
303 }
304 }
这里以 connection 来决定是否要发起内部的 connect()。connection是 HttpConnection的实例。进一步看看connect()的代码。
309 protected void connect() throws IOException {
310 if (connection == null) {
311 connection = openSocketConnection();
312 }
313 }
比较简单,进一步调用了 openSocketConnection()来构建一个 connection。
315 protected final HttpConnection openSocketConnection() throws IOException {
316 HttpConnection result = HttpConnection.connect(uri, getSslSocketFactory(),
317 policy.getProxy(), requiresTunnel(), policy.getConnectTimeout());
318 Proxy proxy = result.getAddress().getProxy();
319 if (proxy != null) {
320 policy.setProxy(proxy);
321 }
322 result.setSoTimeout(policy.getReadTimeout());
323 return result;
324 }
进一步调用HttpConnection的静态方法connect()来创建 HttpConnection。
public static HttpConnection connect(URI uri, SSLSocketFactory sslSocketFactory,
90 Proxy proxy, boolean requiresTunnel, int connectTimeout) throws IOException {
91 /*
92 * Try an explicitly-specified proxy.
93 */
94 if (proxy != null) {
95 Address address = (proxy.type() == Proxy.Type.DIRECT)
96 ? new Address(uri, sslSocketFactory)
97 : new Address(uri, sslSocketFactory, proxy, requiresTunnel);
98 return HttpConnectionPool.INSTANCE.get(address, connectTimeout);
99 }
100
101 /*
102 * Try connecting to each of the proxies provided by the ProxySelector
103 * until a connection succeeds.
104 */
105 ProxySelector selector = ProxySelector.getDefault();
106 List proxyList = selector.select(uri);
107 if (proxyList != null) {
108 for (Proxy selectedProxy : proxyList) {
109 if (selectedProxy.type() == Proxy.Type.DIRECT) {
110 // the same as NO_PROXY
111 // TODO: if the selector recommends a direct connection, attempt that?
112 continue;
113 }
114 try {
115 Address address = new Address(uri, sslSocketFactory,
116 selectedProxy, requiresTunnel);
117 return HttpConnectionPool.INSTANCE.get(address, connectTimeout);
118 } catch (IOException e) {
119 // failed to connect, tell it to the selector
120 selector.connectFailed(uri, selectedProxy.address(), e);
121 }
122 }
123 }
124
125 /*
126 * Try a direct connection. If this fails, this method will throw.
127 */
128 return HttpConnectionPool.INSTANCE.get(new Address(uri, sslSocketFactory), connectTimeout);
129 }
这一堆的代码,前面都是设置代理的,不管它。真正管用的是最后一句HttpConnectionPool.INSTANCE#get()。即从HttpConnectionPool里返回一个HttpConnection。补充一点,INSTANCE代表着HttpConnectionPool对象本身,其实现为一个单例类。进一步看看是如何 Get 的吧。
public HttpConnection get(HttpConnection.Address address, int connectTimeout)
64 throws IOException {
65 // First try to reuse an existing HTTP connection.
66 synchronized (connectionPool) {
67 List connections = connectionPool.get(address);
68 while (connections != null) {
69 HttpConnection connection = connections.remove(connections.size() - 1);
70 if (connections.isEmpty()) {
71 connectionPool.remove(address);
72 connections = null;
73 }
74 if (connection.isEligibleForRecycling()) {
75 // Since Socket is recycled, re-tag before using
76 Socket socket = connection.getSocket();
77 SocketTagger.get().tag(socket);
78 return connection;
79 }
80 }
81 }
82
83 /*
84 * We couldn't find a reusable connection, so we need to create a new
85 * connection. We're careful not to do so while holding a lock!
86 */
87 return address.connect(connectTimeout);
88 }
Get()是一个常见的缓存池的套路。先判断当前连接池里是否包含有同一Address的且没有被回收的连接,如果能找到就重新re-tag一下socket,再返回当前找到的HttpCoonection。如果没有找到就通过 address#connect()方法来创建一个。先不进行下一步来关注两个比较重要的点。
isEligibleForRecycling()方法的实现
248 /**
249 * Returns true if this connection is eligible to be reused for another
250 * request/response pair.
251 */
252 protected boolean isEligibleForRecycling() {
253 return !socket.isClosed()
254 && !socket.isInputShutdown()
255 && !socket.isOutputShutdown();
256 }
从代码中知道,未被回收的连接的判定条件是:socket未关闭,输入以及输出流未被关闭。
连接池的Key——Address
Address是HttpConnection的内部类。我们知道任何一个xx池之类的,都要有一个唯一的key用来判断是否为同一资源。这里使用Address对象,看起来有点奇怪。既然这么用了,那么它一定是重写了 equal()方法和hashcode()方法了。来看一看。
@Override public boolean equals(Object other) {
318 if (other instanceof Address) {
319 Address that = (Address) other;
320 return Objects.equal(this.proxy, that.proxy)
321 && this.uriHost.equals(that.uriHost)
322 && this.uriPort == that.uriPort
323 && Objects.equal(this.sslSocketFactory, that.sslSocketFactory)
324 && this.requiresTunnel == that.requiresTunnel;
325 }
326 return false;
327 }
328
329 @Override public int hashCode() {
330 int result = 17;
331 result = 31 * result + uriHost.hashCode();
332 result = 31 * result + uriPort;
333 result = 31 * result + (sslSocketFactory != null ? sslSocketFactory.hashCode() : 0);
334 result = 31 * result + (proxy != null ? proxy.hashCode() : 0);
335 result = 31 * result + (requiresTunnel ? 1 : 0);
336 return result;
337 }
果然是被重写了。从上面两个方法也可以看出,判断为同一Key,需要 host,port,sslfactory,proxy,tunel都是相等的才能算是同一key。
下面继续看HttpConnection是如何创建的以及创建完成后做了什么。前面有分析到,如果连接池里没有就会创建一个新的。而创建一个新的HttpConnection是通过HttpConnection的子类Address#connect()方法进行的。
public HttpConnection connect(int connectTimeout) throws IOException {
340 return new HttpConnection(this, connectTimeout);
341 }
挺简单的,直接new一个实例,那来看看HttpConnection的构建函数。
private HttpConnection(Address config, int connectTimeout) throws IOException {
62 this.address = config;
63
64 /*
65 * Try each of the host's addresses for best behavior in mixed IPv4/IPv6
66 * environments. See http://b/2876927
67 * TODO: add a hidden method so that Socket.tryAllAddresses can does this for us
68 */
69 Socket socketCandidate = null;
// 1.寻址,即通过 hostname查找 IP 地址,可能会查到多个。
70 InetAddress[] addresses = InetAddress.getAllByName(config.socketHost);
71 for (int i = 0; i < addresses.length; i++) {
//4. 创建用于执行TCP连接的套接字 Socket
72 socketCandidate = (config.proxy != null && config.proxy.type() != Proxy.Type.HTTP)
73 ? new Socket(config.proxy)
74 : new Socket();
75 try {
// 3. 发起套接字Socket的TCP请求连接
76 socketCandidate.connect(
77 new InetSocketAddress(addresses[i], config.socketPort), connectTimeout);
78 break;
79 } catch (IOException e) {
// 4.所有地址都试过了,弹尽粮绝了,报异常。
80 if (i == addresses.length - 1) {
81 throw e;
82 }
83 }
84 }
85
86 this.socket = socketCandidate;
87 }
虽然只是一个构造函数,但复杂度确不低,按照注释的步骤来详细的看一下。
寻址
调用的是InetAddress#getAllByName(),这是一个静态方法。
public static InetAddress[] getAllByName(String host) throws UnknownHostException {
214 return getAllByNameImpl(host).clone();
215 }
216
217 /**
218 * Returns the InetAddresses for {@code host}. The returned array is shared
219 * and must be cloned before it is returned to application code.
220 */
221 private static InetAddress[] getAllByNameImpl(String host) throws UnknownHostException {
// 为空则判定为回路地址,即 127.0.0.1
222 if (host == null || host.isEmpty()) {
223 return loopbackAddresses();
224 }
225
226 // Is it a numeric address?本身就是IP地址吗?是的话就不用继续找了。
227 InetAddress result = parseNumericAddressNoThrow(host);
228 if (result != null) {
229 result = disallowDeprecatedFormats(host, result);
230 if (result == null) {
231 throw new UnknownHostException("Deprecated IPv4 address format: " + host);
232 }
233 return new InetAddress[] { result };
234 }
235 // 前面的都不是,那就要进一步查找了。
236 return lookupHostByName(host).clone();
237 }
这里需要关注的是对内部方法lookupHostByName()的调用。
378 /**
379 * Resolves a hostname to its IP addresses using a cache.
380 *
381 * @param host the hostname to resolve.
382 * @return the IP addresses of the host.
383 */
384 private static InetAddress[] lookupHostByName(String host) throws UnknownHostException {
385 BlockGuard.getThreadPolicy().onNetwork();
386 // Do we have a result cached?
// 1.先从缓存里面找
387 Object cachedResult = addressCache.get(host);
388 if (cachedResult != null) {
389 if (cachedResult instanceof InetAddress[]) {
390 // A cached positive result.
391 return (InetAddress[]) cachedResult;
392 } else {
393 // A cached negative result.
394 throw new UnknownHostException((String) cachedResult);
395 }
396 }
397 try {
398 StructAddrinfo hints = new StructAddrinfo();
399 hints.ai_flags = AI_ADDRCONFIG;
400 hints.ai_family = AF_UNSPEC;
401 // If we don't specify a socket type, every address will appear twice, once
402 // for SOCK_STREAM and one for SOCK_DGRAM. Since we do not return the family
403 // anyway, just pick one.
// 2.缓存里面没有,调用native方法进一步查找。Libcore.os.getaddrinfo底层会发起DNS域名解析请求
404 hints.ai_socktype = SOCK_STREAM;
405 InetAddress[] addresses = Libcore.os.getaddrinfo(host, hints);
406 // TODO: should getaddrinfo set the hostname of the InetAddresses it returns?
407 for (InetAddress address : addresses) {
408 address.hostName = host;
409 }
410 addressCache.put(host, addresses);
411 return addresses;
412 } catch (GaiException gaiException) {
413 // If the failure appears to have been a lack of INTERNET permission, throw a clear
414 // SecurityException to aid in debugging this common mistake.
415 // http://code.google.com/p/android/issues/detail?id=15722
416 if (gaiException.getCause() instanceof ErrnoException) {
417 if (((ErrnoException) gaiException.getCause()).errno == EACCES) {
418 throw new SecurityException("Permission denied (missing INTERNET permission?)", gaiException);
419 }
420 }
421 // Otherwise, throw an UnknownHostException.
422 String detailMessage = "Unable to resolve host \"" + host + "\": " + Libcore.os.gai_strerror(gaiException.error);
423 addressCache.putUnknownHost(host, detailMessage);
424 throw gaiException.rethrowAsUnknownHostException(detailMessage);
425 }
426 }
寻址就是DNS域名解析,会先从缓存中查看是存在,如果没有则会由底层发起请求到DNS服务器来解析域名映射到实际用于通信的IP地址。
创建socket并发起TCP连接
Socket本身还只是一个包装类,它的connect()会继续调具体的实现类。由Socket的构造函数可知,它默认是PlainSocketImpl,也就是最后调用了它的connect()方法进行TCP连接。
56 this.impl = factory != null ? factory.createSocketImpl() : new PlainSocketImpl();
57 this.proxy = null;
58 }
到这里终于看到连接发出去了。原来构建一个HttpConnection就会发起TCP连接了。创建好了HttpConnection,方法就会原路返回,并最终返回输出流给到示例处调用 getOutputStream()的地方。
5.getInputStream()
getInputStream()与getOutputStream()的整个执行流程是大同小异的,有很多的共同部分,比如也可能发起网络连接,建立TCP的三次握手。
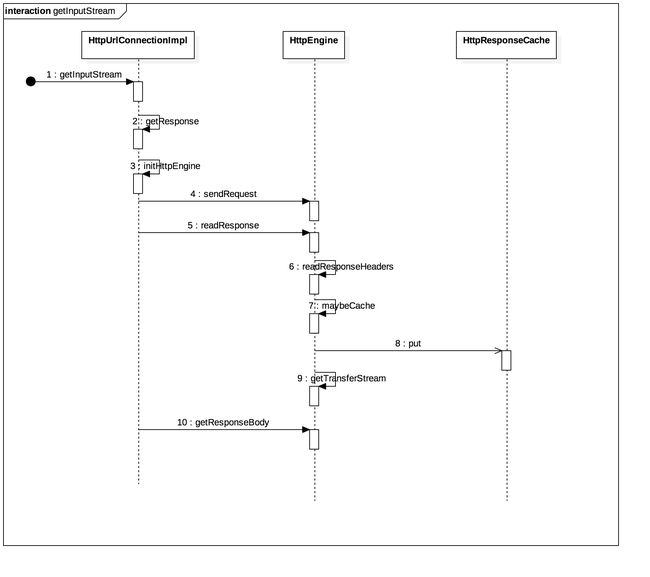
有了前面getOutputStream的基础,getInputStream就简单多了。
@Override public final InputStream getInputStream() throws IOException {
173 if (!doInput) {
174 throw new ProtocolException("This protocol does not support input");
175 }
176 // 获取 HttpEngine
177 HttpEngine response = getResponse();
178
179 /*
180 * if the requested file does not exist, throw an exception formerly the
181 * Error page from the server was returned if the requested file was
182 * text/html this has changed to return FileNotFoundException for all
183 * file types
184 */
185 if (getResponseCode() >= HTTP_BAD_REQUEST) {
186 throw new FileNotFoundException(url.toString());
187 }
188 // 从 HttpEngin 那里获取 InputStream
189 InputStream result = response.getResponseBody();
190 if (result == null) {
191 throw new IOException("No response body exists; responseCode=" + getResponseCode());
192 }
193 return result;
194 }
如注释第一步是获取HttpEngine,因为在getOutputStream阶段已经创建好了,所以不会再重新创建了,用现成的就好。第二步就是从HttpEngine那里拿到 response body。当然这里需要进一步分析的是 getResponse。
/**
269 * Aggressively tries to get the final HTTP response, potentially making
270 * many HTTP requests in the process in order to cope with redirects and
271 * authentication.
272 */
273 private HttpEngine getResponse() throws IOException {
274 initHttpEngine();
275
276 if (httpEngine.hasResponse()) {
277 return httpEngine;
278 }
279
280 while (true) {
281 try {
282 httpEngine.sendRequest();
283 httpEngine.readResponse();
284 } catch (IOException e) {
285 /*
286 * If the connection was recycled, its staleness may have caused
287 * the failure. Silently retry with a different connection.
288 */
289 OutputStream requestBody = httpEngine.getRequestBody();
290 if (httpEngine.hasRecycledConnection()
291 && (requestBody == null || requestBody instanceof RetryableOutputStream)) {
292 httpEngine.release(false);
293 httpEngine = newHttpEngine(method, rawRequestHeaders, null,
294 (RetryableOutputStream) requestBody);
295 continue;
296 }
297 httpEngineFailure = e;
298 throw e;
299 }
300 // 处理响应头,确定重试的策略。
301 Retry retry = processResponseHeaders();
302 if (retry == Retry.NONE) {
// 正常情况下不需要重试,因此这里也标记HttpConnection由HttpConnectionPool来自动释放。
303 httpEngine.automaticallyReleaseConnectionToPool();
304 return httpEngine;
305 }
306
307 /*
308 * The first request was insufficient. Prepare for another...
309 */
310 String retryMethod = method;
311 OutputStream requestBody = httpEngine.getRequestBody();
312
313 /*
314 * Although RFC 2616 10.3.2 specifies that a HTTP_MOVED_PERM
315 * redirect should keep the same method, Chrome, Firefox and the
316 * RI all issue GETs when following any redirect.
317 */
318 int responseCode = getResponseCode();
319 if (responseCode == HTTP_MULT_CHOICE || responseCode == HTTP_MOVED_PERM
320 || responseCode == HTTP_MOVED_TEMP || responseCode == HTTP_SEE_OTHER) {
321 retryMethod = HttpEngine.GET;
322 requestBody = null;
323 }
324
325 if (requestBody != null && !(requestBody instanceof RetryableOutputStream)) {
326 throw new HttpRetryException("Cannot retry streamed HTTP body",
327 httpEngine.getResponseCode());
328 }
329
330 if (retry == Retry.DIFFERENT_CONNECTION) {
331 httpEngine.automaticallyReleaseConnectionToPool();
332 } else {
333 httpEngine.markConnectionAsRecycled();
334 }
335 // 需要重试情况下,主动断开连接
336 httpEngine.release(true);
337 // 生成一个新的 HttpEngine
338 httpEngine = newHttpEngine(retryMethod, rawRequestHeaders,
339 httpEngine.getConnection(), (RetryableOutputStream) requestBody);
340 }
341 }
如前所述initHttpEngine()以及httpEngine.sendRequest在getOutputStream那里已经做了详细分析了,这里也不用再赘述了。
这里有HttpEngine中的两个方法需要关注,它与如何缓存响应数据以及如何重用连接有关。先来看readResponse()方法。
/**
794 * Flushes the remaining request header and body, parses the HTTP response
795 * headers and starts reading the HTTP response body if it exists.
796 */
797 public final void readResponse() throws IOException {
798 if (hasResponse()) {
799 return;
800 }
801
802 if (responseSource == null) {
803 throw new IllegalStateException("readResponse() without sendRequest()");
804 }
805
806 if (!responseSource.requiresConnection()) {
807 return;
808 }
809
810 if (sentRequestMillis == -1) {
811 int contentLength = requestBodyOut instanceof RetryableOutputStream
812 ? ((RetryableOutputStream) requestBodyOut).contentLength()
813 : -1;
814 writeRequestHeaders(contentLength);
815 }
816
817 if (requestBodyOut != null) {
818 requestBodyOut.close();
819 if (requestBodyOut instanceof RetryableOutputStream) {
820 ((RetryableOutputStream) requestBodyOut).writeToSocket(requestOut);
821 }
822 }
823
824 requestOut.flush();
825 requestOut = socketOut;
826 // 读取响应头
827 readResponseHeaders();
828 responseHeaders.setLocalTimestamps(sentRequestMillis, System.currentTimeMillis());
829
830 if (responseSource == ResponseSource.CONDITIONAL_CACHE) {
831 if (cachedResponseHeaders.validate(responseHeaders)) {
832 release(true);//如果是条件缓存且缓存有效则释放连接并标记为重用连接
833 ResponseHeaders combinedHeaders = cachedResponseHeaders.combine(responseHeaders);
834 setResponse(combinedHeaders, cachedResponseBody);
835 if (responseCache instanceof ExtendedResponseCache) {
836 ExtendedResponseCache httpResponseCache = (ExtendedResponseCache) responseCache;
837 httpResponseCache.trackConditionalCacheHit();
838 httpResponseCache.update(cacheResponse, getHttpConnectionToCache());
839 }
840 return;
841 } else {
842 IoUtils.closeQuietly(cachedResponseBody);
843 }
844 }
845
846 if (hasResponseBody()) {
// 将响应数据写入缓存
847 maybeCache(); // reentrant. this calls into user code which may call back into this!
848 }
849 // 获取响应体的输入流。
850 initContentStream(getTransferStream());
851 }
注释里面有几个关键的内部方法调用,一个一个来看吧。
readResponseHeaders读取响应行与响应头
5 private void readResponseHeaders() throws IOException {
576 RawHeaders headers;
577 do {
578 headers = new RawHeaders();
// 读取响应行
579 headers.setStatusLine(Streams.readAsciiLine(socketIn));
// 读取其他响应头参数,下面直接贴出来了
580 readHeaders(headers);
581 } while (headers.getResponseCode() == HTTP_CONTINUE);
582 setResponse(new ResponseHeaders(uri, headers), null);
583 }
624 private void readHeaders(RawHeaders headers) throws IOException {
625 // parse the result headers until the first blank line
626 String line;
// 直到读到空行为止,头与数据以空行分开
627 while (!(line = Streams.readAsciiLine(socketIn)).isEmpty()) {
628 headers.addLine(line);
629 }
630 // 解析 cookie
631 CookieHandler cookieHandler = CookieHandler.getDefault();
632 if (cookieHandler != null) {
633 cookieHandler.put(uri, headers.toMultimap());
634 }
635 }
关键的东西在代码里有注释了,主要是读响应行,读响应头并设置cookie。而响应头与响应数据之间的空格就是空行。其实请求的也是,如果包含有请求体时,请求头与请求体之间也是空行分开。
release,这里先不贴代码,后面会再继续分析,只要记住在条件缓存的情况下会释放connection,且带的参数为 true.
maybeCache,将响应数据写入HttpResponseCache,比较简单,不展开了。
getTransferStream,构建返回给调用者的 InputStream。终于拿到InputStream了。
readResponse()已经解析完了,然而在getResponse中还有工作需要做。其接下来会通过处理响应头来确认是否需要重试或者重试的策略,是否需要授权(401,可能需要用户名或者密码),是否需要重定向次数已达到最大(5次)。不需要重试的情况下标记请求由请求池自动回收。需要重试的情况下,释放并重用连接,因为这里调用了HttpEngine#release()方法时传入的参数为 true。这里同样记住传入的参数为true
6.小结
连接所涉及的东西有点多,也可能有些乱,也记不住了,那先总结一波吧。
6.1openConnection()方法
该方法主要是根据协议确定对应的帮助类HttpHandler以及HttpURLConnectionImpl。之后的操作都基于HttpURLConnectionImpl来进行。
6.2参数设置
在getOutpuStream()以及getInputStream()或者显式直接调用connect()方法之前设置好参数,否则会报异常。这三个方法都会触发状态 connected 为 true。
6.3Http协议包装
在发出请求前,会构造好请求行,请求头参数一起发送给服务器。并且注意到在HTTP的版本大于 0 的情况下,默认开启了 keep-alive
6.4缓存
根据HTTP的缓存规则,在getInputStream阶段会对响应回来的数据即response进行缓存。缓存的内部算法采用的是DiskLRUCache实现,key 为对应 url 的MD5编码。
6.5连接池
对当前连接好的HTTP会通过连接池缓存起来,连接池里已经有相等的Address了就会进行重用。其中Address相等需要host,port,sslfactory,proxy,tunel都相等。连接池的全部内容这里其实还没有讲完,比如连接put以及回收。
6.6TCP连接
getOutpuStream()以及getInputStream()或者显式直接调用connect()方法最终都会触发TCP的连接,也就是我们需要的HTTP连接。
三、HTTP通信
所谓的通信,就是利用getOutputStream()获取输出流,从而将数据写到服务端。再利用getInputStream()获取输入流,读取从服务端返回的数据。
四、断开连接
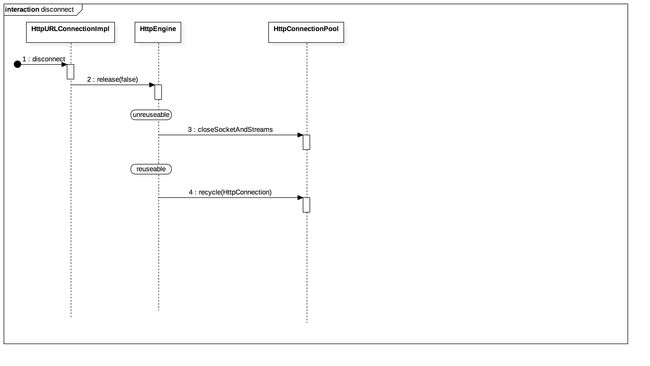
先来看disconnect()方法
@Override public final void disconnect() {
89 // Calling disconnect() before a connection exists should have no effect.
90 if (httpEngine != null) {
91 // We close the response body here instead of in
92 // HttpEngine.release because that is called when input
93 // has been completely read from the underlying socket.
94 // However the response body can be a GZIPInputStream that
95 // still has unread data.
96 if (httpEngine.hasResponse()) {
97 IoUtils.closeQuietly(httpEngine.getResponseBody());
98 }
99 httpEngine.release(false);
100 }
101 }
主要是进一步调用 HttpEngine#release()方法进行释放。另外需要注意的是关闭了responseBody,那这个又是什么呢?后面会详情讲解。
/**
483 * Releases this engine so that its resources may be either reused or
484 * closed.
485 */
486 public final void release(boolean reusable) {
487 // If the response body comes from the cache, close it.
// 从缓存取的结果直接关掉
488 if (responseBodyIn == cachedResponseBody) {
489 IoUtils.closeQuietly(responseBodyIn);
490 }
491
492 if (!connectionReleased && connection != null) {
493 connectionReleased = true;
494
495 // We cannot reuse sockets that have incomplete output.
// 输出数据流还没有关闭不能重用
496 if (requestBodyOut != null && !requestBodyOut.closed) {
497 reusable = false;
498 }
499
500 // If the request specified that the connection shouldn't be reused,
501 // don't reuse it. This advice doesn't apply to CONNECT requests because
502 // the "Connection: close" header goes the origin server, not the proxy.
// 请求协议头描述了connection为close的不能重用
503 if (requestHeaders.hasConnectionClose() && method != CONNECT) {
504 reusable = false;
505 }
506
507 // If the response specified that the connection shouldn't be reused, don't reuse it.
// 响应协议头描述了connection为close的不能重用
508 if (responseHeaders != null && responseHeaders.hasConnectionClose()) {
509 reusable = false;
510 }
511 // 不知道长度的输入流不能重用
512 if (responseBodyIn instanceof UnknownLengthHttpInputStream) {
513 reusable = false;
514 }
515
516 if (reusable && responseBodyIn != null) {
517 // We must discard the response body before the connection can be reused.
518 try {
519 Streams.skipAll(responseBodyIn);
520 } catch (IOException e) {
521 reusable = false;
522 }
523 }
524
525 if (!reusable) {
526 connection.closeSocketAndStreams();
527 connection = null;
528 } else if (automaticallyReleaseConnectionToPool) {
529 HttpConnectionPool.INSTANCE.recycle(connection);
530 connection = null;
531 }
532 }
533 }
中间一大段都可以先不用太关注,看看注释就行。看最后几句,注意这里的 reuseable 传递进来的是false,那么最后是一定会关闭连接的了。也就是说一旦执行disconnect()连接就会被关闭。
131 public void closeSocketAndStreams() {
132 IoUtils.closeQuietly(sslOutputStream);
133 IoUtils.closeQuietly(sslInputStream);
134 IoUtils.closeQuietly(sslSocket);
135 IoUtils.closeQuietly(outputStream);
136 IoUtils.closeQuietly(inputStream);
137 IoUtils.closeQuietly(socket);
138 }
最后把socket与输入输出流都关闭了。也就是说整个连接都断开了。那如果要保持连接一直是重用的,那就不能disconnect()了。这样又是否会有内存泄漏?
还记得前面提到过的吗?在两种情况下框架会自动发生重用,一个是重试情况下,一个条件缓存情况下。所以说这个连接重用还真的是弱呢。
关于HttpConnectionPool#recycle()方法来继续看代码。
public void recycle(HttpConnection connection) {
91 Socket socket = connection.getSocket();
92 try {
93 SocketTagger.get().untag(socket);
94 } catch (SocketException e) {
95 // When unable to remove tagging, skip recycling and close
96 System.logW("Unable to untagSocket(): " + e);
97 connection.closeSocketAndStreams();
98 return;
99 }
100 //
101 if (maxConnections > 0 && connection.isEligibleForRecycling()) {
102 HttpConnection.Address address = connection.getAddress();
103 synchronized (connectionPool) {
104 List connections = connectionPool.get(address);
105 if (connections == null) {
106 connections = new ArrayList();
107 connectionPool.put(address, connections);
108 }
// 未达到最大连接数
109 if (connections.size() < maxConnections) {
110 connection.setRecycled();
// 把连接加入到连接池
111 connections.add(connection);
112 return; // keep the connection open
113 }
114 }
115 }
116
117 // don't close streams while holding a lock!
// 不能重用就关闭
118 connection.closeSocketAndStreams();
119 }
在recycle()时判断是否已经达到最大连接数,如果没有就可以重用,否则就会关闭连接。这里还需要关注一下maxConnections,默认情况下每个URI最大的连接数为 5。如何得来的?需要关注一下HttpConnectionPool的构造函数。
private HttpConnectionPool() {
51 String keepAlive = System.getProperty("http.keepAlive");
52 if (keepAlive != null && !Boolean.parseBoolean(keepAlive)) {
53 maxConnections = 0;
54 return;
55 }
56
57 String maxConnectionsString = System.getProperty("http.maxConnections");
58 this.maxConnections = maxConnectionsString != null
59 ? Integer.parseInt(maxConnectionsString)
60 : 5;
61 }
也就是说需要系统设置了 http.keepAlive 这个参数为true,那么就可以进一步设置maxConnections的大小了。可以自己定义,也可以使用默认值为5.
五、总结
(1)至此,Android原生网络库,仅HTTP部分终于分析完了,还是学习不到少东西的。
(2)Android原生网络库只是HTTP协议在网络应用层的实现,有一定的封装,但本身并没有进行过多的扩展。
(3)这里面我们能看到最基本的一些Http协议相关的内容,如请求行,请求头以及请求体的封装,解析,默认参数设置等。当然也有对响应行,响应头以及响应体的解析,封装,默认处理等。对了,还有一个重要的,那就是cookie,也有相应的解析以及处理,包括请求和响应时。
(4)Android原生网络库同样也实现了响应内容的缓存,所用的算法也是DiskLRUCache
(5)关于重用,除了依赖Http的请求参数 keep-alive通知服务器希望连接之外,还依赖于系统对 http.keepalive的设定。而同一个url默认最多只能有5个连接。