聊一聊leetcode第156场周赛
一. 5205. 独一无二的出现次数
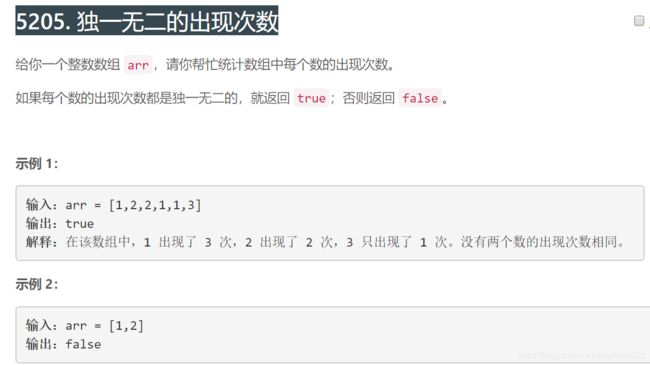

1.这个提示很关键,第一名用了提示的关系建立了一个对应的数组.(来自JOHNKRAM大神)
class Solution {
public:
bool uniqueOccurrences(vector& arr) {
int s[2005];
//memset用于清空数组.
memset(s, 0, sizeof(s));
//将arr里的值作为数组的键.因为数组大小不超过1000,值-1000到1000.
for (auto i : arr)s[i + 1000]++;
sort(s, s + 2005);//排序是为了使值连续.
for (int i = 0; i<2004; i++)if (s[i] && s[i + 1] == s[i])return 0;
return 1;
}
}; 2. 第2名liouzhou_101的想法很自然.
class Solution {
public:
bool uniqueOccurrences(vector& a) {
//构建两个哈希表.
map F, G;
//F统计每个值出现的个数.
for (auto x : a) F[x] ++;
//G统计F中每个值个数的个数.
for (auto [x, y] : F) G[y] ++;
//如果超过2,肯定有相同的.
for (auto [x, y] : G) if (y >= 2) return false;
return true;
}
}; 3. 我的其实也很自然.
class Solution {
public:
bool uniqueOccurrences(vector& arr) {
map res;
for (int i = 0; i < arr.size(); i++) {
if (res.count(arr[i]) == 0) {
res.insert(map::value_type(arr[i], 1));
}
else
res[arr[i]]++;
}
set tmp;
for (auto i : res) {
tmp.insert(i.second);
}
if (tmp.size() != res.size())
return false;
else
return true;
}
};
二. 5207. 尽可能使字符串相等

1. 这一题第一眼看上去绝对的dp,但是很可惜超出内存限制了.......没办法,我用的二维数组存储dp表格
 \
\

2,提示很关键, 不过dp虽然超内存,但是思想不错,以后可以借鉴.
class Solution {
public:
int equalSubstring(string s, string t, int maxCost) {
int m = s.length();
//dp[len][i]的含义是以长度为len并且以i索引结尾的字符子串的转化长度.
//cost[len][i]的含义是长度为len并且以i索引结尾的字符子串的开销.
vector> dp(m + 1, vector(m, 0));
//初始化值都为0.
vector> cost(m + 1, vector(m, 0));
int maxv = -1;//求最大值,所以需要maxv变量.
//初始化长度为1的情况.
for (int num = 0; num <= m - 1; num++) {
if (abs(s[num] - t[num]) <= maxCost) {
dp[1][num] = 1;
}
cost[1][num] = abs(s[num] - t[num]);
maxv = max(maxv, dp[1][num]);
}
for (int len = 2; len <= m; len++) {
for (int i = len - 1; i <= m - 1; i++) {
cost[len][i] = cost[len - 1][i - 1] + abs(s[i] - t[i]);
if (cost[len][i] <= maxCost)
//如果加上i的开销小于maxcost,则长度加1.
dp[len][i] = dp[len - 1][i - 1] + 1;
else {
//这个容易错,注意一下,因为我们的dp含义一定以字符串i结尾,
//所以如果本身i的开销大于maxcost,则肯定为0,跳过.
if (abs(s[i] - t[i]) > maxCost) {
continue;
}
//否则,dp[len][i]就只能就只能从前面开始判断,并且相应截断.
for (int num = i - len + 1; num <= i - 1; num++) {
if (cost[len][i] - cost[num - i + len][i - len + 1] <= maxCost) {
dp[len][i] = dp[i - num][i];
}
}
}
maxv = max(maxv, dp[len][i]);
}
}
return maxv;
}
}; 3. 这个时候只能参考大神代码了.(JOHNKRAM)(感觉智商被碾压)(是我想的太复杂了......看到啥都dp,但其实二维数组很耗费内存的,而且也没有必要.)
class Solution {
int a[100005];//根据范围定义数组.长度在100000之内.
public:
int equalSubstring(string s, string t, int maxCost) {
int n = s.size(), i, j, ans = 0;
//其实也是dp的思想,但是没有开辟额外空间存储.
//其中a[i]代表以i索引结尾的字符串的总开销.
for (i = 0; imaxCost; j++);
ans = max(ans, i - j);
}
return ans;
}
}; 三. 5206. 删除字符串中的所有相邻重复项 II
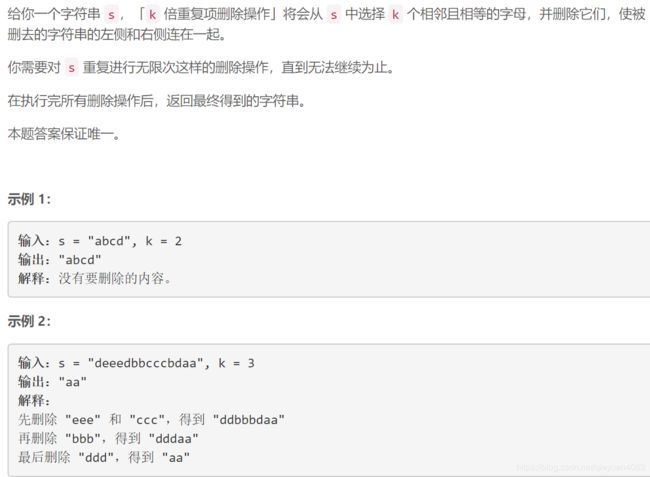
1. 这一题第一眼看上去就是递归.放出我自己的代码.
class Solution {
public:
string removeDuplicates(string s, int k) {
int n = s.length();
//令res等于s,如果找不到删除就直接返回.
string res = s;
for (int i = 0; i <= n - k; i++) {
//找长度为k的需要删除的部分是否满足.
int first = i, end = i + k - 1, tmp = s[first];
while (first < end) {
//这里尤其注意,第一次提交就bug了.
//判断相等第一反应看前后字符是否一样,但是有可能回文串,
//导致错误,其实也可以直接顺序判断的....不知道我怎么想的.
if (s[first] == s[end] && s[first] == tmp) {
first++;
end--;
}
else
break;//直接跳出.
}
if (first >= end) {
//分三种情况,拼接字符串并返回.
//递归想法.
if (i > 0 && i < n - k)
res = removeDuplicates(s.substr(0, i) + s.substr(i + k, n - i - k), k);
else if (i == 0)
res = removeDuplicates(s.substr(i + k, n - i - k), k);
else if (i == n - k)
res = removeDuplicates(s.substr(0, i), k);
break;
}
}
return res;
}
};2. 参考下上一题大神的思路.
class Solution {
int a[100005], t;//看题目范围设定数组范围.
char c[100005];
string ans;
public:
string removeDuplicates(string s, int k) {
t = 0;
//第1个for循环意思是,如果有新的字母.c[i]代表从1开始
//不超过k个的需要保留的字母,a[i]统计连续相同字母的个数.
for (auto i : s)if (i == c[t])
{
a[t]++;
//t代表有效的字母,如果到k个了,则t--,这样下次就会覆盖.
if (a[t] == k)t--;
}
else
{
c[++t] = i;
a[t] = 1;
}
ans = "";
//第二个for打印连续a[i]个c[i]中的字符.
for (int i = 1; i <= t; i++)for (int j = 0; j3.好吧又被碾压了......
四. 5208. 穿过迷宫的最少移动次数
1.这一题第一眼看到肯定动态规划,因为需要求解一个最优问题.算了还是参考大神的代码吧.
class Solution {
int f[105][105][2];
public:
//动态规划,其中f前两个代表贪吃蛇的头部坐标,最后代表贪吃蛇的两种状态.
//这个设置状态得学学,明白了含义程序不难看懂了.
int minimumMoves(vector>& grid) {
int n = grid.size(), i, j, ans;
memset(f, 127, sizeof(f));
f[0][0][0] = 0;
for (i = 0; i 2.大神两个地方值得学习,第一个就是f前面两个代表贪吃蛇前面,我设置为第二点的话,就多了很多麻烦.第二个就是状态单独放在第三维坐标,省去了判断.
最后再接再厉吧..........