RocketMQ4.X消息队列详细笔记
人不能没有批评和自我批评
那样一个人就不能进步。
目录
- JMS和消息中间件介绍
- JMS消息服务和使用场景
- 消息中间件常见概念和编程模型
- 主流消息队列和技术选型讲解
- 基础介绍和阿里云服务器快速部署
- RocketMQ4.x消息队列介绍
- 阿里云Linux服务器安装RocketMQ步骤
- 整合Springboot2.X实战
- 实战发送消息
- 实战接受消息
- 高级篇幅之集群架构
- 集群模式架构分析
- 消息可靠性之同步、异步刷盘
- 消息可靠性之同步、异步复制
- 集群高可用之主从模式搭建
- 故障演练之主节点Broker退出保证消息可用
- 主从同步必备知识点
- 生产者核心配置和核心知识
- 生产者核心配置
- 消息发送模式及其状态
- 生产和消费消息重试及处理
- 异步发送消息和回调实战
- OneWay发送消息及多种场景对比
- 延迟消息实战和电商系统中应用
- MessageQueueSelector 实战
- 顺序消息详解与实际应用模拟操作
- 消费者核心配置和核心知识
- 消费者核心配置
- 两种消费方式
- 标签Tag详解和消息过滤原理
- PushConsumer、PullConsumer消费模式分析
- 消息偏移量0ffset
- 消息存储之CommitLog和ConsumerQueue
- 高性能分析之ZeroCopy零拷贝技术
- 分布式事务消息
- 介绍
- 总体架构
- 分布式事务消息实战
- 面试专题
- 为什么使用消息队列,怎么选择技术
- 消息怎么避免重复消费
- 如何保证消息的可靠性传输
- 消息发生大量堆积应该怎么处理
- RocketMQ高性能的原因分析
JMS和消息中间件介绍
JMS消息服务和使用场景
JMS:
JAVA消息服务(JAVA Message Service),JAVA平台中关于面向消息中间件的接口
JMS是一种与厂商无关的API,用来访问消息收发系统消息
使用场景
核心应用
解耦
订单系统-->物流系统
异步
用户注册-->发送短信,初始化信息
削峰
秒杀,日志处理
跨平台,多语言
分布式事务,最终一致性
RPC调用上下游对接,数据源变动-->通知下属
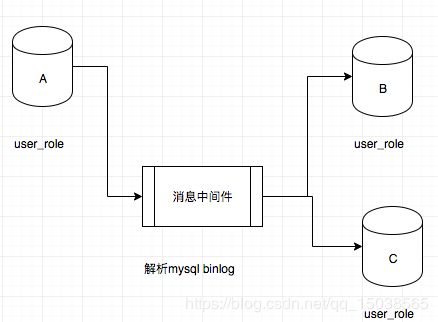
主从库数据一致性,可先保存主库A,主库通过消息队列进行发送到从库
异步改造前
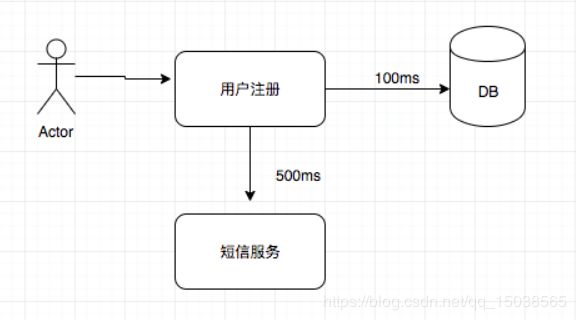
异步改造后
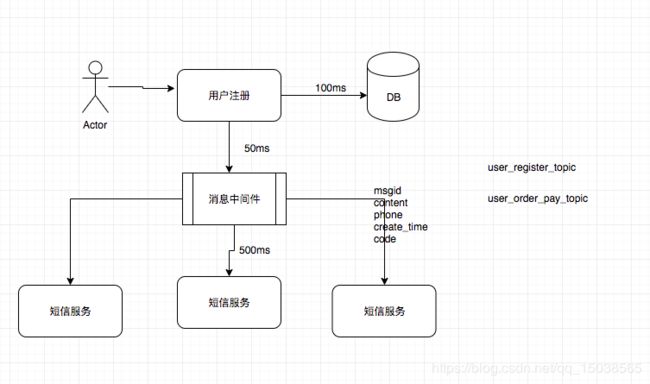
主从库数据一致性,可先保存主库A,主库通过消息队列进行发送到从库
消息中间件常见概念和编程模型
常见概念
。JMS提供者:连接面向消息中间件的,JMS接口的一个实现,RocketMQ,ActiveMQ,Kafka等 等
。JMS生产者(Message Producer):生产消息的服务
。 JMS消费者(Message Consumer):消费消息的服务
。JMS消息:数据对象
。JMS队列:存储待消费消息的区域
。JMS主题:一种支持发送消息绐多个订阅者的机制
。JMS消息通常有两种类型:点对点(Point-to-Point)、发布/订阅(Publish/Subscribe)
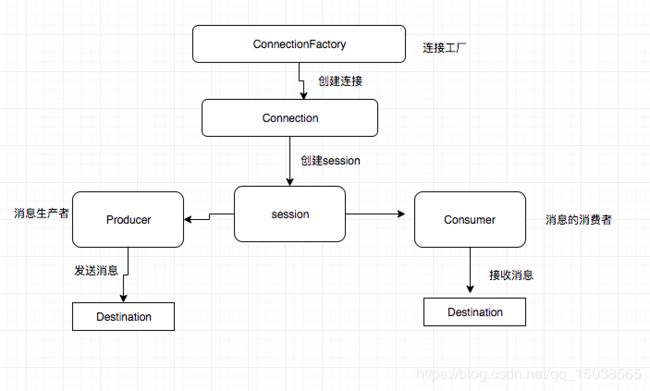
基础编程模型(MQ中常见的类)
。ConnectionFactory :连接工厂,JMS用它创建连接
。Connection : JMS 客户端到JMS Provider 的连接
。Session:—个发送或接收消息的线程
。Destination :消息的目的地;消息发送绐谁.
。MessageConsumer / MessageProducer:消息消费者,消息生产者
流程
主流消息队列和技术选型讲解
ActiveMQ
Apache出品,历史悠久,支持多种语言的客户端和协议,支持多种语言Java,
NET, C++等,基于JMS Provider的实现
缺点:吞吐量不高,多队列的时候性能下降,存在消息丢失的情况,比较少大规模使用
Kafka
是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一
种高吞吐量的分布式发布订阅消息系统,它可以处理大规模的网站中的所有动作流数据
(网页浏览,搜索和其他用户的行动),副本集机制,实现数据冗余,保障数据尽量不
丢 失;支持多个生产者和消费者
缺点:不支持批量和广播消息,运维难度大,文档比较少,需要掌握Scala
RabbitMQ
是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如: Python、
Ruby、.NET、Java、JMS、C、用于在分布式系统中存储转发消息,在易用性、扩展性、
高可用性等方面表现不错
缺点:使用Erlang开发,阅读和修改源码难度大
RocketMQ
阿里开源的一款的消息中间件,纯Java开发,具有高吞吐量、高可用性、适合大规模分布
式系统应用的特点,性能强劲(零拷贝技术),支持海量堆积,支持指定次数和时间间隔
的失败消息重发,支持consumer端tag过滤、延迟消息等,在阿里内部进行大规模使用,
适合在电商,互联网金融等领域使用
基础介绍和阿里云服务器快速部署
RocketMQ4.x消息队列介绍
介绍
Apache RocketMQ作为阿里开源的一款高性能、高吞吐量的分布式消息中间件
特点
。支持Broker和Consumer端消息过滤
。支持发布订阅模型,和点对点,
。支持拉pull和推push两种消息模式
。单一队列百万消息、亿级消息堆积
。 支持单master节点,多master节点,多master多slave节点
。任意一点都是高可用,水平拓展,Producer, Consumer、队列都可以•分布式
。消息失败重试机制、支持特定leveI的定时消息
。新版本底层采用Netty
。4.3.x支持分布式事务
。适合金融类业务,高可用性跟踪和审计功能。
概念
。Producer:消息生产者
。Producer Group:消息生产者组,发送同类消息的一个消息生产组
。Consumer:消费者
。Consumer Group:消费同类消息的多个实例
。Tag:标签,子主题(二级分类)对topic的进一步细化,用于区分同一个主题下的不同
业务的消息
。Topic:主题,如订单类消息,queue是消息的物理管理单位,而topic是逻辑管理单位。
一个 topic下可以•有多个queue,默认自动创建是4个,手动创建是8个
。Message :消息,每个message必须指定一个topic
。Broker: MQ程序,接收生产的消息,提供绐消费者消费的程序
。Name Server:绐生产和消费者提供路由信息,提供轻量级的服务发现、路由、元数据
信息,可以多个部署,互相独立(比zookeeper更轻量)
。Offset:偏移量,可以理解为消息进度
。commit log:消息存储会写在Commit log文件里面
官网
阿里中间团队博客
阿里云Linux服务器安装RocketMQ步骤
安装JDK8—详细参考其他博文
安装Maven
解压: tar -zxvf apache-maven-3.6.0-bin.tar.gz
重命名: mv apache-maven-3.6.0 maven
vim /etc/profile
export PATH=/usr/local/software/maven/bin:$PATH
立刻生效: source /etc/profile
安装RocketMQ
安装解压环境: yum install unzip
解压: unzip rocketmq-all-4.4.0-source-release.zip
重命名: mv rocketmq-all-4.4.0 rocketmq
进去: cd /usr/local/rocketmq
编译: mvn -Prelease-all -DskipTests clean install -U
cd distribution/target/apache-rocketmq
启动NaveService: nohup sh bin/mqnamesrv &
检查: tail -f nohup.out
启动Broker: nohup sh bin/mqbroker -n localhost:9876 &
检查: jps
查看cpu占用: top
开发阶段开启阿里云安全组9876和10911
控制台检测
生产消息
export NAMESRV_ADDR=localhost:9876
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
消费消息
export NAMESRV_ADDR=localhost:9876
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
常见问题
RocketMQ默认需要4G内存,NameServer内存不够怎么处理?
NameService内存不足:
vim bin/runserver.sh
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
Broker内存不足
vim bin/runbroker.sh
JAVA_OPT="${JAVA_OPT} -server -Xms528m -Xmx528m -Xmn256m"
安装RocketMQ4.X控制台
解压: unzip rocketmq-externals-master.zip
cd /usr/local/rocketmq-externals-master/rocketmq-console
修改2个问题
vim pom.xml
修改rocketmq版本号,去掉后面字母,只留4.4.0
cd /src/main/resources
vim application.properties
设置地址: 127.0.0.1:9876
cd /usr/local/rocketmq-externals-master/rocketmq-console
编译: mvn clean package -Dmaven.test.skip=true
运行:
cd target
nohup java -jar rocketmq-console-ng-1.0.0.jar &
访问: 119.22.22.22:8080

整合Springboot2.X实战
实战发送消息
步骤+代码
。快速创建 springboot 项目 https://start.spring.io/
。加入相关依赖
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.4.0</version>
</dependency>
。Message 对象
------topic:主题名称
------tag:标签,用于过滤
------key:消息唯一标示,可以是业务字段组合
------body:消息体,字节数组
。注意发送消息到Broker,需要判断是否有此topic启动broker的时候,本地环境建议
开启自动创建topic,生产环境建议关闭自动化创建topic建议先手工创建Topic,如果
靠程序自动创建,然后再投递消息,会出现延迟情况
。概念模型:一个topic下面对应多个queue,可以■在创建Topic时指定,如订单类topic
。通过可视化管理后台查看消息
private String producerGroup="pay_producer_group";
private String nameServerAddr="119.11.11.11:9876";
private DefaultMQProducer producer;
public PayProducer(){
producer=new DefaultMQProducer(producerGroup);
//指定NameService地址,多个地址之间以 ; 隔开
producer.setNamesrvAddr(nameServerAddr);
start();
}
public DefaultMQProducer getProducer(){
return producer;
}
/**
* 对象在使用之前必须要调用一次,只能初始化一次
*/
public void start(){
try {
producer.start();
} catch (MQClientException e) {
e.printStackTrace();
}
}
/**
* 一般在应用上下文,使用上下文监听器,进行关闭消息队列连接操作
*/
public void shutdown(){
producer.shutdown();
}
@Autowired
private PayProducer payProducer;
private static final String topic="test_pay_topic_1";
@RequestMapping("/test/pay_cb")
public Object callBack(String text) throws Exception {
Message message = new Message(topic, "tag_1", ("test=" + text).getBytes());
SendResult send = payProducer.getProducer().send(message);
System.out.println(send);
return "发送成功!";
}
常见错误1:
org.apache.rocketmq.remoting.exception.RemotingTooMuchRequestException:
sendDefaultImpl call timeout
原因:阿里云存在多网卡,rocketmq都会根据当前网卡选择一个IP使用,当你的机器
有多块网卡时,很有可能会有问题。比如,我遇到的问题是我机器上有两个IP,一个公
网IP,一个私网IP,因此需要配置 broker.conf指定当前的公网ip,然后重新启动broker
新增配置:conf/broker.conf (属性名称brokerIP1=broker所在的公网ip地址)
新增这个配置:brokerIP1=119.11.11.11
启动命令:nohup sh bin/mqbroker -n localhost:9876 -c ./conf/broker.conf &
阿里云控制台安全组开发10909端口
常见错误2:
MQClientException: No route info of this topic, TopicTest1
原因:Broker禁止自动创建Topic,且用户没有通过手工方式创建 此Topic,或者broker
和Nameserver网络不通
解决:
通过sh bin/mqbroker -m 查看配置
autoCreateTopicEnable=true 贝自动创建 topic(需要RocketMQ客户端版本和服务器
版本一致)
Centos7 关闭防火墙 systemctl stop firewalld
常见错误3:
控制台查看不了数据,提示连接10909错误
原因:Rocket默认开启了VIP通道,VIP通道端口为10911-2 = 10909
解决:阿里云安全组需要增加一个端口 10909
测试
![]()

实战接受消息
步骤+代码
准备工作和生产者一样
private static final String topic = "test_pay_topic_1";
private String producerGroup = "pay_consumer_group";
private String nameServerAddr = "119.11.11.11:9876";
private DefaultMQPushConsumer consumer;
public PayConsumer() throws MQClientException {
consumer = new DefaultMQPushConsumer(producerGroup);
consumer.setNamesrvAddr(nameServerAddr);
//消费策略,从最后一个开始消费
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
//订阅主题,监听拿些标签
consumer.subscribe(topic, "*");
//注册消费者监听器,有消息到来就触发函数
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
MessageExt m = msgs.get(0);
System.out.println("线程名称:" + Thread.currentThread().getName() + "---消息体为:" + new String(m.getBody()));
//获取消息Topic
String topic = m.getTopic();
//获取消息Tag
String tags = m.getTags();
//获取消息Key
String keys = m.getKeys();
//获取消息内容
String body = new String(m.getBody(), "utf-8");
System.out.println("topic=" + topic + "---tags=" + tags + "---keys=" + keys + "---body=" + body);
//告诉消息Broker消费成功
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
//消息消费失败
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
});
consumer.start();
System.out.println("消费者启动成功!");
}
测试

高级篇幅之集群架构
集群模式架构分析
1. 单节点
优点:
本地开发测试,配置简单,同步刷盘消息一条都不会丢
缺点:
不可靠,如果宕(dàng)机,会导致服务不可用
2. 主从(异步复制、同步双写)
优点:
同步双写消息不丢失,异步复制存在少量丢失,主节点宕机,从节点可以对外提供
消息的消费,但是不支持写入
缺点:
主备有短暂消息延迟,毫秒级,目前不支持自动切换,需要脚本或者其他程序进行
检测然后进行停止broker,重启让从节点成为主节点
3. 双主
优点:
配置简单,可以靠配置RAID磁盘阵列保证消息可靠,异步刷盘丢失少量消息
缺点:
master机器宕机期间,未被消费的消息在机器恢复之前不可消费,实时性会受到影响
4. 双主双从,多主多从模式(异步复制)
优点:
磁盘损坏,消息丢失的非常少,消息实时性不会受影响,Master宕机后,消费者仍然可以
从Slave消费
缺点:
主备有短暂消息延迟,毫秒级,如果Master宕机,磁盘损坏情况,会丢失少量消息
5. 双主双从,多主多从模式(同步双写)
优点:
同步双写方式,主备都写成功,向应用才返回成功,服务可用性与数据可用性都非常高
缺点:
性能比异步复制模式略低,主宕机后,备机不能自动切换为主机
推荐方案2、4、5


消息可靠性之同步、异步刷盘
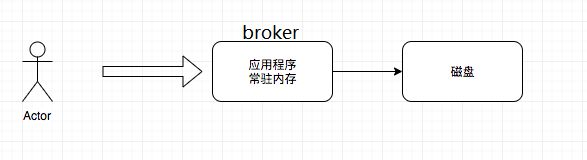
存储系统往往追求尽量高的吞吐,在写入的时候会尽量提升系统的吞吐。一般来说,
提升系统性能的方式是先将数据写入内存中,然后再刷盘到磁盘中进行持久化。
同步刷盘:数据安全性高(保存到磁盘再返回SUCCESS)
异步刷盘(数据可能丢失,性能高)
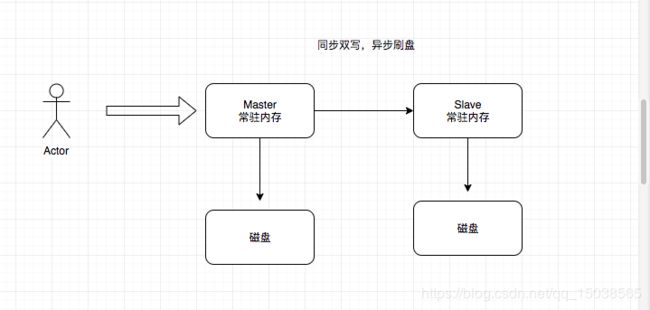
消息可靠性之同步、异步复制
・Master - Slave 节点里面
・异步复制:数据可能丢失,性能高
・同步复制:数据安全性高,性能低一点
・最终推荐方式:同步双写(即M-S同步复制),异步刷盘
集群高可用之主从模式搭建
机器列表,准备2台阿里云服务器,也可以用VMcare虚拟机
server1 ssh root@192.168.159.129---使用---master
server2 ssh root@192.168.159.130---使用---slave
配置参考前面的详细过程
1-修改RocketMQ(启动内存配置,两个机器都要修改)
2-启动两个机器的nameServer
3-编辑并启动rocketmq
#conf里面的文件夹代表使用哪种模式
vim /usr/local/rocketmq/distribution/target/apache-rocketmq/conf/2m-2s-async/broker-a.properties
主节点配置:
#nameServer地址
namesrvAddr=192.168.159.129:9876;192.168.159.130:9876
#集群名
brokerClusterName=Cluster
#分片名
brokerName=broker-a
#编号,0为主,>0为从
brokerId=0
deleteWhen=04
fileReservedTime=48
#角色模式---主从异步复制
brokerRole=ASYNC_MASTER
刷盘类型
flushDiskType=ASYNC_FLUSH
vim /usr/local/rocketmq/distribution/target/apache-rocketmq/conf/2m-2s-async/broker-a-s.properties
从节点配置:
namesrvAddr=192.168.159.129:9876;192.168.159.130:9876
brokerClusterName=Cluster
brokerName=broker-a
brokerId=1
deleteWhen=04
fileReservedTime=48
brokerRole=SLAVE
flushDiskType=ASYNC_FLUSH
启动:
nohup sh bin/mqbroker -c conf/2m-2s-sync/broker-a.properties &
nohup sh bin/mqbroker -c conf/2m-2s-sync/broker-a-s.properties &
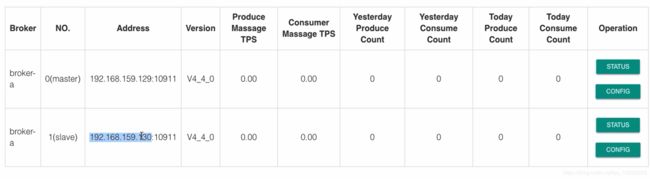
4-使用管控台
修改事项
pom.xml 里面的rocketmq版本号
application.properties 里面的 nameserver
增加rocketmq.config.namesrvAddr=192.168.159.129:9876;192.168.159.130:9876
mvn install -Dmaven.test.skip=true
java -jar rocketmq-console-ng-1.0.0.jar
故障演练之主节点Broker退出保证消息可用
・发送一条消息,关闭主节点,关闭主节点之后不能写入
・从节点提供数据供外面消费,但不能接受新消息
・主节点上线后同步从节点已经被消费的数据(offset同步)
主从同步必备知识点
•Broker分为master与slave,—个master可以对应多个Slave,但一个slave只能对应一个master, master与slave通过相同的Broker Name来匹配,不同的brokerId来定义是master还是slave
Broker向所有的NameServer结点建立长连接,定时注册Topic和发送元数据信息
NameServer定时扫描(默认2分钟)所有存活broker的连接,如果超过时间没响应则断开连接(心 跳检测),但是consumer客户端不能感知,consumer定时(30s)从NameServer获取topic的最 新信息,所以broker不可用时,consumer最多最需要30s才能发现(Producer的机制一样,在未发现broker宕机前发送的消息会失败)
•只有master才能进行写入操作,slave不允许写入只能同步,同步策略取决于master的配置
•客户端消费可以从master和slave消费,默认消费者都从m aster消费,如果在m aster挂后,客户端 从NameServer中感知到Broker宕机,就会从slave消费,感知非实时,存在一定的滞后性,slave不 能保证master的消息100%都同步过来了,会有少量的消息丢失。但一旦master恢复,未同步过去 的消息会被最终消费掉
•如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分 至Uqueue,也就无法消费到消息,也就无法起到分摊负载的作用,所以需要控制让Queue >= Consumer
生产者核心配置和核心知识
生产者核心配置
。compressMsgBodyOverHowmuch :消息超过默认字节4096后进行压缩
。retryTimesWhenSendFailed :失败重发次数
。maxMessageSize :最大消息配置,默认128k
。topicQueueNums :主题下面的队列数量,默认是4
。autoCreateTopicEnable :是否自动创建主题Topic,开发建议为true,生产要为false
。defaultTopicQueueNums :自动创建服务器不存在的topic,默认创建的队列数
。autoCreateSubscriptionGroup:是否允许Broker自动创建订阅组,建议线下开发开启,线上 关闭
。brokerClusterName :集群名称
。brokerId : 0表示Master主节点大于0表示从节点
。brokerIP1 : Broker服务地址
。brokerRole : broker角色 ASYNC_MASTER/ SYNC_MASTER/ SLAVE
。deleteWhen :每天执行删除过期文件的时间,默认每天凌晨4点
。flushDiskType :刷盘策略,默认为ASYNC_FLUSH(异步刷盘),另外是SYNC_FLUSH(同步刷盘)
。listenPort : Broker监听的端口号
。mapedFileSizeCommitLog :单个conmmitlog文件大小,默认是 1GB
。mapedFileSizeConsumeQueue: ConsumeQueue每个文件默认存30W条,可以根据项目调 整
。storePathRootDir :存储消息以及一些配置信息的根目录默认为用户的${HOME}/store
。storePathCommitLog: commitlog存储目录默认为${storePathRootDir}/commitlog
。storePathlndex:消息索引存储路径
。syncFlushTimeout :同步刷盘超时时间
。diskMaxUsedSpaceRatio :检测可用的磁盘空间大小,超过后会写入报错
消息发送模式及其状态
• 消息发送有同步和异步
同步方式:
-消息的发送方发A送一条消息到接收端B,B收到消息之后需要对消息进行处理,然后发送
ACK确认消息回A,A收到B的ACK之后就可以认为这条消息发送成功,并且保证B顺利收到
并处理,在A收到ACK之前A将一直处于阻塞等待状态。
异步方式:
-可细分成发送线程和接受线程异步,发送端进程和接收端进程异步;
-发送线程和接收线程的异步指消息发送线程A发消息到B,A和B都有消息的接收和发送缓
存,A将消息送入发缓存之后立即返回接着发下一条消息,缓存中的消息将被逐条写入
TCP,B端从TCP拿到消息先入收缓存,B从收缓存中逐条取出处理,这里的收发两个线程
处于不同的进程中,且同一时间可能同时处理不同的消息。
-发送端进程和接收端端进程异步指的是,发送方和接收方不必同时在线,A将消息发送到
消息队列,B上线之后从消息队列中获取A发送过来的消息。
• 返回状态共4种
。FLUSH_DISK_TIMEOUT
没有在规定时间内完成刷盘(刷盘策略需要为SYNC_FLUSH才会出这个错误)
。FLUSH_SLAVE_TIMEOUT
主从模式下,broker是SYNC_MASTER,没有在规定时间内完成主从同步
。SLAVE_NOT_AVAILABLE
从模式下,broker是SYNC_MASTER,但是没有找到被配置成Slave的Broker
。SEND_OK
发送成功,没有发生上面的三种问题
生产和消费消息重试及处理
•生产者Producer重试(异步和SendOneWay下配置无效)
•消息重投(保证数据的高可靠性),本身内部支持重试,默认次数是2,
•如果网络情况比较差,或者跨集群则建改多几次
producer=new DefaultMQProducer(producerGroup);
//消息发送失败重试次数,默认2
producer.setRetryTimesWhenSendFailed(3);
//异步发送失败重试次数
producer.setRetryTimesWhenSendAsyncFailed(3);
•消费端重试
•原因:
消息处理异常、broker端到consumer端各种问题,如网络原因闪断,消费处理失败, ACK返回失败等等问题。
•注意:
重试间隔时间配置,默认每条消息最多重试16次
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
超过重试次数人工补偿
消费端去重
一条消息无论重试多少次,这些重试消息的Message ID, key不会改变。
消费重试只针对集群消费方式生效;广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息
......
consumer = new DefaultMQPushConsumer(producerGroup);
//设置消费方式为广播,默认集群模式,广播方式不支持消息重试
consumer.setMessageModel(MessageModel.BROADCASTING);
......
//注册消费者监听器,有消息到来就触发函数
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
MessageExt m = msgs.get(0);
//获取消息重试次数
int reconsumeTimes = m.getReconsumeTimes();
System.out.println("消息重试次数="+reconsumeTimes);
......
//消息消费成功,返回通知Broker
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
/**
* 消息重试机制
*/
System.out.println("消费异常!");
if(reconsumeTimes>=2){
//记录数据库,通知人工介入处理
System.out.println("记录数据库,通知人工介入处理,停止消费!");
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
});
• 异步发送:不会重试,发送总次数等于1
• 于同步而言,超时异常也是不会再去重试。
• 以下附上部分源码
/**
* 说明 抽取部分代码
*/
private SendResult sendDefaultImpl(Message msg, final CommunicationMode communicationMode, final SendCallback sendCallback, final long timeout) {
//1、获取当前时间
long beginTimestampFirst = System.currentTimeMillis();
long beginTimestampPrev ;
//2、去服务器看下有没有主题消息
TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic());
if (topicPublishInfo != null && topicPublishInfo.ok()) {
boolean callTimeout = false;
//3、通过这里可以很明显看出 如果不是同步发送消息 那么消息重试只有1次
int timesTotal = communicationMode == CommunicationMode.SYNC ? 1 + this.defaultMQProducer.getRetryTimesWhenSendFailed() : 1;
//4、根据设置的重试次数,循环再去获取服务器主题消息
for (times = 0; times < timesTotal; times++) {
MessageQueue mqSelected = this.selectOneMessageQueue(topicPublishInfo, lastBrokerName);
beginTimestampPrev = System.currentTimeMillis();
long costTime = beginTimestampPrev - beginTimestampFirst;
//5、前后时间对比 如果前后时间差 大于 设置的等待时间 那么直接跳出for循环了 这就说明连接超时是不进行多次连接重试的
if (timeout < costTime) {
callTimeout = true;
break;
}
//6、如果超时直接报错
if (callTimeout) {
throw new RemotingTooMuchRequestException("sendDefaultImpl call timeout");
}
}
}
异步发送消息和回调实战
• 官方文档
@RestController
public class PayController {
@Autowired
private PayProducer payProducer;
private static final String topic = "test_pay_topic_1";
@RequestMapping("/test/pay_cb")
public Object callBack(String text) throws Exception {
Message message = new Message(topic, "tag_1", "keyssssss", ("test=" + text).getBytes());
/**
* 异步发送
*/
//回调函数
payProducer.getProducer().send(message, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
System.out.printf("发送结果=%s,body=%s\n", sendResult.getSendStatus(), sendResult);
}
@Override
public void onException(Throwable e) {
//补偿机制,根据业务情况进行使用,看是否进行重试
}
});
return "发送成功!";
}
}
• 注意:官方例子:如果异步发送消息,调用producer.shutdown()后会失败
OneWay发送消息及多种场景对比
・ SYNC :
应用场景:重要通知邮件、报名短信通知、营销短信系统等
ASYNC :异步
。应用场景:对RT时间敏感,可以支持更高的并发,回调成功触发相对应的业务,比如
注册成功 后通知积分系统发放优惠券
ONEWAY :无需要等待响应
官方文档:https://rocketmq.apache.org/docs/simple-example/
使用场景:主要是日志收集,适用于某些耗时非常短,但对可靠性要求并不高的场景,
也就是 LogServer,只负责发送消息,不等待服务器回应且没有回调函数触发,即只
发送请求不等待应答
//OneWay发送
payProducer.getProducer().sendOneway(message);
• 汇总对比

延迟消息实战和电商系统中应用
• 延迟消息
Producer将消息发送到消息队列RocketMQ服务端,但并不期望这条消息立马投递,而是
推 迟到在当前时间点之后的某一个时间投递到Consumer进行消费,该消息即定时消息,
目前 支持固定精度的消息
• 源码位置
rocketmq-store > MessageStoreConfig.java 属性 messageDelayLevel
"1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
• 使用message.setDelayTimeLevel(xxx) //xxx是级别,1表示配置里面的第一个级别,2表示第 二个级别
Message message = new Message(topic, "tag_1","".getBytes());
/**设置延迟消息级别,此时间是延迟消费时间,不是发送时间
* 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
*/
message.setDelayTimeLevel(2);
• 使用场景
。通过消息触发一些定时任务,比如在某一固定时间点向用户发送提醒消息
。消息生产和消费有时间窗口要求:比如在天猫电商交易中超时未支付关闭订单的场景,
在订单创建时会发送一条延时消息。这条消息将会在30分钟以后投递绐消费者,消费者
收到此消息后需要判断对应的订单是否已完成支付。如支付未完成,则关闭订单。如已
完成支付则忽略
MessageQueueSelector 实战
•生产消息使用MessageQueueSelector投递到Topic下指定的queue
•应用场景:顺序消息,分摊负载
•默认topic下的queue数量是4,可以配置
•支持同步,异步发送指定的M essageQueue
•选择的queue数量必须小于配置的,否则会出错
@RequestMapping("/test2")
public Object callBack2(String text) throws Exception {
Message message = new Message(topic, "tag_1", "keyssssss", ("test=" + text).getBytes());
/**
* 同步发送
*/
payProducer.getProducer().send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
int i = Integer.parseInt(arg.toString());
System.out.println("i=" + i + "---msg=" + msg + "---mqs=" + mqs.get(i));
return mqs.get(i);
}
}, 0);//第几个Queue,默认共4个,0123
/**
* 异步发送
*/
payProducer.getProducer().send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
int i = Integer.parseInt(arg.toString());
return mqs.get(i);
}
//第几个Queue,默认共4个,0123
}, 0, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
System.out.printf("发送结果=%s,body=%s\n", sendResult.getSendStatus(), sendResult);
}
@Override
public void onException(Throwable e) {
}
});
return "发送成功!";
}
顺序消息详解与实际应用模拟操作
• 顺序消息:
消息的生产和消费顺序一致
全局顺序:
topic下面全部消息都要有序(少用)
性能要求不高,所有的消息严格按照FIFO(先进先出)原则进行消息发布和消费的场景,并行度成为消息系统的瓶颈,吞吐量不够
局部顺序:
只要保证一组消息被顺序消费即可(RocketMQ使用)
性能要求高,电商的订单创建,同一个订单相关的创建订单消息、订单支付消息、订单退款消息、订 单物流消息、订单交易成功消息都会按照先后顺序来发布和消费(阿里巴巴集团内部电商系统均使用局部顺序消息,既保证业务的顺序,同时又能保证 业务的高性能)
• 顺序发布:
对于指定的一个Topic,客户端将按照一定的先后顺序发送消息
• 顺序消费:
对于指定的一个Topic,按照一定的先后顺序接收消息,即先发送的消息一定会先被客 户端接收到
• 注意:
顺序消息暂不支持广播模式
顺序消息不支持异步发送方式,否则将无法严格保证顺序
• Order顺序执行之生产端模拟操作
生产端保证发送消息有序,且发送到同一个Topic的同个queue里面.
例子:订单的顺序流程是:创建、付款、物流、完成,订单号相同的消息会被先后发送到同 —个队列中, 根据MessageQueueSelect or里面自定义策略,根据同个业务id放置到同个queue里面,如订单号取模运算再放到selector中,同一个模的值都会投递到同一条queue
消费端要在保证消费同个topic里的同个队列,不应该使用MessageListenerConcurrently,应该使用MessageListenerOrderly,自带单线程消费消息,不能再Consumer端再使用多线程去消 费,消费端分配到的q ueue数量是固定的,集群消会锁住当前正在消费的队列集合的消息,所以会保证顺序消费。
• 官方例子
@RestController
public class PayOrdersProducer {
@Autowired
private PayProducer payProducer;
private static final String topic = "test_order_topic_1";
@RequestMapping("/orderly_1")
public Object demo_1() throws Exception {
List<ProductOrder> orderList = ProductOrder.getOrderList();
for (int i = 0; i <orderList.size() ; i++) {
ProductOrder productOrder = orderList.get(i);
Message message = new Message(topic, "tags",productOrder.getOrderId()+"",productOrder.toString().getBytes());
SendResult sendResult = payProducer.getProducer().send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
//保证不超过最大Queue,且每个订单号所在的队列相同
Long id = (Long) arg;
long index = id % mqs.size();
return mqs.get((int) index);
}
}, productOrder.getOrderId());
System.out.printf("发送结果=%s, sendResult=%s ,orderid=%s, type=%s\n", sendResult.getSendStatus(), sendResult.toString(),productOrder.getOrderId(),productOrder.getType());
}
return "发送成功!";
}
}
• Order顺序执行之消费端模拟操作
Consumer会平均分配queue的数量
并不是简单禁止并发处理,而是为每个consumer Quene加个锁,消费每个
消息前,需要获得这个消息所在的Queue的锁,这样同个时间,同个Queue的
消息不被并发消费,但是不同Queue的消息可以并发处理
@Component
public class PayOrdersConsumer {
private static final String topic = "test_order_topic_1";
//Group不能重复
private String consumerGroup = "pay_order_consumer_group";
private String nameServiceAddr = "119.23.43.244:9876";
private DefaultMQPushConsumer consumer;
public PayOrdersConsumer() throws MQClientException {
consumer = new DefaultMQPushConsumer(consumerGroup);
consumer.setNamesrvAddr(nameServiceAddr);
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
consumer.subscribe(topic, "*");
//MessageListenerOrderly单线程启动消费者,加锁机制
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
MessageExt msg = msgs.get(0);
try {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), new String(msg.getBody()));
//做业务逻辑操作 TODO......
//成功消费
return ConsumeOrderlyStatus.SUCCESS;
} catch (Exception e) {
e.printStackTrace();
//暂时停止,时间段之后重试
return ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT;
}
}
});
consumer.start();
System.out.println("consumer start ...");
}
}
• 控制台输出:
同一个步骤的生产消息的queueId和queueOffset是一样的
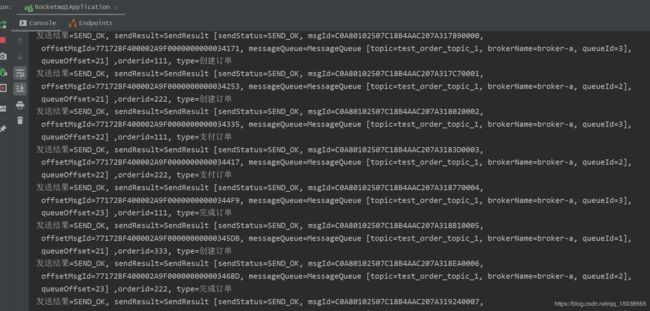
同一个步骤的消费线程是一样的
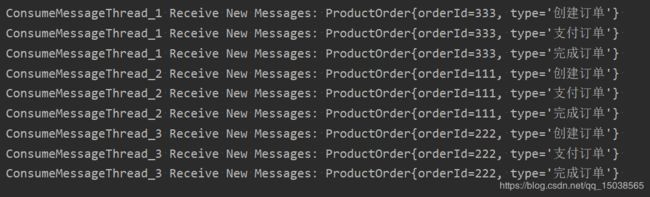
消费者核心配置和核心知识
消费者核心配置
失效参考
consumeFromWhere配置(某些情况失效)
。CONSUME_FROM_FIRST_OFFSET:初次从消息队列头部开始消费,即历史消息(还储
存在broker的)全部消费一遍,后续再启动接着上次消费的进度开始消费
。CONSUME_FROM丄AST_OFFSET:默认策略,初次从该队列最尾开始消费,即跳过历史
消息,后续再启动接着上次消费的进度开始消费
。CONSUME_FROM_TIMESTAMP :从某个时间点开始消费,默认是半个小时以前,后续再
启动接着上次消费的进度开始消费
allocateMessageQueueStrategy
。负载均衡策略算法,即消费者分配到queue的算法,默认值是
AllocateMessageQueueAveragely即取模平均分配
offsetStore
。消息消费进度存储器offsetStore有两个策略:
LocalFileOffsetStore和RemoteBrokerOffsetStor
广播模式默认使用LocalFileOffsetStore
集群模式默认使用RemoteBrokerOffsetStore
consumeThreadMin
。最小消费线程池数量
consumeThreadMax
。最大消费线程池数量
pullBatchSize
。消费者去broker拉取消息时,一次拉取多少条。可选配置
consumeMessageBatchMaxSize
。单次消费时一次性消费多少条消息,批量消费接口才有用,可选配置
messageModel
。消费者消费模式
。CLUSTERING(集群模式)和BROADCASTING(广播模式)
。默认是集群模式CLUSTERING
两种消费方式
集群模式(默认)
Consumer实例平均分摊消费生产者发送的消息
例子:订单消息,一般是只被消费一次
consumer.setMessageModel(MessageModel.CLUSTERING);
广播模式:
广播模式下消费消息:投递到Broke啲消息会被每个Consumer进行消费,一条消息被多个
Consumer消费,广播消费中C onsumerGroup暂时无用
例子:群公告,每个人都需要消费这个消息
consumer.setMessageModel(MessageModel.BROADCASTING);
Topic下队列的奇偶数会影响Customer个数里面的消费数量
°如果是4个队列,8个消息,4个节点则会各消费2条,如果不对等,则负载均衡会
分配不均,
°如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer
实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用,所以需要
控制让queue的总数量大于等于consumer的数量
标签Tag详解和消息过滤原理
• 一个Message只有一个Tag, tag是二级分类
• 过滤分为Broker端和Consumer端过滤
。Broker端过滤,减少了无用的消息的进行网络传输,增加了broker的负担
。Consumer端过滤,完全可以根据业务需求进行实习,但是增加了很多无用的消息传输
• 一般是监听*,或者指定tag, ||运算,SLQ92 , FilterServer等…
tag性能高,逻辑简单
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(producerGroup);
consumer.subscribe(topic, "*");
consumer.subscribe(topic, "aaa | bbb | ccc");
SQL92性能差点,支持复杂逻辑(只支持PushConsumer中使用)MessageSelector.bySql
语法:> ,< =,IS NULL, AND, OR, NOT等,sql where后续的语法即可(大部分)
Message message = new Message(topic, "tag_1","".getBytes());
message.putUserProperty("ago","18");
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(producerGroup);
//根据SQL语法进行过滤
consumer.subscribe(topic, MessageSelector.bySql("ago > 18"));
• 注意:
。消费者订阅关系要一致,不然会消费混乱,甚至消息丢失
。订阅关系一致:订阅关系由Topic和Tag组成,同一个group name,订阅的topic和tag必须是一样的
• 过滤原理:
在Broker端进行MessageTag过滤,遍历message queue存储的message tag和订阅传递的tag的 hashcode不一样则跳过,符合的则传输绐Consumer,在consumer queue存储的是对应的 hashcode,对比也是通过hashcode对比;Consumer收到过滤消息后也会进行匹配操作,但是是对比真实的message tag而不是hashcode(防止Hash碰撞)
。consume queue存储使用hashcode定长,节约空间
。过滤中不访问commit log,可以.高效过滤
。如果存在hash冲突,Consumer端可以进行再次确认
如果想使用多个Tag,可以使用sql表达式,但是不建议,单一职责,多个队列
常见错误:
The broker does not support consumer to filter message by SQL92
解决:broker.conf里面配置如下
enablePropertyFilter=true
备注,修改之后要重启Broker
master节点配置: vim conf/2m-2s-async/broker-a.properties
slave节点配置: vim conf/2m-2s-async/broker-a-s.properties
PushConsumer、PullConsumer消费模式分析
• Push和Pull优缺点分析
Push
・实时性高;但增加服务端负载,消费端能力不同,如果Push推送过快,消费端会出现
很多问题
Pull
・消费者从Server端拉取消息,主动权在消费者端,可控性好;但间隔时间不好设置,
间 隔太短,则空请求,浪费资源;间隔时间太长,则消息不能及时处理
长轮循
・Client请求Server端也就是Broker的时候,Broker会保持当前连接一段时间默认是
15s,如果这段时间内有消息到达,则立刻返回绐Consumer.没消息的话超过15s,则返
回 空,再进行重新请求;主动权在Consumer中,Broker即使有大量的消息也不会主动
提送 Consumer,缺点:服务端需要保持C onsumer的请求,会占用资源,需要客户端连
接数可控 否则会一堆连接
• PushConsumer本质是长轮循
系统收到消息后自动处理消息和offset,如果有新的Consumer加入会自动做负载均衡
。在broker端可以通过longPollingEnable=true来开启长轮询
。消费端代码:DefaultMQPushConsumerlmpl->pullMessage->PullCallback
。服务端代码:broker.longpolling
。虽然是push,但是代码里面大量使用了pull,是因为使用长轮训方式达到Push效果,
既有pull 有的,又有Push的实时性
。优雅关闭:主要是释放资源和保存Offset,调用shutdown。即可,参考
@PostConstruct、 @PreDestroy
• PullConsumer(需要自己维护Offset参考官方例子)
官方例子路径:org.apache.rocketmq.example.simple.PullConsumer
。获取MessageQueue遍历
。客户维护Offset,需用用户本地存储Offset,存储内存、磁盘、数据库等
。处理不同状态的消息 FOUND、NO_NEW_MSG、OFFSET_ILLRGL、 NO_MATCHED_MSG、4种状态
。灵活性高可控性强,但是编码复杂度会高
。优雅关闭:主要是释放资源和保存Offset,需用程序自己保存好Offset,特别是异常处理的时候
消息偏移量0ffset
• Offset
message queue是无限长的数组,一条消息进来下标就会涨1,下标就是offset,消息在某个 MessageQueue里的位置,通过offset的值可以定位到这条消息,或者指示Consumer从这条消息开始向后处理
message queue中的maxOffset表示消息的最大offset, maxOffset并不是最新的那条消息的 offset,而是最新消息的offset+1, minOffset则是现存在的最小offset。
fileReserveTime=48默认消息存储48小时后,消费会被物理地从磁盘删除,message queue 的min offset也就对应增长。所以比minOffset还要小的那些消息已经不在broker上了,就无法被消费
• 类型(父类是0ffsetStore)
本地文件类型
DefaultMQPushConsumer的BROADCASTING(广播)模式,各个Consumer 没有互相干扰,使用
LoclaFileOffsetStore,把Offset存储在本地
Broker代存储类型
DefaultMQPushConsumer的CLUSTERING(集群)模式,由Broker端存储和控制Offset的值,使用
RemoteBrokerOffsetStore
• 用处
。主要是记录消息的偏移量,有多个消费者进行消费
。集群模式下采用RemoteBrokerOffsetStore, broker控制offset的值
。广播模式下采用LocalFileOffsetStore,消费端本地存储
建议采用pushConsumer, RocketMQ自动维护OffsetStore,如果用pullConsumer需要自己进行维护OffsetStore
消息存储之CommitLog和ConsumerQueue
消息存储是由C onsumeQueue和CommitLog配合完成
• ConsumeQueue:
逻辑队列,CommitLog是真正存储消息文件的,存储的是指向物理存储的地址Topic下的每个message queue都有对应的ConsumeQueue文件,内容也会被持久化到磁盘,默认地址:store/consumequeue/{topicName}/{queueid}/fileName
• CommitLog:
消息文件的真正物理存储地址
生成规则: 每个文件的默认1G =1024 *1024 *1024, commitlog的文件名fileName,名字长 度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了 第一个文件,起始偏移量为0,文件大小为1G=1 073 741 824Byte;当这个文件满 了,第二个文件名字为00000000001073741824,起始偏移量为
1073741824,消 息存储的时候会顺序写入文件,当文件满了则写入下一个文件
判断消息存储在哪个CommitLog上: 例如1073742827为物理偏移量,则其对应的相对偏移量为1003 = 1073742827 - 1073741824,并且该偏移量位于第二个CommitLog。
Broker 里面一个 Topic
里面有多个MesssageQueue
每个 MessageQueue 对应一个 ConsumeQueue
ConsumeQueue里面记录的是消息在CommitLog里面的物理存储地址
高性能分析之ZeroCopy零拷贝技术
• 高效原因
CommitLog顺序写,存储了MessagBody、message key、tag等信息
ConsumeQueue随机读+操作系统的PageCache +零拷贝技术ZeroCopy
• 普通拷贝与零拷贝技术
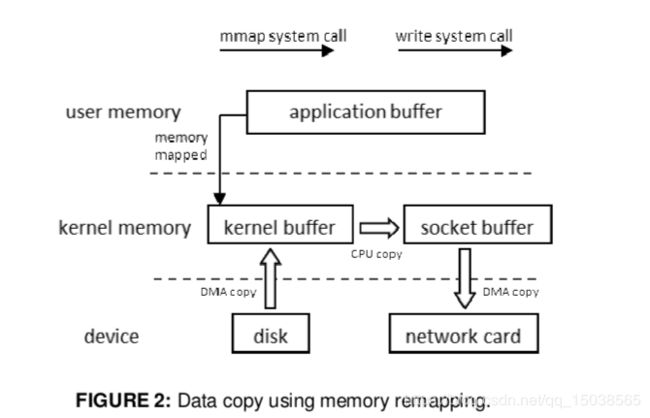
普通拷贝
例子:将一个File读取并发送出去(Linux有两个上下文,内核态,用户态)
File文件的经历了4次copy-调用read,将文件拷贝到了kernel内核态
CPU控制kernel态的数据copy到用户态
调用write时,user态下的内容会copy到内核态的socket的buffer中 -最后将内核态socket buffer的数据copy到网卡设备中传送
缺点:增加了上下文切换、浪费了2次无效拷贝

ZeroCopy
请求kerneI直接把disk的data传输绐socket,而不是通过应用程序传输。Zero copy 大大提高了应用程序的性能,减少不必要的内核缓冲区跟用户缓冲区间的拷贝,从 而减少CPU的开销和减少了 kernel和u ser模式的上下文切换,达到性能的提升
对应零拷贝技术有mmap及sendfile
-mmap:小文件传输快
-RocketMQ选择这种方式,mmap+write方式,小块数据传输,效果会 比sendfile更好
sendfile:大文件传输比m map快
Java 中的 TransferTo 0 实现 了Zero-Copy
应用:Kafka、Netty、RocketMQ等都采用了零拷贝技术
分布式事务消息
介绍
• 分布式事务
。来源:单体应用一>拆分为分布式应用
。一个接口需要调用多个服务,且操作不同的数据库,数据一致性难保障
• 常见解决方案
。2PC :两阶段提交,基于XA协议
。TCC : Try、Confirm、Cancel
。事务消息最终一致性:
。…
• 框架
GTS -> 开源 Fescar
LCN
总体架构
• RocketMQ事务消息
RocketMQ提供分布事务功能,通过RocketMQ事务消息能达到分布式事务的最终一致
• 半消息Half Message
暂不能投递的消息(暂不能消费),Producer已经将消息成功发送到了Broker端,但是服务端未 收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”状态,处于该种状态下的消息即半消息
• 消息回查
由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,消息队列 RocketMQ服务端通过扫描发现某条消息长期处于“半消息”时,需要主动向消息生产者询问 该消息的最终状态(Commit或是Rollback),该过程即消息回查
• 整体交互流程

。Producer向broker端发送消息。
。服务端将消息持久化成功之后,向发送方ACK确认消息已经发送成功,此时消息为半消息。 。发送方开始执行本地事务逻辑。
。发送方根据本地事务执行结果向服务端提交二次确认(Commit或是Rollback),服务端收 到Commit状态则将半消息标记为可投递,订阅方最终将收到该消息;服务端收到Rollback 状态则删除半消息,订阅方将不会接受该消息
。在断网或者是应用重启的特殊情况下,上述步骤4提交的二次确认最终未到达服务端,经过 固定时间后服务端将对该消息发起消息回查
。发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果
。发送方根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半消息进行操作
• RocketMQ事务消息的状态
。COMMIT_MESSAGE:提交事务消息,消费者可以消费此消息
。ROLLBACK_MESSAGE:回滚事务消息,消息会在broker中删除,消费者不能消费
。UNKNOW: Broker需要回查确认消息的状态
• 关于事务消息的消费
事务消息consumer端的消费方式和普通消息是一样的,RocketMQ能保证消息能被consumer收到(消息重试等机制,最后也存在consumer消费失败的情况,这种情况出现的概率极低)
分布式事务消息实战
Producer设计
@Component
public class TransactionProducer {
private String producerGroup = "transaction_producer_group";
private String nameServiceAddr = "119.23.43.244:9876";
private TransactionMQProducer producer;
//创建事务监听器,用来监听事务状态
private TransactionListener transactionListener = new TransactionListenerImpl();
//创建线程池,回查事务状态需要线程池
private ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 5,
100, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName("test_transaction");
return thread;
}
});
public TransactionProducer() {
producer = new TransactionMQProducer(producerGroup);
//把事务监听器添加进去
producer.setTransactionListener(transactionListener);
producer.setNamesrvAddr(nameServiceAddr);
//把线程池添加进去
producer.setExecutorService(threadPoolExecutor);
start();
}
public TransactionMQProducer getProducer() {
return producer;
}
/**
* 对象在使用之前必须要调用一次,只能初始化一次
*/
public void start() {
try {
producer.start();
} catch (MQClientException e) {
e.printStackTrace();
}
}
/**
* 一般在应用上下文,使用上下文监听器,进行关闭消息队列连接操作
*/
public void shutdown() {
producer.shutdown();
}
private class TransactionListenerImpl implements TransactionListener {
@Override
//执行本地事务,进行二次确认
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
System.out.println("--------------------executeLocalTransaction-----------------");
String body = new String(msg.getBody());
String keys = msg.getKeys();
String transactionId = msg.getTransactionId();
System.out.println("body="+body+"---keys="+keys+"---reansactionId="+transactionId);
String state = arg.toString();
/**
* 执行本地事务开始
* 执行本地事务结束
*/
//提交事务,二次确认成功,消息可被消费
if ("666".equalsIgnoreCase(state)){
return LocalTransactionState.COMMIT_MESSAGE;
}
//回滚事务,二次确认失败,消息被删除
if ("777".equalsIgnoreCase(state)){
return LocalTransactionState.ROLLBACK_MESSAGE;
}
//回查消息状态
if ("888".equalsIgnoreCase(state)){
return LocalTransactionState.UNKNOW;
}
return null;
}
@Override
//回查消息,服务器宕机也会回查,只要没经过二次确认
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
System.out.println("--------------------checkLocalTransaction-----------------");
String body = new String(msg.getBody());
String keys = msg.getKeys();
String transactionId = msg.getTransactionId();
System.out.println("body="+body+"---keys="+keys+"---reansactionId="+transactionId);
//要么Commit要么Rollback
//可以根据key去检查本地事务消息是否完成
return null;
}
}
}
生产者执行
@RestController
public class TransactionController {
@Autowired
private TransactionProducer producer;
private static final String topic = "test_transaction_topic_1";
@RequestMapping("/transaction_1")
public Object callBack1(String text) throws Exception {
Message message = new Message(topic, "tag_1", ("test=" + text).getBytes());
//第二个参数是二次确认消息需要的标识
SendResult send = producer.getProducer().sendMessageInTransaction(message,text);
System.out.println(send);
return "发送成功!";
}
}
消费者设计
@Component
public class TransactionConsumer {
private static final String topic = "test_transaction_topic_1";
private String producerGroup = "transaction_consumer_group";
private String nameServiceAddr = "119.23.43.244:9876";
private DefaultMQPushConsumer consumer;
public TransactionConsumer() throws MQClientException {
consumer = new DefaultMQPushConsumer(producerGroup);
consumer.setNamesrvAddr(nameServiceAddr);
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.subscribe(topic, "*");
//注册消费者监听器,有消息到来就触发函数
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
MessageExt m = msgs.get(0);
try {
System.out.println("线程名称:" + Thread.currentThread().getName() + "---消息体为:" + new String(m.getBody()));
String topic = m.getTopic();
String tags = m.getTags();
String keys = m.getKeys();
String body = new String(m.getBody(), "utf-8");
System.out.println("topic=" + topic + "---tags=" + tags + "---keys=" + keys + "---body=" + body);
System.out.println("消息已成功消费!");
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
});
consumer.start();
System.out.println("Transaction消费者启动成功!");
}
}
当执行链接携带参数text值为666:
成功生产并成功消费
当执行链接携带参数text值为777:
成功生产再删除,不会消费
当执行链接携带参数text值为888:
成功生产,消费还是删除具体看回查情况
面试专题
为什么使用消息队列,怎么选择技术
异步
解耦
削峰
• 缺点:
。系统可用性越低:外部依赖越多,依赖越多,出问题风险越大
。系统复杂性提高:需要考虑多种场景,比如消息重复消费,消息丢失
。需要更多的机器和人力:消息队列一般集群部署,而且需要运维和监控,例如topic申请等
选择问题:ActiveMQ、Kafka、RabbitMQ、RocketMQ,查看前面章节
消息怎么避免重复消费
RocketMQ不保证消息不重复,如果你的业务需要保证严格的不重复消息,需要你自己在业务端去重
接口幂等性保障,消费端处理业务消息要保持幂等性
Redis
setNXO ,做消息id去重java版本目前不支持设置过期时间
//redis中操作,判断是否已经操作过
boolean flasg=jedis.setNX(key);
if(flag){
//消费
}else{
//忽略,重复消费
}
拓展(如果再用expire则不是原子操作,可以用下面方式实现分布式锁)
加锁
String result = jedis.set(key, value, "NX", "PX", expireTime)
解锁(Lua脚本,先检查key,匹配再释放锁,lua可以保证原子性)
String script = "if redis.call('get', KEYS[1]) == ARGV[1]
then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script,
Collections.singletonList(lockKey),
Collections.singletonList(requestId));
备注:lockKey可以是商品id,requestId用于标示是同个客户端
Incr原子操作:key自增,大于0返回值大于0则说明消费过
int num=jedis.incr(key);
if(num==1){
//消费
}else{
//忽略,重复消费
}
上述两个方式都可以,但是不能用于分布式锁,考虑原子问题,但是排重可以不考虑原子
问题,数据量多需要设置过期时间
数据库去重表
某个字段使用Message的key做唯一索引
如何保证消息的可靠性传输
• producer 端
。不采用oneway发送,使用同步或者异步方式发送,做好重试,但是重试的Message key必须 唯一
。投递的日志需要保存,关键字段,投递时间、投递状态、重试次数、请求体、响应体
• broker 端
。双主双从架构,NameServer需要多节点
。同步双写、异步刷盘(同步刷盘则可靠性更高,但是性能差点,根据业务选择)
• consumer 端
。消息消费务必保留日志,即消息的元数据和消息体
。消费端务必做好幂等性处理
• 投递到broker端后
。机器断电重启:异步刷盘,消息丢失;同步刷盘消息不丢失
。硬件故障:可能存在丢失,看队列架构
消息发生大量堆积应该怎么处理
。消息堆积了10小时,有几千万条消息待处理,现在怎么办?
。修复consumer,然后慢慢消费?也需要几小时才可以消费完成,新的消息怎么办?
• 正确的姿势
。临时topic队列扩容,并提高消费者能力,但是如果增加Consumer数量,但是堆积的topic里面的 message queue数量固定,过多的Consumer不能分配到message queue
。编写临时处理分发程序,从旧topic快速读取到临时新topic中,新topic的queue数量扩容多倍,然后再启动更多consumer进行在临时新的topic里消费
RocketMQ高性能的原因分析
• MQ架构配置
。顺序写,随机读,零拷贝
。同步刷盘SYNC_FLUSH和异步刷盘ASYNC_FLUSH,通过flushDiskType配置
。同步复制和异步复制,通过brokerRole配置,ASYNC_MASTER, SYNC_MASTER, SLAVE
。推荐同步复制(双写),异步刷盘
• 发送端高可用
。双主双从架构:创建Topic对应的时候,MessageQueue创建在多个Broker上,即相同的Broker名称,不同的brokerId(即主从模式);当一个Master不可用时,组内其他的 Master仍然可用。
。但是机器资源不足的时候,需要手工把slave转成master,目前不支持自动转换,可用shell处理
• 消费高可用
。主从架构:Broker角色,Master提供读写,Slave只支持读
。Consumer不用配置,当Master不可用或者繁忙的时候,Consumer会自动切换到Slave节点进行能读取
• 提高消息的消费能力
并行消费:
。增加单个 Consumer 的并行度,修改 consumerThreadMin 和ConsumerThreadMax
。批量消费,设置Consumer的consumerMessageBatchMaxSize,默认是1,如果为N,则消息多的时候,每次收到的消息为N条
选择LinuxExt4文件系统,Ext4文件系统删除1G大小的文件通常耗时小于50ms,而Ext3文件系统耗时需要1s,删除文件时磁盘IO压力极大,会导致IO操作超时
文章持续更新,可以微信搜索「 绅堂Style 」第一时间阅读,回复【资料】有我准备的面试题笔记。
GitHub https://github.com/dtt11111/Nodes 有总结面试完整考点、资料以及我的系列文章。欢迎Star。
