Leetcode 30:与所有单词相关联的字串(超详细的解法!!!)
给定一个字符串 s 和一些长度相同的单词 **words。**在 s 中找出可以恰好串联 words 中所有单词的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出: [0,9]
解释: 从索引 0 和 9 开始的子串分别是 "barfoor" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = "wordgoodstudentgoodword",
words = ["word","student"]
输出: []
解题思路
我们首先想到的解法当然是暴力破解。我们将words的所有排列情况列出来,为了避免重复元素,我们应该使用一个set去存放结果。然后我们遍历set中的所有元素,查看元素在s中的位置,并将位置存放到list中。
class Solution:
def findSubstring(self, s, words):
"""
:type s: str
:type words: List[str]
:rtype: List[int]
"""
res = list()
if not words:
return res
for word in set(itertools.permutations(words)):
tmp_word = ''.join(word)
i = s.find(tmp_word)
while i != -1:
res.append(i)
i = s.find(tmp_word, i + 1)
return res
提交代码后提示我们Memory Limit Exceeded。我们遗漏了一个条件长度相同的单词 words。所以我们就有了如下的策略,我们可以先将words中的元素存放到dict中,对于例1来说就是
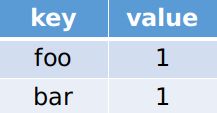
此时我们的目标就是匹配dict中的所有字符串,我们从头开始
我们发现此时匹配了bar,所以我们此时应该移动len(words[0])的步数
我们发现此时foo也匹配了,所以此时dict中的全部元素都匹配成功,我们就要记录开始的index=0。我们现在从index=1开始匹配
我们发现第一个字符串就匹配失败,我们接着从index=2开始也是失败,我们接从index=3开始
我们发现此时第一个匹配成功,所以我们此时应该移动len(words[0])
我们发现此时匹配失败,所以我们就要从index=4,依次往后。
class Solution:
def findSubstring(self, s, words):
"""
:type s: str
:type words: List[str]
:rtype: List[int]
"""
if not words:
return []
words_dict = collections.defaultdict(int)
for word in words:
words_dict[word] += 1
s_len, words_len, word_len, res = len(s), len(words), len(words[0]), list()
for i in range(s_len - words_len*word_len + 1):
num, has_words = 0, collections.defaultdict(int)
while num < words_len:
word = s[i+num*word_len:i+(num+1)*word_len]
if word not in words_dict:
break
has_words[word] += 1
if has_words[word] > words_dict[word]:
break
num += 1
if num == words_len:
res.append(i)
return res
上述代码提交后就获得了accept。你可能已经注意到了上述算法中存在的一些缺陷,例如当我们的words很长时,我们n-1个word都匹配成功了,但是就最后一个匹配失败,我们就要index++开始,实际上这是有问题的,我们此时应该继续从失败的单词后继续开始匹配,直到这一轮匹配完再从index++开始,例如
我们发现此时匹配失败,我们应该从the后,也就是foo开始将剩余部分匹配完。
这样我们就充分利用了我们之前存储的信息。为了更好地说明问题,我们取这样的一个例子s = "barfoobarfoobarfoofoo",words = ["foo","bar","foo"]。我们来看一下具体实现步骤

我们发现此时匹配到了一个单词bar,所以此时我们前进len(words[0])步,并且将此时匹配到的单词加入到一个临时的字典中存放。

我们发现此时匹配到了一个单词foo,所以此时我们前进len(words[0])步,并且将此时匹配到的单词加入到一个临时的字典中存放。

我们发现此时匹配到了一个单词bar,但是此时bar的数量已经超过了words中的,所以我们此时要将第一个bar弹出。

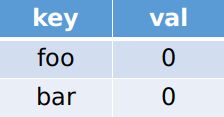
我们发现此时匹配到的单词the不在words中,所以此时我们前进len(words[0])步,并且将临时字典清空。
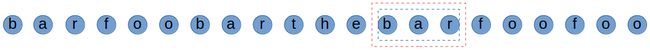
我们发现此时匹配到了一个单词bar,所以此时我们前进len(words[0])步,并且将此时匹配到的单词加入到一个临时的字典中存放。
我们发现此时匹配到了一个单词foo,所以此时我们前进len(words[0])步,并且将此时匹配到的单词加入到一个临时的字典中存放。

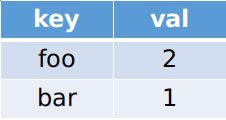
我们发现此时匹配到了一个单词foo,并且将此时匹配到的单词加入到一个临时的字典中存放,我们发现此时多有单词匹配成功,我们就将index=12加入到我们的结果中。接着我们再从index=1...len(words[0])-1开始遍历即可。代码如下
class Solution:
def findSubstring(self, s, words):
"""
:type s: str
:type words: List[str]
:rtype: List[int]
"""
if not words:
return []
words_dict = collections.defaultdict(int)
for word in words:
words_dict[word] += 1
s_len, words_len, word_len, res = len(s), len(words), len(words[0]), list()
for k in range(word_len):
has_words, num = collections.defaultdict(int), 0
for i in range(k, s_len, word_len):
word = s[i:i + word_len]
if word in words_dict:
num += 1
has_words[word] += 1
while has_words[word] > words_dict[word]:
pos = i - word_len*(num - 1)
rem_word = s[pos:pos + word_len]
has_words[rem_word] -= 1
num -= 1
else:
has_words.clear()
num = 0
if num == words_len:
res.append(i - word_len*(num - 1))
return res
我将该问题的其他语言版本添加到了我的GitHub Leetcode
如有问题,希望大家指出!!!