编译过程和ELF文件
目录
一、C/C++编译过程
二、ELF文件
三、符号解析和重定位
四、静态链接和动态链接
一、C/C++编译过程
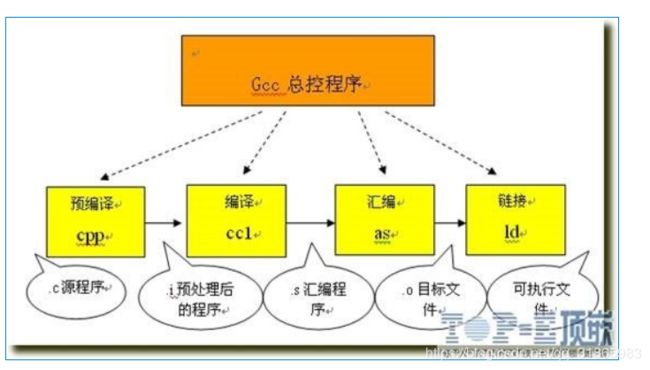
C/C++程序从源代码到可执行文件需要经理预处理(预编译),编译,汇编,链接四个过程:
1、预处理:对源代码中的伪指令(以# 开头的指令)和特殊符号进行处理,如#include指令,预处理会将对应的头文件(即.h文件,声明全局变量和函数,相当于java中的接口类)写入到源代码文件(即.c文件,包含函数的具体实现)。预处理后生成的是.i后缀结尾的文件,依然是文本文件。
2、编译:对预处理结果文件做词法和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码,翻译过程中会执行两种通用的编译优化,一种是代码层面的如代码外提,复制传播等,一种是跟硬件强相关的优化,包括选择更高效的机器指令,合理分配和指派寄存器,具体优化内容可参考《编译原理》,可通过gcc的参数指定优化的强度,通常优化强度越高编译越慢。因为寄存器的种类和数量是取决于CPU架构的,通常只有对应架构下的汇编指令可以直接操作寄存器,C语言中有register关键字请求编译器尽量将某个变量放入寄存器中,但是最终是否放入寄存器由编译器根据硬件环境决定。编译过程产生的文件还是文本文件,以.s结尾,该文件是对应平台下的翻译出的汇编代码。
3、汇编:指把汇编语言代码翻译成目标机器指令的过程,该过程相对简单,将对应的汇编指令替换成数字形式的指令码即可。汇编完成后生成的文件以.o结尾,通常是可重定位目标文件。
4、链接: 编译时是以单个.c文件为单位编译的,所以会产生多个.o文件,将多个.o文件与之依赖的共享库如libc链接在一起形成可执行文件,可执行文件的后缀可以是out或者elf。Linux加载可执行文件过程中不会校验文件后缀而校验是否符合ELF文件格式。
上述每一步操作都可以通过gcc命令单独触发,整体的过程如下图:
参考: C语言编译过程详解
C/C++程序编译过程详解
二、ELF文件
ELF全称Executable and Linkable Format,即可执行和可链接的格式,是UNIX系统实验室(USL)为应用程序二进制接口(Application Binary Interface,ABI)而开发和发布的,是所有类UNIX系统的主要可执行文件格式,windows系统对应的可执行文件格式简称PE,两者都是COFF格式的变种。
Linux上的ELF文件主要有三种:
1、可重定向文件,即通过汇编产生的文件,后缀是.o,该文件不能直接运行,
2、可执行文件,将多个可重定向文件和共享库文件通过链接产生,可以直接运行
3、共享库,如libc的共享库libc.so,该文件同样不能直接运行,同可重定向文件相比,最大的区别在于该文件不需要经过重定向处理。
ELF文件的格式如下:

- ELF header: 描述整个文件的组织,包含ELF文件类型,硬件平台类型,程序执行入口, sections和segments的数量和起始偏移位置,大小等。
- Program Header Table: 描述文件中的各种segments,通常一个segment包含若干个属性(如读写权限等)相同的section,将section合并成segment是为了减少内存空间浪费,方便内存管理,section的大小是任意的,但是segment的大小必须是所在操作系统的内存页(如4KB)大小的整数倍。操作系统加载可执行文件时会把LOAD类型的segment映射至虚拟地址空间。可重定向文件中没有此项,只有可执行文件中才有。
- sections 或者 segments:具体的sections,sections是将汇编代码文件中的各种数据做归类保存,方便对其做内存分配与管理, 如.text section是可执行指令的集合,.data section包含初始化的全局变量,.bss section保存的是未初始化的全局变量和局部静态变量,.dynsym section记录了所有需要重定向处理的符号等。segments是从程序加载和运行的角度来描述elf文件,sections是从链接的角度来描述elf文件,也就是说,在链接阶段,我们可以忽略program header table来处理此文件,在运行阶段可以忽略section header table来处理此程序。
- - Section Header Table: 包含了文件各个section的属性信息,比如起始偏移位置,大小等。
ELF文件格式可通过 readelf ,objdump,gdb等工具查看具体内容,该文件各部分详细说明参考滕启明写的《ELF文件格式分析》和《程序员的自我修养》。
参考: linux,windows 可执行文件(ELF、PE)
ELF格式文件详细分析
三、符号解析和重定位
对多个可重定位目标文件和其引用的共享库文件进行链接时,首先会逐一查找校验可重定位文件使用的所有变量或者函数,包括本模块内定义的和引入自其他模块的,是否存在合法的唯一的定义,如果查找校验失败就会报错符号未找到(undefined reference)。所谓的符号就是源代码中使用的函数名或者变量名,符号是为了提高代码的可读性,方便编程使用,编译时需要将所有的符号替换成内存中的相对地址或者绝对地址,因为底层的机器指令只认识内存地址。上述查找校验符号并将其替换成内存地址的过程就称为符号解析。
查找校验完符号后就会将多个可重定位文件按照输入的文件顺序以section为维度进行合并,一个一个的拼接,因为单个可重定位目标文件中使用的相对地址的起始地址都是0,所以合并时需要将原来的相对于0的地址都加上一个偏移地址,并改写对应section,最后更新对应的section Table。计算偏移地址的时候除了考虑文件拼接因素外,还需要考虑section对应segment在虚拟地址空间中的分布,考虑内存页的大小,即内存布局优化,这个过程就称为地址和空间分配,地址和空间指的是虚拟地址和空间。
单个源代码文件在编译时并不知道其引用的其他模块中的全局变量和函数的具体内存地址,因此编译后的汇编代码(.text section)中此类未知符号都有对应的特定内存地址表示,并在可重定位表(.text.rel section)中记录了这类未知符号。链接时会查找这类未知符号的真实地址,并改写汇编代码中使用的特定地址,这个过程就是重定位,即将代码指令中使用的假地址替换成真实内存地址的操作,重定位是符号解析的核心。在程序静态编译环节发生的重定位叫静态重定位,在程序加载完成,动态链接过程产生的重定位称为动态重定位。
参考: 程序的链接和装入及Linux下动态链接的实现
ELF学习--重定位文件
ELF学习--可执行文件
四、静态链接和动态链接
在静态编译环节将多个存在依赖关系的文件(模块或者库)做合理拼接就称为静态链接。如果多个进程即对应的多个可执行文件都依赖了同一个模块,在静态链接下,该模块的代码和数据则会在硬盘,内存中都各保存一份,实际上代码是可以多个进程共享的,这样就导致了内存硬盘存储空间的浪费。如果该模块代码更新,就必须对可执行文件进行二次编译才能使用更新后的模块代码。
解决上述问题的方法就是动态链接,即将符合解析中核心操作重定位推迟到程序运行时进行,具体而言就是在代码指令运行过程中只有用到了某个来自其他模块的全局变量或者函数才会触发对应的重定位,该重定位由动态链接重定位表,符号表和动态链接器完成,符号表和重定位表记录需要动态链接的符号及其所属的模块ID,函数名等,动态连接器根据重定位表的信息找到符号对应的真实地址。动态链接下,彼此相互依赖的多个模块可以独立开发,独立编译,模块间通过定义全局变量和函数的头文件调用,因为同一个头文件可以有不同的实现,所以可以极大提高程序的可扩展性和兼容性;编译时不需要将依赖的其他模块文件合并进来,所以生成的最终可执行文件体积更小,当其他模块出现更新时不需要对本模块二次编译。动态链接的问题是依赖的模块更新后可能跟原来的接口不兼容且有一定的性能损耗(与静态链接比,在5%以下)。
某个库文件通过静态链接还是动态链接的方式编译由库文件本身决定,编译形成共享库文件时,可以通过参数指定形成静态链接库文件和动态链接库文件,前者.a结尾,后者.so结尾,默认是动态链接库文件,在链接时链接器判断符号所属的库文件是动态链接库就会做特殊处理,将这类符号放在单独的动态链接符号表和可重定位表中。静态链接库文件中每个函数对应一个目标文件,如printf函数对应printf.o文件,这样拆分是为了避免引入其他不需要的函数而导致最终的可执行文件体积过大。动态链接库文件是在程序被装载的时候由动态链接器加载到对应进程的虚拟地址空间内(即完成库文件的内存映射),在完成动态链接后才将控制权交给可执行文件的入口地址,由动态连接器保证内存中的库文件只有一份,但数据是每个进程独立的。动态链接器的库文件路径在可执行文件的.interp section内,Linux下通常是/lib/ld-linux.so.2。
参考: 《程序员的自我修养》
c语言程序编译运行过程;静态链接,动态链接
ELF--动态链接