人脸识别算法FaceNet论文解读
版权声明:本文为CSDN博主「张雨石」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/stdcoutzyx/article/details/46687471
参考文章:https://www.cnblogs.com/lijie-blog/p/10168073.html
参考文章:https://blog.csdn.net/Fire_Light_/article/details/79592804
论文名称:FaceNet: A Unified Embedding for Face Recognition and Clustering
论文地址:https://arxiv.org/pdf/1503.03832.pdf
1、FaceNet
与其他的深度学习方法在人脸上的应用不同,FaceNet并没有用传统的softmax的方式去进行分类学习,然后抽取其中某一层作为特征,而是直接进行端对端学习一个从图像到欧式空间的编码方法,然后基于这个编码再做人脸识别、人脸验证和人脸聚类等。去掉了最后的softmax,而是用元组计算距离的方式来进行模型的训练。元组的选择非常重要,选的好可以很快的收敛。
2、网络结构
这篇文章中,最大的创新点应该是提出不同的损失函数triplet,直接是优化特征本身,用特征空间上的点的距离来表示两张图像是否是同一类。网络结构如下:
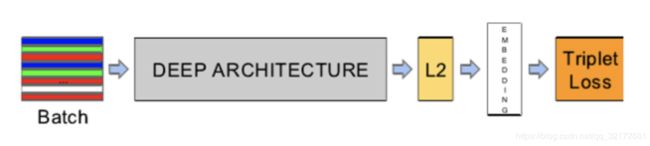
上图是文章中所采用的网络结构,上图步骤可以描述为:
1.前面部分采用一个CNN结构提取特征,
2.CNN之后接一个特征归一化(使其特征的||f(x)||2=1,这样子,所有图像的特征都会被映射到一个超球面上),
3.再接入一个embedding层(嵌入函数),嵌入过程可以表达为一个函数,即把图像x通过函数f映射到d维欧式空间。
4.此外,作者对嵌入函数f(x)的值,即值阈,做了限制。使得x的映射f(x)在一个超球面上。
5.接着,再去优化这些特征,而文章这里提出了一个新的损失函数,triplet损失函数(优化函数),而这也是文章最大的特点所在。
3、目标函数
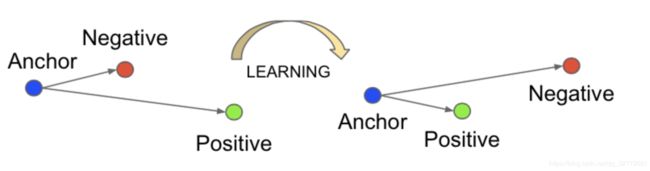
所谓的三元组就是三个样例,如(anchor, pos, neg),其中,x和p是同一类,x和n是不同类。那么学习的过程就是学到一种表示,对于尽可能多的三元组,使得anchor和pos的距离,小于anchor和neg的距离。即:
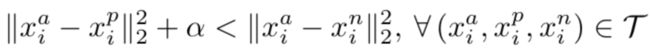
所以,变换一下,得到目标函数:
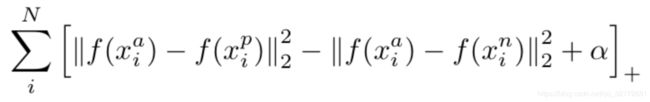
目标函数的含义就是对于不满足条件的三元组,进行优化;对于满足条件的三元组,就pass先不管。
4、三元组的选择
很少的数据就可以产生很多的三元组,如果三元组选的不得法,那么模型要很久很久才能收敛。因而,三元组的选择特别重要。
因此需要采取两种显而易见的方法避免这个问题:
(1)离线更新三元组(每隔n步)。采用最近的网络模型的检测点并计算数据集的子集的argmin和argmax(局部最优)。
(2)在线更新三元组。在mini-batch上选择不好的正(类内)/负(类间)训练模型。(一个mini-batch可以训练出一个子模型)
本文中采用上述第二种方法。本文中,采用以下方法:
(1)使用大量 mini-batch,从而得到几千个不好的训练模型。
(2)计算mini-batch上的argmin和argmax。
总结:以上所有过程博主概括为:为了快速收敛模型-->需要找到训练的不好的mini-batch上的差模型(负样本)-->从而找到不满足约束条件/使损失增大的三元组。
在本文中,训练集的每个mini-batch包含:
1. 每个身份的40个人脸
2. 随机放一些负样本人脸
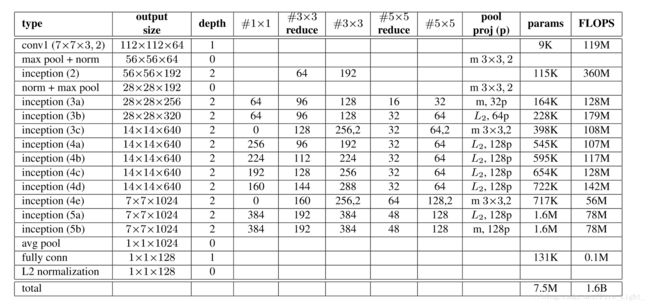
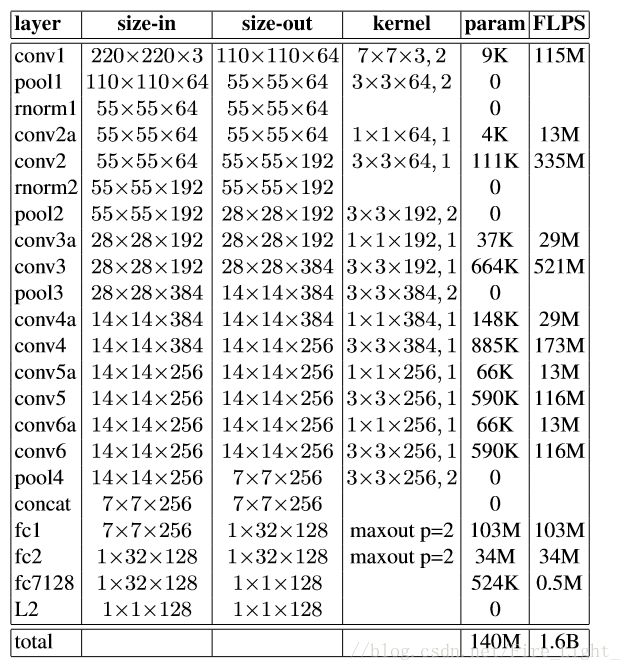
5、网络模型
文中尝试了两个CNN结构,其参数如下:
网络1:Zeiler&Fergus architecture
网络2: GoogLeNet