GAN Guides
Coding Skill目录下的所有Tutorials、Notes、Guides博客都会不定期迭代更新
文章目录
- What's GAN
- Traditional Function
- 变分自动编码器(VAE)
- Auto-Encoder
- Fancy Application
- GAN的其他变体
- 评价指标
- 書籍推薦
- 论文推荐
What’s GAN
GAN全称是Generator adversarial networks,中文是生成对抗网络,是一种生成式模型,无监督模型。
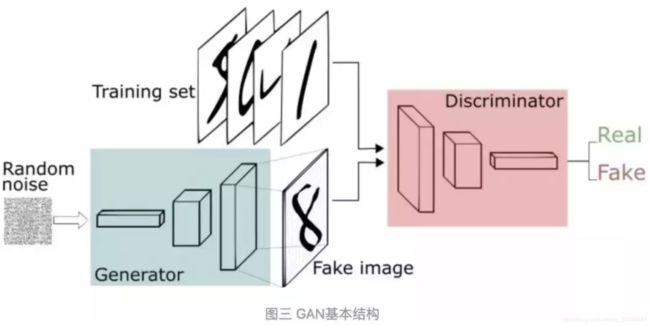
GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。
-
Generator
定义一个模型(可以是任意可以输出图片的模型,比如最简单的全连接神经网络,又或者是反卷积网络等。)来作为生成器,输入需要一个n维度向量(使用随机生成的向量来作为输入即可,随机输入最好是满足常见的比如均值分布,高斯分布等。),输出为图片像素大小的图片。 -
Discrimnator
往往是常见的判别器,输入为图片,输出为图片的真伪便签。可以是任意的判别器模型,比如全连接,或者是包含卷积的神经网络。
生成式对抗网络模型综述
DCGAN介绍及原理
- How to training
基本流程如下:- 初始化判别器D和生成器G的参数
- 固定生成器G,训练判别器D
How to Train a GAN? Tips and tricks to make GANs work
Tip:之所以要训练k次判别器,再训练生成器,是因为要先拥有一个好的判别器,使得能够教好地区分出真实样本和生成样本之后,才好更为准确地对生成器进行更新。
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。
可以看到在(a)状态处于最初始的状态的时候,生成器分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。
通过多次训练判别器来达到(b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。
训练生成器之后达到(c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。
经过多次反复训练迭代之后,最终希望能够达到(d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。也就是说我们这个时候就可以生成出非常真实的样本啦,目的达到。
- Summary
GAN一开始提出来的时候,实际上针对于不同的情况也有存在着一些不足,后面也陆续提出了不同的GAN的变体来完善GAN。
通过一个判别器而不是直接使用损失函数来进行逼近,更能够自顶向下地把握全局的信息。比如在图片中,虽然都是相差几像素点,但是这个像素点的位置如果在不同地方,那么他们之间的差别可能就非常之大。
比如上图10中的两组生成样本,对应的目标为字体2,但是图中上面的两个样本虽然只相差一个像素点,但是这个像素点对于全局的影响是比较大的,但是单纯地去使用使用损失函数来判断都是相差一个像素点,而下面的两个虽然相差了六个像素点的差距(粉色部分的像素点为误差),但是实际上对于整体的判断来说,是没有太大影响的。
但是使用损失函数的话,却会得到6个像素点的差距,比上面的两幅图差别更大。而如果使用判别器,则可以更好地判别出这种情况(不会拘束于具体像素的差距)。
Traditional Function
变分自动编码器(VAE)
Auto-Encoder
Fancy Application
GAN Zoo
AdversarialNetsPapers
GAN Application
十款神奇的GAN,总有一个适合你!
-
图像生成
GAN的生成器G输入是一个随机向量,输出的是图像
比如可以用来制作海报,自己用来生成一个高清美女图像作为海报主角,省了一大批广告费。 -
图像转换
图像转换或者说是图像翻译,是将图像转换为另一种形式的图像,与风格迁移稍有不同(区别是???),这方面典型的工作是pixel-2-pixel。
一般的GAN的生成器G输入是一个随机向量,输出的是图像,这里的生成器的输入是图像,输出的是转换后的图像。
cgan:
https://blog.csdn.net/jiongnima/article/details/80209239
https://blog.csdn.net/wspba/article/details/54666907
pix2pix-TF
Example:
- Cycle-GAN,可以实现风景画和油画互变,马和斑马互相转换等domain transfer等任务。cycleGAN的主要贡献是提供了一种unpaired的图像翻译方法,这是pix2pix所做不到的。
- DiscoGAN,DiscoGAN在不需要label标记和图像pairing的情况下学习交叉domain之间的联系,比如它可以将包包的图像风格迁移到鞋子的图像上
- cycleGAN给冷酷大哥加上笑容,将人脸图像转换为卡通图像,类似之前很火的脸萌APP,这个工作见DTN
(https://arxiv.org/pdf/1611.02200.pdf)。
-
图像合成
图像合成这个任务是通过__某种形式的图像描述__创建新图像的过程。pix2pix和cycleGAN 都属于图像合成领域的一部分。-
场景合成
给定部分显示场景的信息还原出真实的场景信息,比如根据分割图像还原出原始场景信息,刚好是图像分割的逆过程,据说英伟达在不断的开拓这个方向,试想一下,只要GAN还原的场景足够真实,完全可以模拟无人驾驶的路况场景,从而在实验室阶段就可以完成无人驾驶汽车的上路测试工作 -
人脸合成
人脸合成主要是根据一张人脸的图像,合成出不同角度的人脸图像,可以用做人脸对齐,姿态转换等辅助手段提高人脸识别的精度,典型的工作是中科院的TP-GAN,可以根据半边人脸生成整张人脸的前向图,对人脸识别任务有很大的辅助效果。 -
文本到图像的合成
从给定的一段文字描述,生成一张和图像文字匹配的图像。比如:根据文字:一只黑色冠冕和黄色喙的白色的鸟,生成下面的这张图像。
类似的工作还有 stack GAN 和 attn GAN:https://arxiv.org/abs/1711.10485,后者更是在细粒度的text-to-image上做了一番功夫。 -
风格迁移
Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks,作者发明了一种马尔可夫GAN迁移图像的风格,算是不错的贡献了。 -
年龄变化
Age-cGAN只要有一张年轻时候的照片,就可以提前知道自己几十年之后的样子。
-
-
图像超分辨率
图像超分辨率一直是一个很重要的研究课题,比较重要的是对天文图像和卫星图像做超分辨率,不管是在天文,军事还是其他方面,都有很重要的应用。在生活中,如果有标清的视频可以变为高清的视频。
上述过程都是可逆的,既然可以增加图像的分辨率,那么同样可以减小图像的分辨率。既然都说到了图像超分辨率,那么就谈谈图像去马赛克的一些操作,知乎一位大佬集图像转化和超分辨率之大成,完成了对爱情动作片的添加和去除马赛克操作,详情请移步知乎,36k的高赞文章。- 单帧图像超分辨率:去马赛克其实是个图像超分辨率问题,也就是如何在低分辨率图像基础上得到更高分辨率的图像:
- video多帧影像超分辨率:通过不同帧的低分辨率画面猜测超分辨率的画面
-
图像域的转换
GAN很适合学习数据的分布(只要是数据是连续的,对于离散的文本数据效果不是很好),同时也能完成domain转换的任务,比如使用GAN完成domain的迁移,此部分有比较典型的工作,CVPR的oral论文StarGAN是其中一个。Pix2Pix模型解决了有Pair对数据的图像翻译问题;CycleGAN解决了Unpaired数据下的图像翻译问题。但无论是Pix2Pix还是CycleGAN,都是解决了一对一的问题,即一个domain到另一个domain的转换。StarGAN就是在多个domain之间进行转换的方法。可以做多个图像翻译任务,比如更换头发颜色,表情变化,年龄变换等等.
穿衣搭配问题,详细工作可见PixelDTGAN: https://github.com/fxia22/PixelDTGAN PixelDTGAN是指像素级的domain 转换,输入的是一张复杂的图片,输出的是不包含背景的单纯的服饰的图像 -
图像修复
给定一张缺失的图像,修复出完整的图像
也可以用pix2pix来解决方案
-
文本填空
None -
其他
None
Reference
GAN的其他变体
[你的侧脸泄露了太多信息,中科院TP-GAN图像生成太逆天了]
(https://www.eefocus.com/sensor/381380/r0)
最新的paper里面会有一部分来描述gan的相关研究和历史研究,那是人家总结过的,看看那个应该不会错,比自己搜索要高效。
GAN -> DCGAN -> CGAN -> Pix2Pix -> WGAN -> InfoGAN
https://github.com/YadiraF/GAN
Github Collection of generative models in Tensorflow
Github – 不同GAN效果对比
或许应该像 《21个项目玩转深度学习》 该书中设计纲领的思路来学习,即根据应用场景来学习技术,因为现实中的项目都有对应的业务场景,技术本没用,能解决实际问题才是价值体现。
GAN 生成对抗网络论文阅读路线图
历史最全GAN网络及其各种变体整理(附论文及代码实现)
Mofan GAN
独家 | GAN大盘点,聊聊这些年的生成对抗网络 : LSGAN, WGAN, CGAN, infoGAN, EBGAN, BEGAN, VAE
训练”稳定”,样本的”多样性”和”清晰度” 似乎是GAN的 3大指标
- GAN
- CGAN:cGAN 可以根据指定标签生成样本,pix2pix 模型,可以看作是 cGAN 的一种特殊形式。
Blog
Blog
详解GAN代码之搭建并详解CGAN代码
Conditional Generative Adversarial Nets论文笔记
深度有趣 | 17 CGAN和ACGAN - DCGAN:很难训练
- 改进的 DCGAN:GAN 有关的主要问题之一是它们的收敛性。它是不能保证的,而且即使优化了 DCGAN 架构,训练仍然相当不稳定。
各种出色的GAN变体 - WGAN:GAN的改进版本,Loss改为Wasserstein Loss,更加方便Training好Model。DCGAN用经验告诉我们什么是比较稳定的GAN网络结构, 而WGAN告诉我们: 不用精巧的网络设计和训练过程, 也能训练一个稳定的GAN.
Blog - WGAN-GP
Blog
Blog
Blog
Blog
- SGAN(Stacked GAN):SGAN是一种结构创新的GAN,通过堆叠多个GAN网络,实现生成模型的信息“分层化”。
- InfoGAN:信息理论(Information-theoretic)与GAN相结合提出InfoGAN,采用无监督的方式学习到输入样本X的可解释且有意义的表示(representation)。
InfoGAN解读 - LS GAN
- DRAGAN
- LAPGAN:在 Progressive GAN 出来以前,训练高分辨率图像生成的 GAN 方法主要就是 LAPGAN[2] 和 BEGAN[6]。LAPGAN是建立在GAN和CGAN基础上的成功尝试。LAPGAN 借助 CGAN,高分辨率图像的生成是以低分辨率图像作为条件去生成残差,然后低分辨率图上采样跟残差求和得到高分辨率图,通过不断堆叠 CGAN 得到我们想要的分辨率。
Blog - EBGAN(Energy-based GAN):实验证明EBGAN可以生成高分辨率的图片(256×256)
Blog
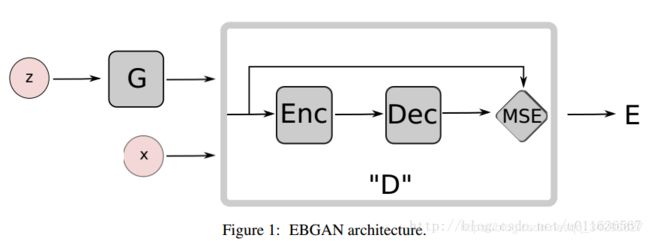
- BEGAN:弥补了DCGAN和improveGAN很难训练的问题。BEGAN使训练过程快又稳定,解决了D网络和G网络能力平衡问题;有能力控制生成图片的多样性和质量平衡问题以及衡量收敛性的近似方法。在128x128上人脸的生成效果还不错。
Code
Blog
Blog
============================= 风格线 ==============================
======================== 高分辨率GAN的诞生 ========================= - Progressive GAN:第一个生成的高分辨率图片(1024*1024)的Model,采用 progressive growing 的训练方式,先训一个小分辨率的图像生成,训好了之后再逐步过渡到更高分辨率的图像。然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率。训练 GAN 生成高分辨率图像,还有一种方法,叫 LAPGAN[2]。LAPGAN 借助 CGAN,高分辨率图像的生成是以低分辨率图像作为条件去生成残差,然后低分辨率图上采样跟残差求和得到高分辨率图,通过不断堆叠 CGAN 得到我们想要的分辨率。
Blog-强烈推荐
TVGAN 的训练,BigGAN,与 InfoGAN 的最新进展,GAN 是否已接近最终形式?
Blog
Blog
给动漫人物轻松换装、编舞
Code:附带CelebAHQ的制作方法
Code第一个使用版本
Official Code
code progressive_infogan - SAGAN:自我注意力生成对抗网络,它在ImageNet数据集上把Inception Score初始分数从原记录的36.8提高到了52.52,并把FID(Fréchet Inception Distance)从27.62降到了18.65。GAN之父Ian Goodfellow大作。解决了:在包含多类图像的大型数据集上训练后,它们无法明确区分图像类别,难以捕捉到这些图像的结构、质地、细节等,因此我们不能用一个GAN生成大量类别不一的高质量图像。
Blog
Blog
Blog
Blog
Blog
Blog
Code
Code - SNGAN - RSGAN:
Blog - BigGAN: SAGAN 在 ImageNet 的128x128 图像生成上的 Inception Score (IS) [3] 达到了 52 分。BigGAN 在 SAGAN 的基础上一举将 IS 提高了 100 分,达到了 166 分(真实图片也才 233 分)。不过BigGAN什么都用的大,是Nvidia的实习生搞出来的,GPU用了很多。
BigGAN Blog
Blog
BigGAN-pytorch
BigGAN-Tensorflow - StyleGAN:顾名思义,GAN的生成器,是借用风格迁移的思路重新发明的。
百度 StyleGAN 解讀
Blog-强烈推荐
2018最佳GAN论文回顾(上)
Blog
Blog
Blog 推荐
Fanny Application
Fanny Application
Code - Pytorch
News
我们的数据集带有一种style的特性
每一个网络结构在某一特定的历史时期都具有突破性的价值,即使它在历史的长河中只是一个过渡,源源不断的新突破会接踵而至。
mode collapse:
Google 还明确地说,可能是 BigGAN 太大了,到后面都会塌掉,他们也没搞清楚深层的原因。所以现在 report 的是塌掉之前的结果。难道真的是效果好大于一切吗?甚至有的时候可以并不清楚为啥效果会这样,或者为啥会效果不好
- StackGAN:Text to Photo-realistic Image Synthesis,分辨率从64x64上升到256x256。
- AttnGAN:这篇文章的主要思想是将生成256x256图像的文图转换成先生成64x64,然后再生成128x128,最后再生成256x256的问题(与stackGAN类似,分多步),从低分辨率的图像生成高分别率图像的过程中,分别利用低分辨率的图片信息和word-context产生下一状态的图片,为了在让最后生成的256x256大小的图像与文本的语义一致,作者应用了文本图像检索的方法将生成的图像与原始的文本之间度量他们的相似性(分别从word层面和sentence层面)。
Blog
High-Resolution Deep Convolutional Generative Adversarial Networks
Energy-relaxed Wassertein GANs (EnergyWGAN): Towards More Stable and High Resolution Image Generation
A Fully Progressive Approach to Single-Image Super-Resolution
Multi-Content GAN for Few-Shot Font Style Transfer
CAN: Creative Adversarial Networks, Generating Art by Learning About Styles and Deviating from Style Norms
Style Transfer Generative Adversarial Networks: Learning to Play Chess Differently
Generative Image Modeling using Style and Structure Adversarial Networks
GP-GAN: Towards Realistic High-Resolution Image Blending
- CGAN -> Pix2Pix -> CycleGAN:图像翻译
CycleGAN-Zhihu
CycleGAN-Pytorch
DiscoGAN和DualGAN
CycleGAN, DiscoGAN, DualGAN
SRResNet - SRGAN(与WGAN、CGAN、PixPix的关系)- ESRGAN - NAS(xiaomi):超分辨率,图像重建
pytorch-SRResNet
tensorlayer-SRHAN
SRGAN_Wasserstein
小米9拍照黑科技:基于NAS的图像超分辨率算法
关于GAN的灵魂七问
SC-FEGAN
不懂Photoshop如何P图?交给SC-FEGAN吧
SketchRNN
素描画
CartoonGAN
pytorch-CartoonGAN
CartoonGAN-Tensorflow
人工智能遇上二次元:用AI生成高分辨率全身动漫人物
AI插画师:如何用基于PyTorch的生成对抗网络生成动漫头像?
AI可能真的要代替插画师了……
你的老婆你做主:画风自定义,内容自定义,南加大AI助你走上人生巅峰
GAN:艺术家眼里生成作品的创作利器
一位艺术家眼中的GAN:它给予我更多灵感
通过文字描述来生成二次元妹子!聊聊conditional GAN与txt2img模型
“抠图”这手艺要过气了:用深度学习自动去除照片背景
TVGAN:一种简单且有效的新GAN (以及WGAN论文的问题) 思考DL的理论细节 (2)
DGN:生成模型,可以有多简单?思考DL的理论细节 (3)
基于深度学习的图像着色算法研究与实现
评价指标
Inception Score
全面解析Inception Score原理及其局限性
FID
Flop指标
六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
如何评价GAN网络的好坏?IS(inception score)和FID(Fréchet Inception Distance
Code Inception-Score
Code
Code
書籍推薦
GAN:实战生成对抗网络:尚未找到電子版资源
https://download.csdn.net/download/livepoolgerres/10905092
论文推荐
想要使用GAN完成期望的学习任务,精致的网络设计和合适的目标函数必不可少,二者是实现较高performance的关键因素。
conditionalGAN:Image-to-Image Translation with Conditional Adversarial Networks
BEGAN:BEGAN: Boundary Equilibrium Generative Adversarial Networks
EBGAN:ENERGY-BASED GENERATIVE ADVERSARIAL NETWORKS
tripleGAN:分析了当前gan存在的问题,不过是两个参与者不能很好的共同收敛。于是提出加入一个第三者
Triple Generative Adversarial Nets
bayesianGAN:Bayesian GAN
stackGAN:为了提高分辨率,可以分两次生成,char-cnn-rnn,text to image GAN
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
cycle GAN:只需不配对数据即可,实现image to image 的转换
CycleGAN-TensorFlow
Tensorflow implementation of CycleGANs
CycleGAN-Torch
CycleGAN-Tensorflow-2
AttGAN-Tensorflow: AttGAN: Facial Attribute Editing by Only Changing What You Want
比CycleGAN更强的非监督GAN----DistanceGAN
Contrast GAN— 实现CycleGAN无法实现的“眼一瞎, 猫变狗”,“手一抖,单车变摩托”
CycleGAN-Zhihu
异父异母的三胞胎:CycleGAN, DiscoGAN, DualGAN
CycleGAN_Tensorlayer
CycleGAN原理及实验(TensorFlow)
生成对抗网络系列(x)——CVPR2018中的图像转化GAN
对偶学习的生成对抗网络 (DualGAN)
人工智能CycleGAN加注意力机制图像转换实现最先进图像到图像转换
cyclegan-qp
带你理解CycleGAN,并用TensorFlow轻松实现
用机器学习生成图片(下)CycleGAN和pix2pixHD
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
infoGAN:信息加入,比conditionalGAN厉害
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
WGAN:接触GAN的都听说过~
Wasserstein Generative Adversarial Networks
f-GAN: f-GAN: 都是可以被规整到他的范式里面,厉害的吧
Training Generative Neural Samplers using Variational Divergence Minimization wgan
SeqGAN: 可以生成序列的GAN
Sequence Generative Adversarial Nets with Policy Gradient
LSGAN:Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities