在Hadoop分布式环境下运行WordCount实例
前提
必须已经配置好了Hadoop真分布环境,如果还没配置好的,可以参看这篇文章:在本机的虚拟机上配置Hadoop真分布集群详细教程
WordCount实例
一、启动HDFS进程服务
命令:start-all.sh
jps
通过jps查看HDFS是否成功启动(jps是一个java程序,它的作用是查看当前Java虚拟机运行着哪些程序)
DataNode、NameNode和SecondaryNameNode这三个组成HDFS系统的进程,说明HDFS系统已经成功启动。
二、使用HDFS服务运行WordCount程序
1.在HDFS创建一个/input的文件夹结构
命令:hdfs dfs -mkdir /input
2.在master节点的/usr/local/hadoop-3.1.0/data/目录下创建一个note.txt
命令:touch -a note.txt
3.编辑note.txt文件,输入一些字符
vi note.txt
添加内容:
Hello Everybody !
my name is TG , This is my centOS .
4.把note.txt文件上传到HDFS,进行文件的分布式存储。
命令:hdfs dfs -put note.txt /input
5.查看HDFS的/input文件夹下面有哪些文件
命令:hdfs dfs -ls /input
我们会看到其中有个note.txt文件,说明我们成功把note.txt文件传输到HDFS了。
6.当前在hadoop-3.1.0根目录下,运行share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar这个java程序,调用wordcount方法。
/input/note.txt是输入参数,待处理的文件
/output/note是输出参数,保存处理后的数据的文件夹名字
命令:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar wordcount /input/note.txt /output/note
7.查看HDFS的/output/note/part-r-00000文件。
命令:hdfs dfs -cat /output/note/part-r-00000
⑥进入到/usr/local/hadoop-3.1.0/data目录下,运行WordCount.jar包,执行词频统计程序
命令:hadoop jar wordCount.jar WordCount/WordCountDriver /input/note.txt /output/note
[注]
wordCount.jar:jar包所在目录
WordCount/WordCountDriver:WordCount包下的main程序所在java文件名
/input/note.txt:即将进行词频统计的文件
/output/note:执行词频统计后的输出文件,注意不要新建此文件夹,确保是在执行程序时系统自动新建。
⑦执行命令后,在HDFS系统的/output/note/下出现一个part-r-00000文件,执行此文件查看词频统计情况
命令:hdfs dfs -cat /data/out/note/part-r-00000
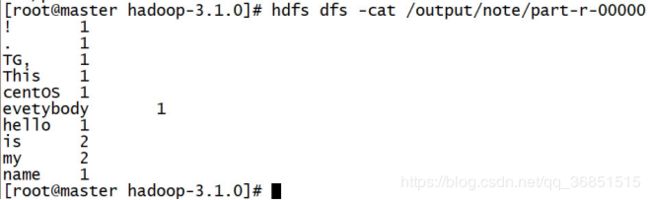
到此,mapreduce的wordcount实例运行成功。
额外命令
hadoop fs -ls /local //这条命令作用是查看/local文件夹下的所有文件
hadoop fs -cat /local/sample.txt //这条命令作用是查看/local文件夹下sample.txt文件的内容
hadoop fs -get /output/sampleout/part-r-00000 //作用:将HDFS文件系统/output/sampleout文件夹下的part-r-00000文件下载至根目录下
hadoop fs -get /output/sampleout/part-r-00000 /home/lina/temp/ //作用:将HDFS文件系统/output/sampleout文件夹下的part-r-00000文件下载至/home/lina/temp目录下
hadoop fs -rm /local/sample.txt //作用:将/local文件目录下的sample.txt文件删除
hadoop fs -rm -r /local //将local文件夹及其内部的文件删除
参考资料
使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)