Hadoop基本配置及在本地模式下运行MapReduce案例
一、认识Hadoop
什么是Hadoop,这里来看看官网的说法,Scalable distribute computing,即可扩展分布式计算框架。具体看下面:
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.Apache Hadoop软件库是一个框架,它允许使用简单的编程模型在计算机集群中对大型数据集进行分布式处理。它被设计成从单个服务器扩展到数千台机器,每个都提供本地的计算和存储。与依赖硬件交付高可用性不同,该库本身的设计目的是检测和处理应用程序层的故障,因此在集群的顶部提供高可用性服务…
上面是来自官网的说法,更简单具体就是,(Scalable distribute computing)可扩展分布式计算框架。
在这里基于本篇文章的内容介绍下MapReduce,关于Hadoop生态系统更具体的内容可参考官网的介绍,在以后的文章中也会有更具体的介绍。
MapReduce是一个离线计算的框架,对海量数据进行处理,采用分而治之的思想,大数据集分为小的数据集,每个数据集,进行逻辑业务的处理(map),合并统计业务结果(reduce)。
1.MapReduce将计算结果分为两个阶段,Map和Reduce.
- map阶段并行处理输入的数据。
- reduce阶段对map结果进行汇总。
2.shuffle连接map和reduce这两个阶段
- map task将数据写入磁盘。
- reduce task从每一个map task上读取一份数据。
3.仅适合离线批处理。
- 具有良好的容错性和扩展性。
- 适合简单的批处理任务。
4.缺点明显:
- 启动开销大,过多使用磁盘导致效率低下等。
对于Hadoop及MapReduce的介绍我们就简单介绍到这里,详情参照官网:
http://hadoop.apache.org
二、搭建Hadoop基本环境
首先你要有安装一台Linux虚拟机,然后安装jdk环境,具体怎么安装jdk读者可查看相关资料,很简单,这里不做说明,在安装好jdk后。在官网下载Hadoop压缩包,这里我们下载的是Hadoop2.5,当然你也可以按照自己的需求去下载相应的版本。
如果在官网找不到以前的版本,因为有的新版本的Hadoop不太稳定。因此我们可以去Apache的官网去找(http://archive.apache.org/dist/)。当我们下载好了之后将其解压。
tar -zxf hadoop-2.5.0.tar.gz -C /opt/modules这里将Hadoop解压在opt/modules目录下,编辑文件/etc/hadoop/hadoop-env.sh配置java环境:
export JAVA_HOME=/home/java/jdk1.8.0_151上面配置的时候只需将JAVA_HOME改为自己jdk安装目录即可。
这时,我们就配置好了最基本的Hadoop环境,按照官网的介绍,我们可以启动测试一下我们的MapReduce程序。进入hadoop的解压目录。
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar grep input output 'dfs[a-z.]+'运行上面的代码,我们会在Hadoop解压目录下得到一个output目录,这个目录下就是我们程序的运行结果。如下图:
![]()
三、MapReduce案例
接下来,我们来做一个很经典的大数据案例,即wordcount程序,统计一篇文本中的单词数。这里在Hadoop解压目录下建立wcinput目录。
mkdir wcinput
cd wcinput
touch wc.input
vim wc.input
hadoop linux mapreduce
linux hadoop yarn hdfs
hdfs hadoop linux yarn上面,我们建立了一个wcinput目录,然后在这个目录下创建了一个wc.input文件,在这个文件中添加了几行简单的文字来统计一下这里的不同的单词出现的单词数。
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount wcinput wcoutput
$ cat wcoutput/part-r-00000运行上面命令即可统计文本中的单词数,下面我们来看看运行结果:
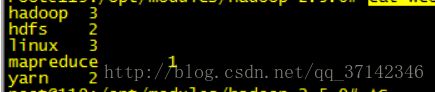
至此,我们就在本地模式下运行了一个简单的MapReduce案例,Hadoop的搭建方式有三种,本地模式,伪分布模式和完全分布式模式,这篇文章我们简单介绍了一下本地模式下怎样搭建Hadoop环境以及运行简单的案例,在后面会陆续介绍伪分布模式下和完全分布式模式下Hadoop的搭建,有什么不足之处望批评指出。
四、注意
大多人在搭建Hadoop环境的时候会遇到很多问题,这里向大家介绍一下我遇到的问题以及解决方案:
Java HotSpot(TM) Client VM warning: You have loaded library /opt/modules/hadoop-2.5.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ', or link it with '-z noexecstack'.
17/12/28 21:45:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/28 21:45:18 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
17/12/28 21:45:18 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
17/12/28 21:45:18 INFO metrics.MetricsUtil: Unable to obtain hostName
java.net.UnknownHostException: myhadoop: myhadoop: Name or service not known
at java.net.InetAddress.getLocalHost(InetAddress.java:1505)
at org.apache.hadoop.metrics.MetricsUtil.getHostName(MetricsUtil.java:95)
at org.apache.hadoop.metrics.MetricsUtil.createRecord(MetricsUtil.java:84)
at org.apache.hadoop.metrics.jvm.JvmMetrics.(JvmMetrics.java:87)
at org.apache.hadoop.metrics.jvm.JvmMetrics.init(JvmMetrics.java:78)
at org.apache.hadoop.metrics.jvm.JvmMetrics.init(JvmMetrics.java:65)
at org.apache.hadoop.mapred.LocalJobRunnerMetrics.(LocalJobRunnerMetrics.java:40)
at org.apache.hadoop.mapred.LocalJobRunner.(LocalJobRunner.java:714)
at org.apache.hadoop.mapred.LocalJobRunner.(LocalJobRunner.java:707)
at org.apache.hadoop.mapred.LocalClientProtocolProvider.create(LocalClientProtocolProvider.java:42)
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:95)
at org.apache.hadoop.mapreduce.Cluster.(Cluster.java:82)
at org.apache.hadoop.mapreduce.Cluster.(Cluster.java:75)
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1255)
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1251)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.mapreduce.Job.connect(Job.java:1250)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1279)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303)
at org.apache.hadoop.examples.Grep.run(Grep.java:77)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.examples.Grep.main(Grep.java:101)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:72)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:145)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
Caused by: java.net.UnknownHostException: myhadoop: Name or service not known
at java.net.Inet4AddressImpl.lookupAllHostAddr(Native Method)
at java.net.InetAddress$2.lookupAllHostAddr(InetAddress.java:928)
at java.net.InetAddress.getAddressesFromNameService(InetAddress.java:1323)
at java.net.InetAddress.getLocalHost(InetAddress.java:1500)
... 35 more
17/12/28 21:45:18 INFO metrics.MetricsUtil: Unable to obtain hostName
java.net.UnknownHostException: myhadoop: myhadoop: Name or service not known 上面启动报错,这个错误很简单,不能识别主机,看似很简单的问题,该怎么解决呢?这里Hadoop不能识别myhadoop这个主机,这是我们可以设置主机名为外网的ip地址即可解决。希望可以帮到初学者。