03-0003 Python遗传算法解决旅行商问题
Python遗传算法解决旅行商问题
- 0.前言
- 1.介绍
- 1.1算法介绍
- 1.2问题介绍
- 2.流程
- 2.1流程图
- 2.2选择过程
- 2.2.1轮盘赌选择法
- 2.2.2比例选择法
- 2.2.3精英保留策略
- 2.3交叉过程
- 2.3变异
- 3.源码
- 4.结果
- 5.总结
0.前言
物竞天择,适者生存
遗传算法模拟生物进化的历程,好的个体拥有好的基因,好的基因能够在物竞天择的环境中被保留,环境一致的情况下,这些个体会越来越多。
1.介绍
1.1算法介绍
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。
每个个体实际上是染色体(chromosome)带有特征的实体。染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。
因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。
这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。
以上描述来自于百度,属于官方描述,其中起床算法是搜索最优解,而不是直接计算得到最优解。
1.2问题介绍
旅行商问题描述:给定一系列城市和每对城市之间的距离,求解访问每一座城市一次并回到起始城市的最短回路。
它是组合优化中的一个NP困难问题,在运筹学和理论计算机科学中非常重要。
本次实验选择的是国内的有限个城市,如下图:

2.流程
如同基因遗传一般,遗传算法的过程包括:选择,交叉,变异三个过程,通过多次迭代,可以逐渐收敛于最优解,
但是并不能保证最后一定会得到最优解。
理解遗传算法并不难,困难在代码的实现。
2.1流程图

流程图是根据代码绘制的,其实可以更简单一些,该算法无非就是选择交叉变异,然后多次迭代,在自己期望的最后一次迭代末尾,输入最优的一个解。
2.2选择过程
选择过程有不同的选择策略,在课堂上,老师只讲解了比例选择、轮盘赌两种方法。
2.2.1轮盘赌选择法
描述:
轮盘赌选择法是依据个体的适应度值计算每个个体在子代中出现的概率,并按照此概率随机选择个体构成子代种群。轮盘赌选择策略的出发点是适应度值越好的个体被选择的概率越大。因此,在求解最大化问题的时候,我们可以直接采用适应度值来进行选择。但是在求解最小化问题的时候,我们必须首先将问题的适应度函数进行转换,以将问题转化为最大化问题。

步骤:
1.调整适应度,确保自己想要的最优结果的适应度是最大值,以保证其在选择区间上占据最大的比例。[一般可以去倒数。]
2.将种群的适应度叠加,累次求和,在实操时,需要累次记录。最终的适应度总值为1。
3.计算每个个体的累积概率,以此构造一个轮盘。[也可以不计算累积概率,改用搜索算法来确定得到的随机数是在哪一个范围之内,属于哪个个体。]
4.选择。随机产生一个[0,1]的随机数,如果是累积概率,则可以直接判断是哪个个体,选择即可,如果不是累积概率,则要多一步操作。
5.重复以上步骤多次,得到所需的个体数量即可。
第三个步骤所描述的搜索算法:
# 插值搜索
# 输入:列表,要搜索的值,最低索引,最高索引
# 输出:相等时的索引,或者接近该值左侧的索引
# 备注:Python里面的递归有次数限制(99次)
def InsertionSearch(list,value,low,high):
mid=low+int((value-list[low])/(list[high]-list[low])*(high-low))
if list[mid]==value:
return mid
if list[mid]>value:
if list[mid-1]<value:
return mid-1
else:
return InsertionSearch(list,value,low,mid-1)
if list[mid]<value:
if list[mid+1]>value:
return mid
else:
return InsertionSearch(list,value,mid+1,high)
2.2.2比例选择法
描述:
选择所有个体中适应度占前60%的个体作为优秀个体加入下一代,其他的个体没有交配的权利,直接舍弃。
步骤:
1.将群体进行排序。
2.按照自己设置的适应度升序或者降序,取前60%以保留。
3.从这60%的个体里面随机复制个体,填补丢弃的40%个体。
4.每一轮操作一次。
2.2.3精英保留策略
描述:
精英个体,不老不死,只能被取代,不能遗传。
步骤:
在其他选择策略的基础之上,保留最优的个体,保证每每一轮这个个体都会被留下来,用临时变量保存,或者是不进行选择交叉变异,只要能留下,即可。
[这里有一种赌的思想,只要最优解出现,就一定会被保留,就能够得到正确结果,但是也有可能最优解在遗传过程之中根本就没有出现过。]
2.3交叉过程
交叉过程是说任意任意两个个体交换基因段的过程。

在上述过程中,说是要交叉两端的,检测两端的是否有重复,有重复就要与重复位置的对应位置互换,直到没有重复为止。
为了方便代码实现,将中间部分进行交换,作为循环的标尺,每次对两端进行检测,直到没有重复为止。
2.3变异
自我感觉变异过程是为了添加噪声。
描述:对于一个基因段的某个两个位置进行变异,也就是改变数值,但是需要保证变异之后一个基因内没有重复个体。
所以,比较好的方法直接选择两个位置进行交换。
备注:关于适应度的计算,这里就不作介绍了,不同的实验有不同的适应度,这也是解题的关键,倘若发现某个问题的适应度不会计算,那么这个时候就应该放下自己所思考的其他东西,首先弄明白适应度的计算公式。
3.源码
源码是可以直接运行的,复制粘贴保存即可。
自我感觉备注写的很完整,也很全面,是比较同意能够看懂的。
实验中调用了numpy的库,不懂的可以去看一看,它对于处理矩阵相关的东西很在行。
import numpy as np
import math
import random
# 適應度
def fitnessFunction(pop,num,city_num,distance):
length=city_num
for i in range(num):
dis=0
for j in range(length-1):
dis+=distance[int(pop[i][j])][int(pop[i][j+1])]
dis+=distance[int(pop[i][j+1])][int(pop[i][0])]
pop[i][-1]=20000/dis
# 選擇
def choiceFuction(pop):
numlist=[0]
length=len(pop)
allnum=0
for i in range(0,length):
allnum+=pop[i][-1]
numlist.append(allnum)
temppop=[] #用于临时的种群数据
max = pop[np.argmax(pop[:, -1])] #最优的一个个体
for i in range(0,length):
rannum=random.random()*numlist[-1] #0~1的小数乘上最大的数字,得到[0,max]上的一个点
ranIndex=InsertionSearch(numlist,rannum,0,length-1) #调用搜索函数
temppop.append(pop[ranIndex-1]) #将一个个的数据添加到
pop=np.array(temppop) #将pop索引指向临时数据,并且此处应该清理原来的pop空间才对
pop[0]=max.copy() #保证第一个元素就是最优的元素
return pop
# 插值搜索
# 输入:列表,要搜索的值,最低索引,最高索引
# 输出:相等时的索引,或者接近该值左侧的索引
# 备注:Python里面的递归有次数限制(99次)
def InsertionSearch(list,value,low,high):
mid=low+int((value-list[low])/(list[high]-list[low])*(high-low))
if list[mid]==value:
return mid
if list[mid]>value:
if list[mid-1]<value:
return mid-1
else:
return InsertionSearch(list,value,low,mid-1)
if list[mid]<value:
if list[mid+1]>value:
return mid
else:
return InsertionSearch(list,value,mid+1,high)
# 交叉变异(此处的交叉有两种情况)
# 输入:种群,交叉概率,城市数量(列),变异概率,种群数量(行)
# 输出:无输出,是一个过程(先交叉,再变异)
# 备注:不同的交叉策略,相邻,随机,配对
def matuingFuction(pop, pc, city_num, pm, num):
#产生两个不同的索引
rancon=True
while rancon :
p1=random.randint(1,city_num-1)
p2=random.randint(0,city_num-2)
if p1==p2:
rancon=True
elif p1<p2:
rancon=False
else:
temp=p1
p1=p2
p2=temp
pass
# 交叉,變異(每一对交换,1 and 2, 3 and 4, and so on)
# for i in range(1,num-1,2):
# # for j in range(0,num-1):
# # if i!=j:
# # pc2=random.random()
# # if(pc2
# # matuting(pop[i],pop[j],p1,p2)
# pc2=random.random()
# if pc2
# matuting(pop[i],pop[i+1],p1,p2)
# # print("poobefore:",pop[i])
# variationFunction(pop[i],pm,city_num)
# # print("pooend:",pop[i])
# variationFunction(pop[i+1],pm,city_num)
# 交叉,變異(相邻两个进行交换)
for i in range(1,num-1):
pc2=random.random()
if pc2<pc:
matuting(pop[i],pop[i+1],p1,p2)
variationFunction(pop[i],pm,city_num)
# 交叉过程
# 输入:第一行数据x1,第二行数据x2,左侧断点,右侧断点
# 输出:惊醒过交叉的两行数据
# 备注:由于函数是单次检测,所以需要调用两次内部函数
def matuting(x1, x2, p1, p2):
length=len(x1)-1
temp=x1[p1:p2].copy()
x1[p1:p2]=x2[p1:p2]
x2[p1:p2]=temp
#自定義交換函數,需要調用兩次才能夠將其完全的排列好
def change(x1,x2,p1,p2):
#检查元素
isrepeat=True
while isrepeat:
countTrue=0
for i in range(p1,p2):
for j in range(0,p1):
if int(x1[j])==int(x1[i]):
isrepeat=True
countTrue+=1
x1[j]=x2[i]
for k in range(p2,length):
if int(x1[k])==int(x1[i]):
isrepeat=True
countTrue+=1
x1[k]=x2[i]
if countTrue==0:
isrepeat=False
#調用交換函數,兩次
change(x1,x2,p1,p2)
change(x2,x1,p1,p2)
# 变异过程
# 输入:一行数据,变异概率,城市数量
# 输出:行内交换元素的一行数据
# 备注:似乎数据交换不需要定义临时变量
def variationFunction(list_a, pm, city_num):
if random.random()<pm:
i=random.randint(0,city_num-1)
isequal=True
while isequal:
j=random.randint(0,city_num-1)
if(j==i): isequal=True
else: isequal=False
pass
#交换两个数据
list_a[i],list_a[j]=list_a[j],list_a[i]
# 主函数
def main():
# 初始化
pop = [] # 存放访问顺序和每个个体适应度@
num = 700 # 初始化群体的数目@
city_num = 10 # 城市数目@
pc = 0.9 # 每个个体的交配概率S@
pm = 0.3 # 每个个体的变异概率@
dis="0,118,1272,2567,1653,2097,1425,1177,3947,1574,118,0,1253,2511,1633,2077,1369,1157,3961,1518,1272,1253,0,1462,380,1490,821,856,3660,385,2567,2511,1462,0,922,2335,1562,2165,3995,933,1653,1633,380,922,0,1700,1041,1135,3870,456,2097,2077,1490,2335,1700,0,2311,920,2170,1920,1425,1369,821,1562,1041,2311,0,1420,4290,626,1177,1157,856,2165,1135,920,1420,0,2870,1290,3947,3961,3660,3995,3870,2170,4290,2870,0,4090,1574,1518,385,993,456,1920,626,1290,4090,0"
# #获取输入的十个城市之间距离,并将它们转化为numpy的array,并重新reshape成10*10的二维数组distance@
# distance1 = input().split(",")
distance1=dis.split(",")
distance2 = np.array(distance1,dtype=np.int)
distance = distance2.reshape((10, 10))
for i in range(num):
pop.append(np.random.permutation(np.arange(0,city_num))) # 假设有10个城市,初始群体的数目500个@
zero = np.zeros((num,1)) # 返回给定形状和类型的新数组,用零填充。二维数组,num行2列@
pop = np.column_stack((pop, zero)) # 矩阵的拼接@
fitnessFunction(pop, num, city_num, distance) # 为初始种群赋予自适应度@
pop=choiceFuction(pop)
# 遗传算法迭代,250为迭代次数,同学们可以对其进行调整@
for i in range(250):
matuingFuction(pop,pc,city_num,pm,num) # 交叉變異
fitnessFunction(pop,num,city_num,distance) # 計算適應度
pop=choiceFuction(pop) # 選擇
#输出自适应度最大解个体并计算其路径长度@
max = pop[np.argmax(pop[:, -1])]
sum = 0
for x2 in range(city_num - 1):
sum += distance[int(max[x2])][int(max[x2 + 1])]
sum += distance[int(max[9])][int(max[0])]
print(sum)
# 运行函数
if __name__=="__main__":
main()
# 值类型:int, float, bool, str, tuple
# 引用类型:list, dict, set
4.结果
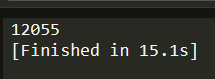
结果很简单,就是一个最优解,这个结果不是很稳定,大部分时候会输出12055,有的时候也会输出12062,
看命吧。
如果想要更仔细的观察遗传的过程,可以在每次选择的时候输出此最好的适应度。
如果想要更精确的得到结果,可以调整参数或者是修改选择策略,也可以调整适应度的计算公式。
5.总结
打字看心情,突然心情不好不知道作何总结。
此次遗传算法实验是针对于全连通图的旅行商问题的一种解决策略,将一个完整回路的距离的相关函数作为实用度,将各个城市作为基因,将每一种回路作为一个个体,模拟遗传进化,最终趋向最优解或者就是最优解。
遗传算法的不足之处:
- 遗传算法的效率会比其他传统的优化方法低。
- 遗传算法容易过早的收敛。[
我以为只这是局部最优化问题] - 对于算法精度、可行度、计算复杂性等方面没有有效的定量分析方法。
一些学习遗传算法的链接:
- 旅行商(TSP)问题专题——多种方法对比
- 【算法】超详细的遗传算法(Genetic Algorithm)解析
- 遗传算法详解(GA)(个人觉得很形象,很适合初学者)