爬虫(四):Selenium+Phantomjs介绍
文章目录
- 一、动态html页面的处理方法
- 二、selenium+phantomjs
- 1.了解
- 2.下载selenium
- 3.下载两个插件phantomjs和Chromeedriver
- ①phantomjs环境变量的配置
- ②安装chromedriver
- 4.selenium+Chrome的配合使用
- 5.改为selenium+phantomjs无界面浏览器后可加可运行速度
- 6.用selenium+phantomjs请求页面的流程
一、动态html页面的处理方法
| 种类 | 介绍 |
|---|---|
| js | html是页面的表现,css是叶面的装饰,js负责页面的动作 |
| jquery | jquery是一个js库,可以简化js代码 |
| Ajax | ajax是一个异步请求 |
| DHTML | 动态的html(标准通用标记语言下的一个应用),是相对传统的静态的html而言的一种制作网页的概念。 |
二、selenium+phantomjs
1.了解
-
selenium:web自动测试工具
-
pantomjs:是一个无界面的浏览器,所以他可以运行js代码,帮我们拿到页面数据。
所以selenium+phantomjs可以解决js代码拿数据的问题
2.下载selenium
selenium可以通过百度下载:http://npm.taobao.org/mirrors/selenium
selenium也可以通过pip安装
pip install selenium==2.48.0
3.下载两个插件phantomjs和Chromeedriver
①phantomjs环境变量的配置
-
phantomjs可以通过百度下载:http://npm.taobao.org/mirrors/phantomjs
-
将插件安装在anaconda/scripts文件下面
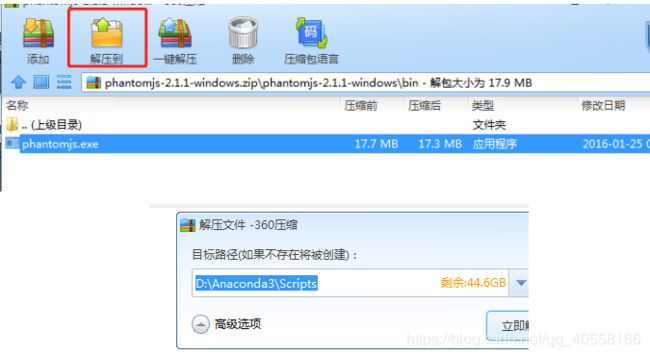
②安装chromedriver
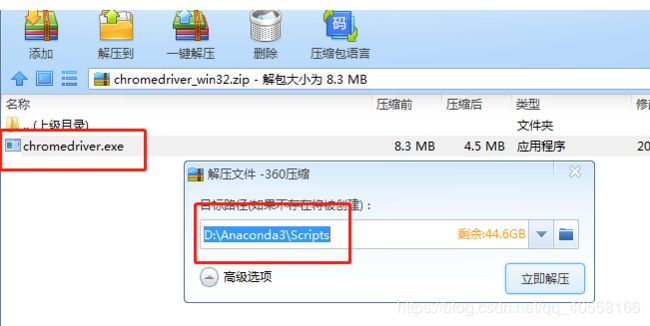
下载地址:http://npm.taobao.org/mirrors/chromedriver/
在谷歌下载最接近自己版本g弍浏览器的版本放在该文件下,可以使selenium变为可视化
4.selenium+Chrome的配合使用
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# -----1.创建一个浏览器驱动
driver = webdriver.Chrome()
# -----2.请求url
driver.get('http://www.baidu.com/')
# 查看标题
print(driver.title)
# 查看cookies
print(driver.get_cookies())
# 查找标签元素
# driver.find_element_by_id('kw').send_keys()
# webelement对象
webEle = driver.find_element_by_id('kw')
input = driver.find_element_by_id('kw')
input.send_keys('蔡徐坤') # 寻找百度搜索框,并写入Unicode编码的蔡徐坤
submit = driver.find_element_by_id('su')
submit.click() # 寻找搜索框的确定按钮点击
driver.save_screenshot('cxk1.jpg') # 截屏
print(driver.current_url)#当前url
print(driver.name)#查看浏览器名字
# 将某个输入框的输入东西删除
input.send_keys(Keys.CONTROL, 'a') # 全选
input.send_keys(Keys.CONTROL, 'x') # 剪切
# 查看input元素的坐标
# input.send_keys('周杰伦')
# print(input.location)#{'x': 129, 'y': 18}
# #查看元素大小
# print(input.size)#{'height': 22, 'width': 395}
#
# #常用的查找element对象的方法
# driver.find_element_by_id('kw')
# driver.find_element_by_css_selector('#kw').send_keys('aa')#css选择器
# # driver.find_element_by_xpath()
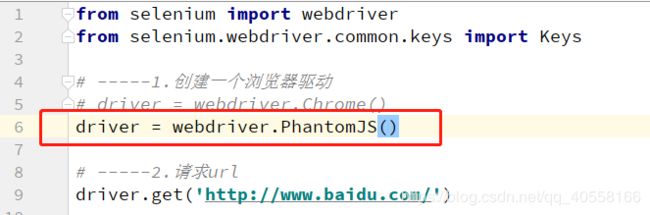
5.改为selenium+phantomjs无界面浏览器后可加可运行速度
1.获取当前页面的Url
方法:current_url 实例:driver.current_url
2.获取元素坐标
方法:location
解释:首先查找到你要获取元素的,然后调用location方法 实例:driver.find_element_by_xpath("xpath").location
3.表单的提交
方法:submit
解释:查找到表单(from)直接调用submit即可
实例:driver.find_element_by_id("form1").submit()
4.获取CSS的属性值
方法:value_of_css_property(css_name)
实例:driver.find_element_by_css_selector("input.btn").value_of_css_property("input.btn")
5.获取元素的属性值
方法:get_attribute(element_name)
实例:driver.find_element_by_id("kw").get_attribute("kw")

6.判断元素是否被选中
方法:is_selected()
实例:driver.find_element_by_id("form1").is_selected()
7.返回元素的大小
方法:size
实例:driver.find_element_by_id("iptPassword").size 返回值:{'width': 250, 'height': 30}
8.判断元素是否显示
方法:is_displayed()
实例:driver.find_element_by_id("iptPassword").is_displayed()
9.判断元素是否被使用
方法:is_enabled()
实例:driver.find_element_by_id("iptPassword").is_enabled()
10.获取元素的文本值
方法:text
实例:driver.find_element_by_id("iptUsername").text
11.元素赋值
方法:send_keys(*values)
实例:driver.find_element_by_id("iptUsername").send_keys('admin')
12.返回元素的tagName
方法:tag_name
实例:driver.find_element_by_id("iptUsername").tag_name
13.删除浏览器所有的cookies
方法:delete_all_cookies()
实例:driver.delete_all_cookies()
14.删除指定的cookie
方法:delete_cookie(name)
实例:deriver.delete_cookie("my_cookie_name")
15.关闭浏览器
方法:close()
实例:driver.close()
16.关闭浏览器并且退出驱动程序
方法:quit()
实例:driver.quit()
17.返回上一页
方法:back()
实例:driver.back()
18.清空输入框
方法:clear()
实例:driver.clear()
19.浏览器窗口最大化
方法:maximize_window()
实例:driver.maximize_window()
20.查看浏览器的名字
方法:name
实例:drvier.name
21.返回当前会话中的cookies
方法:get_cookies()
实例:driver.get_cookies()
22.根据cookie name 查找映射Value值
方法:driver.get_cookie(cookie_name)
实例:driver.get_cookie("NET_SessionId")
23.截取当前页面
方法:save_screenshot(filename)
实例:driver.save_screenshot("D:\\Program Files\\Python27\\NM.bmp")
6.用selenium+phantomjs请求页面的流程
-
导包
from selenium import webdriver -
创建driver对象
driver=webdriver.Phantomjs() -
等待(等待有三种方法)
-
强制等待
time.sleep(5) -
隐式等待(就是等待页面全部加载完成,例如css图片js等)
driver.implicitly_wait(10) -
显示等待
from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By #-------------------------------------步骤: #1.创建等待对象 wait = WebDriverWait( driver,#浏览器驱动对象 10,最大等待时长 0.5,扫描间隔 ) #2.wait.until(等待条件)--->等待条件成立程序才继续运行。 #等待条件在selenium中有个专门的模块来设置了一些条件--expected_conditions as EC #最常用的条件有一下两个:这两个条件验证元素是否出现,传入的参数都是元组类型的locator,如(By.ID, 'kw') EC.presence_of_element_located#一个只要一个符合条件的元素加载出来就通过; EC.presence_of_all_elements_located# 另一个必须所有符合条件的元素都加载出来才行 EC.presence_of_element_located(locator对象也就是定位器) licator对象是一个元组(通过什么来查找,--By.ID,By.XPATH,By.CSS_SELECTOR‘查找的内容的语法’) #3.wait.until方法的返回值是一个对应定位器所定位到的webelement对象。你如果需要对这个webelment对象做一些点击或者其他操作,可以很方便的做到。 #4获取页面内容 html = driver.page_source #5.用lxml模块解析页面内容 tree = etree.HTML(html)
-
-
获取页面内容
html=driver.page_source -
用lxml模块解析页面内容
tree=etree.HTML(html)