使用 PyRsa 库解决新版正方教务的 RSA 加密问题并模拟登陆的 Python 实现
前言
先前有一个契机,需要模拟登陆学校所使用的正方教务来获取课程表,其所使用的 RSA 加密方法没有现成的 Python 库可使用,目前其他的 CSDN 博客所采用的方法均无法成功登陆,故只能自己研究正方教务所采用的 crypto/rsa 的 JavaScript 实现并转义为 Python 语言实现。现开源为 PyRsa 库发布到 PyPI。
PyRsa 使用
安装
pip install pyrsa
基本介绍
本模块的基本思路为 1:1 等价转义原生的 JavaScript 库,正方教务上的加密库与安装后 PyRsa 库文件截图对比:
其中有几个移植 JavaScript 到 Python 过程中值得注意的问题:
- 无符号整数位移
由于 Python 独特的数据类型特性,在数据超过其数据类型长度后则会自动转化为 long,因此不存在JavaScript的 “>>>” 或者 “<<<” 的无符号整数操作,因此需要利用右移操作符 “>>” 来实现无符号整数右移:
def unsigned_right_shift(n, i):
"""
无符号整数右移
:param n:
:param i:
:return:
"""
def int_overflow(val):
maxint = 2147483647
if not -maxint - 1 <= val <= maxint:
val = (val + (maxint + 1)) % (2 * (maxint + 1)) - maxint - 1
return val
# 数字小于 0,则转为 32 位无符号 uint
if n < 0:
n = ctypes.c_uint32(n).value
# 正常位移位数是为正数,但是为了兼容 js 之类的,负数就右移变成左移
if i < 0:
return -int_overflow(n << abs(i))
# print(n)
return int_overflow(n >> i)
- 原生 js 库 jsbn 用来实现任意精度的整数算法,其 API 类似于java.math.BigIntegerJava 中的 类。在此库中,BigInteger 为一个 Array() 类,但考虑到 Python 的数据类型结构,PyRsa 库采用名为 int_dict 的字典来存储,其键值对与 Array() 的数据一一对应。

在下图中演示的是在 modulus 和 exponent 相同时 Python 实现的 BigInteger 类与 jsbn 库实现的 BigInteger 类的对应情况。其余参数对应 BigInteger 类的 proto 隐式原型。
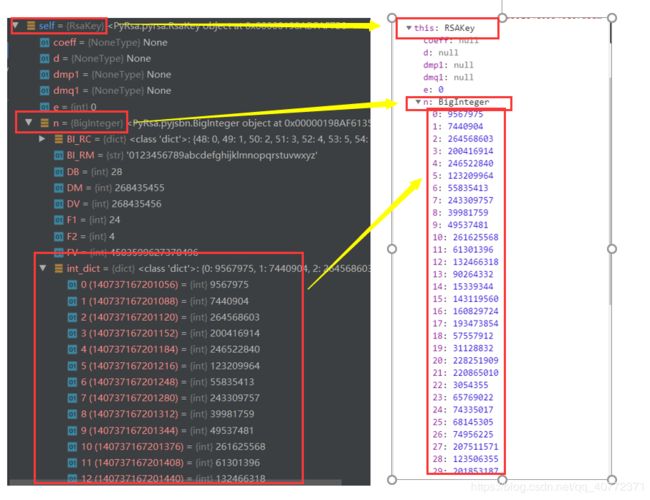
- 利用 rng.js 库随机生成 seed 来填充字符串,使得每一次对相同原密码的加密后的字符串不可能重复产生。
基本使用
使用 RsaKey 模块
由于本模块是面向正方教务的加密,因此 modulus 长度应为 172;如果单纯是加密着玩的话,那么 modulus 与 pre_psw 两个参数的长度则有所限制,大概就是
modulus = int(psw / 3) + 15 + psw
嘛,谁会这么无聊干这事儿呢
from PyRsa.pyrsa import RsaKey
from PyRsa.pyb64 import Base64
modulus = "AJftLhHzsQPu1LwCgOR41hRKn4tbaD/ehyZKiBWDYCpaualtMyJIT0SzBl07O2NwjxI8uwr82SMvEW9iiSEoBylHOWNnEzyOYwXb29xMo+D4LTVqMX7NkAliIqH+wOSA1g0DVxmcQWCtGVI4vDUnGIN8tYPlxc9NIXN5zO0HwqKn"
exponent = 'AQAB'
rsakey.set_public(Base64().b64tohex(modulus), Base64().b64tohex(exponent))
psw = '1234567890'
en_psw = Base64().hex2b64(rsakey.encrypt(pre_psw))
模拟登陆正方教务
拿到经过 PyRsa 加密后的字符串后,就可以开始进行正方教务的模拟登陆了。新版正方教务基本样式如下:

完整实现思路
1. 黑盒模型

最终获取到的 JSESSIONID 相当于整个教务的唯一识别代码,可用其获取得到任意想获取到的数据。换句话说,JSESSIONID 包含了用户的模拟登陆信息,并有一定的生命周期(没具体测过,不超过一天)。
2. 主要函数实现:
-
获取初始 cookies:

通过抓包,在 login_slogin.html 页面的 Response Headers 找到 Set-Cookie 的两个参数 BIPipServerjwxtnew_BS80 和 JSESSIONID。
代码实现如下:def get_raw_cookies_csrf(self): headers = { 'Host': f'{self.domain}', 'Connection': 'keep-alive', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/76.0.3809.87 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;' 'q=0.8,application/signed-exchange;v=b3', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8' } url = f'http://{self.domain}/jwglxt/xtgl/login_slogin.html' res = self.session.get(url, headers=headers) doc = pq(res.text) self.csrf = doc('#csrftoken').attr('value') self.raw_cookie = requests.utils.dict_from_cookiejar(res.cookies) -
获取 modulus 和 exponent 两个参数生成 RSA 公钥

利用上一步获取到的初始 cookies 的两个参数,在 xhr 异步网页 login_getPublicKey.html 用 GET 方法可以获取到对应 json 的两个参数 exponent 和 modulus。def get_json(self): self.getpublickey_t = int(time.time() * 1000) url = f'http://{self.domain}/jwglxt/xtgl/login_getPublicKey.html?time={self.getpublickey_t}' headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Cookie': f'JSESSIONID={self.raw_cookie["JSESSIONID"]};' f' BIGipServerjwxtnew_BS80={self.raw_cookie["BIGipServerjwxtnew_BS80"]}', 'Host': f'{self.domain}', 'Referer': f'http://{self.domain}/jwglxt/xtgl/login_slogin.html', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/76.0.3809.87 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest' } try: res = self.session.get(url, headers=headers) rj = res.json() return rj['modulus'], rj['exponent'] except: print('Fail') -
登录完成后 login_slogin.html 抓包情况

其中 time 为登陆时的时间戳,mm 为加密后的字符串。值得考量的是,提交的表单中存在两个相同的 mm 参数,这是因为在 login.js 文件里存在以下源码:

也就是说,表单提交的两个 mm 实际上就是为可见密码输入框和不可见密码输入框填充数值。实际上我们只需提供一个 mm 赋予可见的输入框即可。而这个表单提交过程,就是整个模型的黑盒子。def get_jsessionid(self): rsakey = RsaKey() m, e = self.get_json() rsakey.set_public(Base64().b64tohex(m), Base64().b64tohex(e)) rr = rsakey.rsa_encrypt(self.mm) enpsw = Base64().hex2b64(rr) # print('csrf:', self.csrf) # print('mm:', enpsw) data = { 'csrftoken': self.csrf, 'yhm': self.yhm, 'mm': enpsw } headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;' 'q=0.8,application/signed-exchange;v=b3', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Content-Length': '470', 'Content-Type': 'application/x-www-form-urlencoded', 'Cookie': f'JSESSIONID={self.raw_cookie["JSESSIONID"]}; ' f'BIGipServerjwxtnew_BS80={self.raw_cookie["BIGipServerjwxtnew_BS80"]}', 'Host': f'{self.domain}', 'Origin': f'http://{self.domain}', 'Referer': f'http://{self.domain}/jwglxt/xtgl/login_slogin.html', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/76.0.3809.87 Safari/537.36' } dt = random.randint(5, 10) # dt 的作用实际上是尽可能模拟浏览器,浏览器上获取公钥页相对于此页面有些许延迟,事实上不减去 dt 也能正常运行 url = f'http://{self.domain}/jwglxt/xtgl/login_slogin.html?time={self.getpublickey_t - dt}' # print(self.getpublickey_t - dt) res = self.session.post(url, headers=headers, data=data) if len(res.history) and res.history[0].status_code == 302: js = requests.utils.dict_from_cookiejar(res.history[0].cookies) return js['JSESSIONID'] else: print('Fail to get JSESSIONID!')至此,正方教务模拟登陆完结撒花。
完整代码如下(包含课程表的获取)
# -*- coding: utf-8 -*-
"""
Created on: 2019/9/30 16:14
Author : zxt
File : rsatest.py
Software : PyCharm
Version : Python 3.7
"""
import random
import time
import requests
import json
from pyquery import PyQuery as pq
from PyRsa.pyrsa import RsaKey
from PyRsa.pyb64 import Base64
def is_useful_jsessionid(jsessionid, bigipserver):
"""
此函数用来测试获取到的 JSESSIONID 是否可用
:param jsessionid:
:param bigipserver:
:return:
"""
kb_url = 'http://{self.domain}/jwglxt/kbcx/xskbcx_cxXsKb.html?gnmkdm=N253508'
kb_headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Content-Length': '14',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Cookie': f'JSESSIONID={jsessionid}; BIGipServerjwxtnew_BS80={bigipserver}',
'Host': '{self.domain}',
'Origin': 'http://{self.domain}',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://{self.domain}/jwglxt/kbcx/xskbcx_cxXskbcxIndex.html?gnmkdm=N253508'
'&layout=default&su=201730615063',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/76.0.3809.87 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'
}
data = {
'xnm': 2019,
'xqm': 3
}
res = requests.post(kb_url, headers=kb_headers, data=data)
if res.status_code == 200:
return True
return False
class TimeTable:
def __init__(self, yhm, mm):
self.yhm = yhm
self.mm = mm
self.session = requests.Session()
self.raw_cookie = {}
self.domain = 'xxx.com' ## 换成使用新版正方教务的学校域名
def get_raw_cookies_csrf(self):
headers = {
'Host': f'{self.domain}',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/76.0.3809.87 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;'
'q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
}
url = f'http://{self.domain}/jwglxt/xtgl/login_slogin.html'
res = self.session.get(url, headers=headers)
doc = pq(res.text)
self.csrf = doc('#csrftoken').attr('value')
self.raw_cookie = requests.utils.dict_from_cookiejar(res.cookies)
# print('JSESSIONID', self.raw_cookie['JSESSIONID'])
# print('BIGipServerjwxtnew_BS80', self.raw_cookie['BIGipServerjwxtnew_BS80'])
def get_json(self):
self.getpublickey_t = int(time.time() * 1000)
url = f'http://{self.domain}/jwglxt/xtgl/login_getPublicKey.html?time={self.getpublickey_t}'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Cookie': f'JSESSIONID={self.raw_cookie["JSESSIONID"]};'
f' BIGipServerjwxtnew_BS80={self.raw_cookie["BIGipServerjwxtnew_BS80"]}',
'Host': f'{self.domain}',
'Referer': f'http://{self.domain}/jwglxt/xtgl/login_slogin.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/76.0.3809.87 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
try:
res = self.session.get(url, headers=headers)
rj = res.json()
return rj['modulus'], rj['exponent']
except:
print('Fail')
def get_jsessionid(self):
# csrf = self.get_csrf()
rsakey = RsaKey()
m, e = self.get_json()
rsakey.set_public(Base64().b64tohex(m), Base64().b64tohex(e))
rr = rsakey.rsa_encrypt(self.mm)
enpsw = Base64().hex2b64(rr)
# print('csrf:', self.csrf)
# print('mm:', enpsw)
data = {
'csrftoken': self.csrf,
'yhm': self.yhm,
'mm': enpsw
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;'
'q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '470',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': f'JSESSIONID={self.raw_cookie["JSESSIONID"]}; '
f'BIGipServerjwxtnew_BS80={self.raw_cookie["BIGipServerjwxtnew_BS80"]}',
'Host': f'{self.domain}',
'Origin': f'http://{self.domain}',
'Referer': f'http://{self.domain}/jwglxt/xtgl/login_slogin.html',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/76.0.3809.87 Safari/537.36'
}
dt = random.randint(5, 10)
url = f'http://{self.domain}/jwglxt/xtgl/login_slogin.html?time={self.getpublickey_t - dt}'
# print(self.getpublickey_t - dt)
res = self.session.post(url, headers=headers, data=data)
if len(res.history) and res.history[0].status_code == 302:
js = requests.utils.dict_from_cookiejar(res.history[0].cookies)
ll = self.parser(js['JSESSIONID'])
print(ll)
else:
print('Fail to get courses')
def parser(self, js):
"""
解析教务处,取出课程表数据
:return:
"""
url = f'http://{self.domain}/jwglxt/kbcx/xskbcx_cxXsKb.html?gnmkdm=N253508'
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Content-Length': '23',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Cookie': f'JSESSIONID={js}; '
f'BIGipServerjwxtnew_BS80={self.raw_cookie["BIGipServerjwxtnew_BS80"]}',
'Host': f'{self.domain}',
'Origin': f'http://{self.domain}',
'Referer': f'http://{self.domain}/jwglxt/kbcx/xskbcx_cxXskbcxIndex.html'
'?gnmkdm=N253508&layout=default&su=201864730502',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/76.0.3809.87 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
from_data = {
'xnm': '2019',
'xqm': '3'
}
resp = self.session.post(url, headers=headers, data=from_data)
if resp.status_code == 200:
res = resp.text
# print(json.loads(res)['kbList'])
courses = []
courses_d = {}
for course in json.loads(res)['kbList']:
courses_d['location'] = course['cdmc']
if len(self._section2list(course['jcs'])):
courses_d['startTime'] = self._section2list(course['jcs'])[0]
courses_d['endTime'] = self._section2list(course['jcs'])[-1]
courses_d['name'] = course['kcmc']
# courses_d['point'] = course['xf']
courses_d['teacher'] = course['xm']
courses_d['day'] = course['xqj']
courses_d['weeks'] = self._weeks2list(course['zcd'])
courses.append(courses_d)
courses_d = {}
return self.tran2everyday(courses)
else:
print('Fail to get courses!')
def _section2list(self, s='3-4'):
"""
将节数转为数组
:param s:
:return:
"""
sections = []
if '-' in s:
sections += [i for i in range(int(s.split('-')[0]), int(s.split('-')[1]) + 1)]
return sections
def _weeks2list(self, s='1-11周,14周'):
"""
将周数转为数组
:param s:
:return:
"""
weeks = []
for week in s.replace(',', '').split('周')[:-1]:
if '-' in week:
weeks += [i for i in range(int(week.split('-')[0]), int(week.split('-')[1]) + 1)]
else:
weeks.append(int(week))
return weeks
def tran2everyday(self, raw=None):
"""
将原数据(按课程分)转化为按 周-天-课程 的格式
:param raw: []
:return: str
"""
if raw is None:
raw = []
week_courses = {}
for i in range(1, 26):
week_courses[f'week{i}'] = {f'day{j}': []for j in range(1, 8)}
for course in raw:
if i in course['weeks']:
for j in range(1, 8):
if str(j) == course['day']:
week_courses[f'week{i}'][f'day{j}'].append(course)
# print(week_courses)
for i in range(25, 0, -1): # 从后往前除去没有课的周
if self._is_courses(week_courses[f'week{i}']): # 从后往前出现第一个有课的周终止
break
else:
del week_courses[f'week{i}'] # 删除没有课的周
return str(week_courses).replace("'", '"')
def _is_courses(self, d):
"""
判断某个周是否存在课程
:param d:
:return: bool
"""
for day in d:
if len(d[day]):
return True
continue
return False
def operator(self):
self.get_raw_cookies_csrf()
self.get_jsessionid()
if __name__ == '__main__':
tt = TimeTable('2017xxxxxxxx', '1234567890')
tt.operator()
运行结果:
