(P4)使用keras进行多分类问题
今天使用keras中的fashionminst数据集进行的,是一个关于识别服饰的多分类问题,新知识有
| 知识点 | |
|---|---|
| 导入数据集 | tf.keras.datasets.fashion_mnist.load_data() |
| 看图片 | plt.imshow(train_image[1]) & plt.show() |
| 看数据集尺寸 | print(train_image.shape) |
| 归一化处理 | 当像素点值在0-255可以归一化为0-1 |
| 当输入是矩阵怎么办 | model.add(tf.keras.layers.Flatten(input_shape=(28,28))) |
| 多分类问题 | tf.keras.layers.Dense(10, activation=‘softmax’) & 最后一层要注意 |
| 损失函数 | loss=‘sparse_categorical_crossentropy’ & label是数字列表 |
| 独热编码(one-hot) | loss=‘categorical_crossentropy’ |
| 测试集测试 | model.evaluate(test_image, test_label) |
完整代码
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
# print(train_image.shape) # (60000, 28, 28)用shape函数输出训练集size,6000张图片每一个28*28
# plt.imshow(train_image[1])
# plt.show()
# print(train_image[1])
# print(train_label[1]) # 0
#进行归一化处理
train_image = train_image/255
test_image = test_image/255
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
model.fit(train_image, train_label, epochs=5)
model.evaluate(test_image, test_label) # 用测试集进行测试
各部分详细讲解
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
和往常一样,先导入需要用到的库
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
# print(train_image.shape) # (60000, 28, 28)用shape函数输出训练集size,6000张图片每一个28*28
获得我们需要的数据集,并且用shape函数看一看训练集的size
plt.imshow(train_image[1])
plt.show()
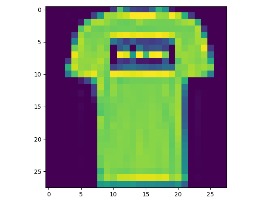
用plt.imshow()看一看训练集的第2个图片,是一件T-shirt
print(train_image[1])
# np.max(train_image[1]) # 这个可以看矩阵中的最大值是255

只截取了一部分,可以看到是28*28的矩阵,每一个像素有一个值代表颜色(取值在0-255)
print(train_label[1]) # 0
训练集中第2个数据的label是0,代表的是T-shirt
建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
因为输入的是一个28*28的矩阵,所以不能用Dense,我们用Flatten将矩阵扁平成一个向量
model.add(tf.keras.layers.Dense(128, activation='relu'))
第二层设定为128个神经元,因为考虑到特征比较多,activation选用relu
model.add(tf.keras.layers.Dense(10, activation='softmax'))
输出的时候,因为是多分类过程(具体来说是10分类),所以输出10个,activation用softmax
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
损失函数loss选择sparse_categorical_crossentropy,是因为多分类问题的lebal是像[0,1,2,3,4]这种数字的情况
同时在训练时将准确度显示出来
model.fit(train_image, train_label, epochs=5)
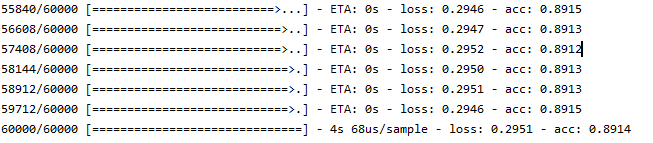
用60000张图片的训练集进行训练,训练5次
训练结束后准确度为89%`
model.evaluate(test_image, train_label)
用测试集去测试model的性能
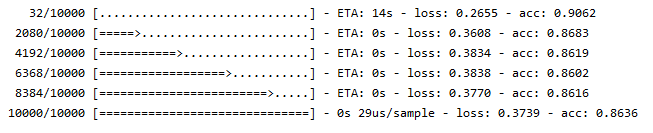
可以看到model在测试集上的准确度是86%