pytorch系列笔记二:批处理与优化器选择
pytorch系列笔记二:批处理与优化器选择
批处理
批处理对于神经网络的训练是必不可少的,通过对有限数据的shuffle并重新送入模型,因为训练的数据更多了,所以可以提高模型的训练效果
在Pytorch中要使用批处理需要进行如下步骤:
-
利用数据集创建一个
TensorDataset:-
#### Download and construct CIFAR-10 dataset. train_dataset = torchvision.datasets.CIFAR10(root='../data/', train=True, transform=transforms.ToTensor(), download=False) -
#### make custom data be a TensorDataset torch_dataset = torch.utils.data.TensorDataset(x, y) -
# You should build your custom dataset as below. class CustomDataset(torch.utils.data.Dataset): def __init__(self): # TODO # 1. Initialize file paths or list of file names pass def __getitem__(self,index): # TODO # 1.Read one data from file (e.g. using numpy.fromfile,PIL.image.open) # 2. Preprocess the data (e.g. torchvision.Transform). # 3. Return a data pair (e.g. image and label). pass def __len__(self): # You should change 0 to the total size of your dataset return 0 # You can then use the prebuilt data loader custom_dataset = CustomDataset() train_loader = torch.utils.data.DataLoader(dataset=custom_dataset, batch_size=64, shuffle=True)
-
-
使用
TensorDataset创建DataLoader:loader = torch.utils.data.DataLoader( dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, # shuffle=False, num_workers=2, ) -
使用
DataLoader的实例化对象,通过循环一批一批地从数据集中采集样本:for epoch in range(3): for step, (batch_x, batch_y) in enumerate(loader): # TODO:training print('EPOCH:', epoch, '| Step:', step, '| batch x:', batch_x.numpy(), '| batch_y:', batch_y.numpy())
通过下面程序的结果可以理解批处理的作用:
import torch
from torch.utils import data
# BATCH_SIZE = 5
BATCH_SIZE = 8
# 10 samples
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
torch_dataset = data.TensorDataset(x, y)
loader = data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
# shuffle=False,
num_workers=2,
)
if __name__ == '__main__':
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
# TODO:training
print('EPOCH:', epoch, '| Step:', step, '| batch x:',
batch_x.numpy(), '| batch_y:', batch_y.numpy())
输出:
EPOCH: 0 | Step: 0 | batch x: [ 1. 4. 10. 8. 7. 9. 2. 5.] | batch_y: [10. 7. 1. 3. 4. 2. 9. 6.]
EPOCH: 0 | Step: 1 | batch x: [3. 6.] | batch_y: [8. 5.]
EPOCH: 1 | Step: 0 | batch x: [ 2. 9. 8. 3. 5. 4. 10. 6.] | batch_y: [9. 2. 3. 8. 6. 7. 1. 5.]
EPOCH: 1 | Step: 1 | batch x: [7. 1.] | batch_y: [ 4. 10.]
EPOCH: 2 | Step: 0 | batch x: [ 5. 4. 7. 10. 6. 1. 2. 3.] | batch_y: [ 6. 7. 4. 1. 5. 10. 9. 8.]
EPOCH: 2 | Step: 1 | batch x: [8. 9.] | batch_y: [3. 2.]
优化器的选择
越复杂的神经网络,越多的数据会导致我们在训练神经网络所需花费的时间越多,所以需要寻找加速神经网络训练的优化器,使得神经网络的训练变得快起来。
最基础的神经网络训练方法为SGD(随机梯度下降法)
每次使用随机的一个Mini-Batch数据来进行梯度下降,在进行多次Epoch后也可以达到与使用原始梯度下降法一样的效果,而且速度大大提升。
前面有过一次手写实现,可以体现其处理数据的核心逻辑
def dJ_sgd(theta,X_b_i,y_i):
# 只对一个样本做梯度下降处理
return X_b_i.T.dot(X_b_i.dot(theta)-y_i) *2
def sgd(X_b,y,initial_theta,n_iters):
t0 = 5
t1 = 50
def learn_rate(t):
return t0/(t+t1)
theta = initial_theta
for cur_iter in range(n_iters):
# 每次从所有样本中随机抽取一个样本做梯度计算
rand_i = np.random.randint(len(X_b))
gradient = dJ_sgd(theta,X_b[rand_i],y[rand_i])
theta = theta - learn_rate(cur_iter) * gradient
return theta
Momentum
传统的参数更新公式:
w i = w i − l r ∗ ∇ w i w_i =w_i- lr * \nabla w_i wi=wi−lr∗∇wi
这种方法可能会使得学习过程曲折无比:
拿movan的话说,就像一个酒鬼在平地上走路。

Moment就是将酒鬼放在一个斜坡上,使得酒鬼因为惯性不得不随着下降方向前进:
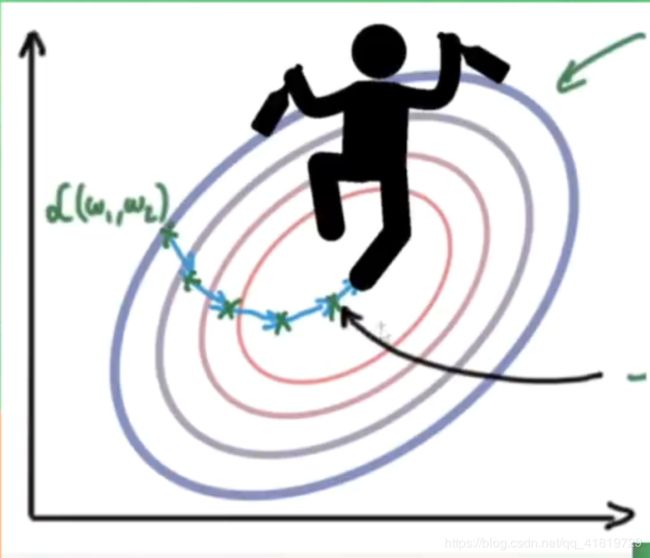
数学形式为:
m = b 1 ∗ m − l r ∗ ∇ w i w i = w i + m m = b1*m-lr* \nabla w_i \\ w_i = w_i + m m=b1∗m−lr∗∇wiwi=wi+m
AdaGrad
这种方法是在学习率上做手脚,每当下降的方向不对,学习率就得到相应的减少,这样就像是给了酒鬼一双不好走的鞋子,使得他摇晃着走路的时候就发现脚疼,鞋子变成了走弯路的阻力。
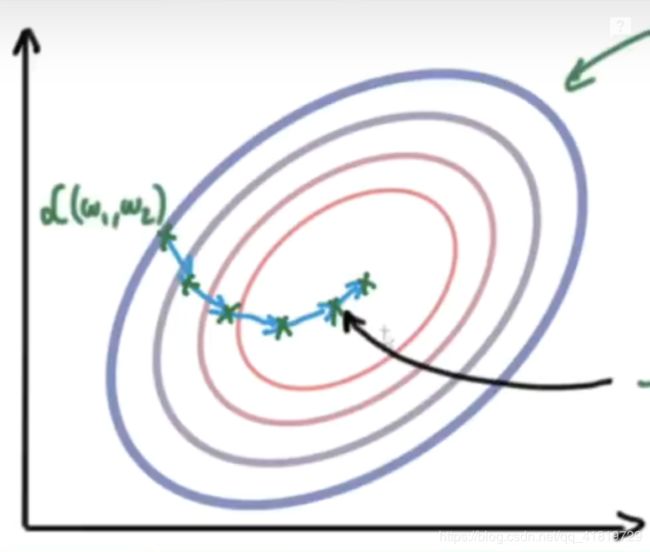
数学形式为:
v = v + ∇ w i 2 w i = w i − l r ∗ ∇ w i v v =v+ {\nabla w_i}^2\\ w_i = w_i-lr* \frac{\nabla w_i}{\sqrt{v}} v=v+∇wi2wi=wi−lr∗v∇wi
RMSProp
RMSProp结合了Momentum与AdaGrad的优势,将二者的优化参量都引入到自己的数学公式中
v = b 1 ∗ v + ( 1 − b 1 ) ∗ ∇ w i w i = w i − l r ∗ ∇ w i v v = b1 * v + (1-b1) * \nabla w_i\\ w_i = w_i - lr* \frac{\nabla w_i}{\sqrt{v}} v=b1∗v+(1−b1)∗∇wiwi=wi−lr∗v∇wi
Adam
相比RMSProp,Adam做到了对两个优化方法更好的融合:
m = b 1 ∗ m + ( 1 − b 1 ) ∗ ∇ w v = b 2 ∗ v + ( 1 − b 2 ) ∗ ∇ w 2 w = w − l r ∗ m / v m = b1 * m + (1-b1)*\nabla w\\ v = b2 * v + (1-b2) * \nabla w ^2\\ w = w - lr* m/\sqrt{v} m=b1∗m+(1−b1)∗∇wv=b2∗v+(1−b2)∗∇w2w=w−lr∗m/v
import torch
from torch import optim
from torch.utils import data
import torch.nn as nn
import matplotlib.pyplot as plt
# Hyper Params
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1 * torch.normal(torch.zeros(x.size()))
# plot dataset
# plt.scatter(x.numpy(), y.numpy())
# plt.show()
torch_dataset = data.TensorDataset(x, y)
loader = data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
# default network
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = nn.Linear(1, 20)
self.predict = nn.Linear(20, 1)
def forward(self, x):
x = nn.functional.relu(self.hidden(x))
x = self.predict(x)
return x
# make 4 different nets
net_SGD = Net()
net_Momentum = Net()
net_RMSProp = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSProp, net_Adam]
# using different optimizer
opt_SGD = optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSProp = optim.RMSprop(net_RMSProp.parameters(), lr=LR, alpha=0.9)
opt_Adam = optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSProp, opt_Adam]
# loss function
loss_func = nn.MSELoss()
loss_his = [[], [], [], []] # record loss
for epoch in range(EPOCH):
print("epoch:", epoch)
for step, (batch_x, batch_y) in enumerate(loader):
# TODO:transform x,y
x_train = batch_x
y_train = batch_y
for net, opt, l_his in zip(nets, optimizers, loss_his):
y_predict = net(x_train)
loss = loss_func(y_predict, y_train)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data.item())
label = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(loss_his):
plt.plot(l_his, label=label[i])
plt.legend(loc='best')
plt.xlabel("Step")
plt.ylabel("Loss")
plt.ylim((0, 0.2))
plt.savefig("OptimizerCompare")
plt.show()
结果:
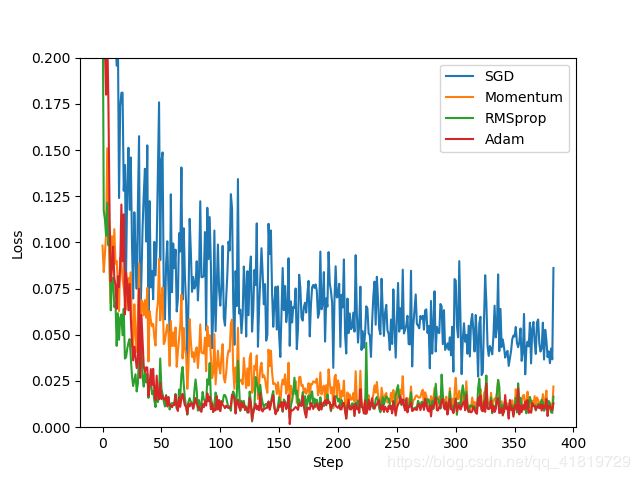
参考致谢
莫烦python:https://morvanzhou.github.io/tutorials/machine-learning/torch/3-04-save-reload/
github:https://github.com/yunjey/pytorch-tutorial
pytorch doc:https://pytorch.org/docs/stable/torch.html?highlight=unsqueeze#torch.unsqueeze