Spark-Core应用详解之高级篇
文章目录
- 三、RDD高级应用
- 1.RDD的分片数量
- 2.RDD的函数传递问题
- <1>如果RDD的转换操作中使用到了class中的方法或者变量,那么该class需要支持实例化。
- <2>如果通过局部变量的方式将class中的变量赋值为局部变量,那么就不需要传递对象。
- 3.RDD的运行方式
- (1)RDD的依赖关系
- (2)DAG 有向无环图
- (3)RDD的任务划分
- Stage
- 4.RDD的持久化
- 5.RDD的checkpoint机制
- 6.键值对RDD数据分区
- 7.RDD的累加器和广播变量
- (1)RDD 的累加器
- 自定义累加器
- (2)广播变量
三、RDD高级应用
1.RDD的分片数量
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
numSlices: 分片数,一个分片就是一个任务,所以defaultParallelisms是分片数也是相当于并行度。
2.RDD的函数传递问题
传递RDD函数的时候,要继承java的Serializable接口,也就是序列化。
序列化:将对象的状态信息转换为可以存储或传输的形式的过程。因为我们声明一个对象的时候是以字节码,字节数组的形式呈现给jvm实现跨平台操作。
而产生序列化的原因是因为需要分布式读取,在两台节点相互合作的时候,就需要把命令转换成为二进制码,令另一台机器的jvm接收转换为可以使用的对象,这也就是反序列化。
所以在我们打成jar包的时候就会产生序列化问题,当我们在spark上运行jar的时候,需要把它传给很多worker,也就是我们要运用Serializable的原因。
而这个过程也就叫做RDD的传递操作。
import org.apache.spark.rdd
class SearchFunctions(val query: String) extends java.io.Serializable{
def isMatch(s: String): Boolean = {
s.contains(query) }
def getMatchesFunctionReference(rdd: org.apache.spark.rdd.RDD[String]): org.apache.spark.rdd.RDD[String] = {
// 问题:"isMatch"表示"this.isMatch",因此我们要传递整个"this"
rdd.filter(isMatch)
}
def getMatchesFieldReference(rdd: org.apache.spark.rdd.RDD[String]): org.apache.spark.rdd.RDD[String] = {
// 问题:"query"表示"this.query",因此我们要传递整个"this"
rdd.filter(x => x.contains(query))
}
def getMatchesNoReference(rdd: org.apache.spark.rdd.RDD[String]): org.apache.spark.rdd.RDD[String] = {
// 安全:只把我们需要的字段拿出来放入局部变量中
val query_ = this.query
rdd.filter(x => x.contains(query_))
}
}
解析一下这个SearchFunction类,首先传入一个String类型的s,去匹配是否含有query,返回一个boolean值。
getMatchesFunctionReference方法主要用来过滤传入进来的rdd,因为他在filter内写进了isMatch方法做过滤的详细指标。而isMatch又可以表示为this.isMatch,因为rdd.filter这个操作是要分布式运行到很多机器上去,所以这也就是我们要是用序列化操作的原因。
getMatchesFieldReference方法的query也可以表示为this.query,像上所述的一样,也是要分布式运行到很多台机器上去。
但是有一个方法,可以不采用序列化操作,那就是产生一个新的参数被this.所赋值,就可以不用序列化了。
小结:
<1>如果RDD的转换操作中使用到了class中的方法或者变量,那么该class需要支持实例化。
<2>如果通过局部变量的方式将class中的变量赋值为局部变量,那么就不需要传递对象。
3.RDD的运行方式
(1)RDD的依赖关系
窄依赖:父类的RDD的Partition最多被子RDD的一个Partition使用。

宽依赖:指的是多个子RDD的Partition会依赖同一个父RDD的Partition会引起shuffle。
只要是xxbyKey基本都是存在shuffle过程的,因为存在混洗。

(2)DAG 有向无环图
当进程互相矛盾,资源调度出现先后顺序问题的时候,需要使用oozie进行资源调度。

(3)RDD的任务划分
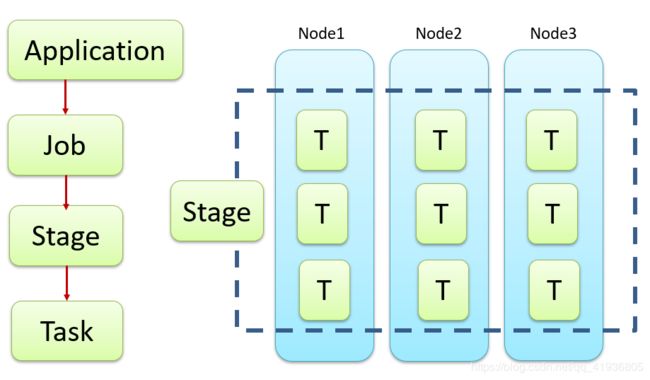
Application:一个运行的jar就是一个应用。
Job:一个Action操作就是一个Job,也就是Hadoop的MR
Stage:按照看窄依赖划分,下面会详讲。
Task:一个进程就是一个Task。
Stage

以wordCount核心算法为例:
val file = sc.textFile("hdfs://Master:8020/person.txt")
val words = file.flatMap(_.split(" "))
val word2count = words.map((_,1))
val result = word2count.reduceByKey(_+_)
result.saveAsTextFile("path")
运行的时候是从上往下运行的,但是划分stage的时候,是从下往上去划分,如图
因为最后的saveAsTextFile是一个Action操作,所以被划分在最外面,也就是蓝色的背景部分。
往上倒,之后是reduceByKey,也就是一个宽依赖,混洗操作,所以划分在Stage2。
在往上看,上面的textFile,flatMap,map操作都是一个窄依赖,所以可以被共同划分在Stage1。
Stage的结构就像栈结构一样,先进后出,stage2先被压入栈底,然后再压stage1。
4.RDD的持久化
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
// This means the user previously called localCheckpoint(), which should have already
// marked this RDD for persisting. Here we should override the old storage level with
// one that is explicitly requested by the user (after adapting it to use disk).
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
}
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
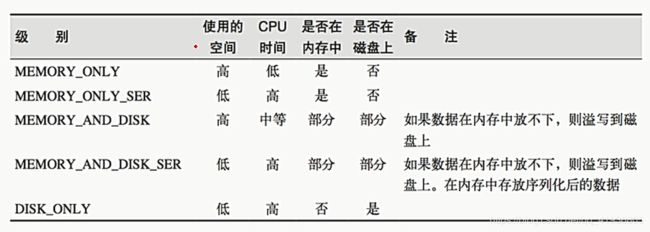
RDD的持久化也就是RDD的缓存操作,其中,RDD有两个缓存算子,一个是cache,一个是persist,这两个的关系就像makeRDD和 parallelize一样,可以直接调用cache,这样默认的persist参数为void,直接将StorageLevel的存储级别设置为内存存储(最好的一种存储),而调用persist,填了参数的话,如图介绍:
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
2的意思也就是存储两份的意思
scala> val rdd = sc.makeRDD(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at :24
scala> val nocache = rdd.map(_.toString+"["+System.currentTimeMillis+"]")
nocache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at map at :26
scala> val cache = rdd.map(_.toString+"["+System.currentTimeMillis+"]")
cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at map at :26
scala> cache.cache
res1: cache.type = MapPartitionsRDD[2] at map at :26
scala> nocache.collect
res2: Array[String] = Array(1[1546694698266], 2[1546694698266], 3[1546694698266], 4[1546694698266], 5[1546694698266], 6[1546694698273], 7[1546694698273], 8[1546694698273], 9[1546694698273], 10[1546694698273])
scala> nocache.collect
res3: Array[String] = Array(1[1546694699746], 2[1546694699746], 3[1546694699746], 4[1546694699746], 5[1546694699746], 6[1546694699747], 7[1546694699747], 8[1546694699747], 9[1546694699747], 10[1546694699747])
scala> cache.collect
res4: Array[String] = Array(1[1546694705677], 2[1546694705677], 3[1546694705677], 4[1546694705677], 5[1546694705678], 6[1546694705678], 7[1546694705678], 8[1546694705678], 9[1546694705679], 10[1546694705679])
scala> cache.collect
res5: Array[String] = Array(1[1546694705677], 2[1546694705677], 3[1546694705677], 4[1546694705677], 5[1546694705678], 6[1546694705678], 7[1546694705678], 8[1546694705678], 9[1546694705679], 10[1546694705679])
从程序中,我们可以看出,使用了cache算子进行缓存的,时间不会改变,因为collect输出的是缓存的时间,是不经过计算的,而没有经过cache进行缓存的,所collect的时间是随时都会变化的。
5.RDD的checkpoint机制
checkpoint和cache都是给RDD做缓存作用的,但是他们还是有着显著区别的,最明显的区别就是cache把缓存写在了memory中,而checkpoint写在了hdfs中。
我个人感觉,如果要是小项目的话,还可以,但是要是大项目的话,会导致内存超载,如果使用cache进行缓存,当某个节点的executor宕机,RDD就会丢失,数据也会没,而这时候,cache一种自带的容错机制,也就是依赖链就会起作用,重新把内存还原继续计算,这倒是也可以,但是很浪费资源,浪费内存,相反,checkpoint一开始就把缓存写在了hdfs中,也就没有依赖链一说,保证了高容错性。
scala> sc.setCheckpointDir("hdfs://linux01:8020/checkpoint")
scala> val ch1=sc.parallelize(1 to 2)
ch1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at :24
scala> val ch2 = ch1.map(_.toString+"["+System.currentTimeMillis+"]")
ch2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at map at :26
scala> val ch3 = ch1.map(_.toString+"["+System.currentTimeMillis+"]")
ch3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at map at :26
scala> ch3.checkpoint
scala> ch2.collect
res10: Array[String] = Array(1[1546695226909], 2[1546695226909])
scala> ch2.collect
res11: Array[String] = Array(1[1546695231735], 2[1546695231736])
scala> ch3.collect
res12: Array[String] = Array(1[1546695237730], 2[1546695237728])
scala> ch3.collect
res13: Array[String] = Array(1[1546695237805], 2[1546695237800])
scala> ch3.collect
res14: Array[String] = Array(1[1546695237805], 2[1546695237800])
scala> ch3.collect
res15: Array[String] = Array(1[1546695237805], 2[1546695237800])
scala>

被checkpoint的RDD第一次collect的时候我们发现时间还是变了,但是第二次就开始执行缓存机制了,因为他内部有一个触发器,并且根据hdfs的存储目录可知,最后缓存的数据的确被存入了hdfs中。
6.键值对RDD数据分区
Spark目前可以使用HashPartition和RangePartition进行分区,用户也可以自定义分区方法,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中的每条数据经过shuffle过程属于哪个分区和Reduce的个数。
但是在这里,HashPartition有一个弊端,就是会导致数据倾斜,因为Hash的本质是除留取余法进行存储,所以就会产生这种偶然性,导致大量偶然的数据进来之后会让其中一个线程被挤爆,而其他线程占用的很少。
所以,我们更倾向使用RangePartition,这种分区方法采用了水塘抽样随机算法进行数据的存储,可以让数据平均的存储到每一个分区中。
注意:
1.只有K-V类型的RDD才有分区,非K-V类型的RDD分区的值就是None
2.每个RDD 分区ID范围:0~numPartitions-1,决定这个值是属于哪个分区的。
3.当我们自己想制造一个分区方法的时候,只需要继承Partitioner这个抽象类就可以了
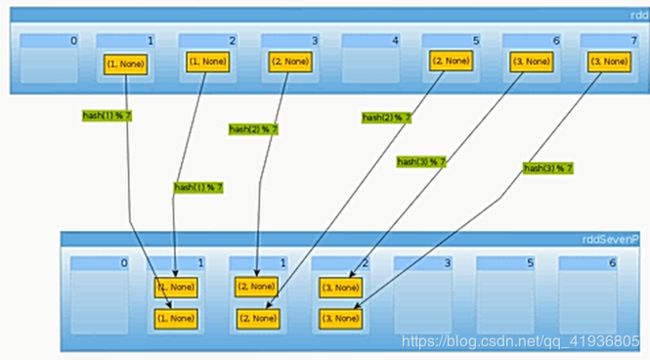
具体代码:
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
class CustomerPartitioner(numPartition:Int) extends Partitioner{
// 返回分区的总数
override def numPartitions: Int = {
numPartition
}
// 根据传入的key返回分区的索引
override def getPartition(key: Any): Int = {
key.toString.toInt % numPartition
}
}
object CustomerPartitioner{
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setAppName("Partition").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(0 to 10,1).zipWithIndex()//把下标拉到一起
print(rdd.mapPartitionsWithIndex((index,items)=>Iterator(index+":"+items.mkString(","))).collect())
val rdd2 = rdd.partitionBy(new CustomerPartitioner(5))
print(rdd2.mapPartitionsWithIndex((index,items)=>Iterator(index+":"+items.mkString(","))).collect())
sc.stop()
}
}
7.RDD的累加器和广播变量
(1)RDD 的累加器
Spark内部提供了一个累加器,但是只能用于求和
使用方法:
scala> val blank = sc.textFile("./NOTICE")
notice: org.apache.spark.rdd.RDD[String] = ./NOTICE MapPartitionsRDD[40] at textFile at :32
scala> val blanklines = sc.accumulator(0)
warning: there were two deprecation warnings; re-run with -deprecation for details
blanklines: org.apache.spark.Accumulator[Int] = 0
scala> val tmp = blank.flatMap(line => {
| if (line == "") {
| blanklines += 1
| }
| line.split(" ")
| })
tmp: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[41] at flatMap at :36
scala> tmp.count()
res1: Long = 3213
scala> blanklines.value
res2: Int = 171
累加器也是懒执行,所以需要Action操作触发出来
自定义累加器
代码:
package Mapreduce
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
class CustomerAcc extends AccumulatorV2[String,mutable.HashMap[String,Int]] {
private val _hash = new mutable.HashMap[String,Int]()
// 检测是否为空
override def isZero: Boolean = {
_hash.isEmpty
}
// 拷贝一个新的累加器
override def copy(): AccumulatorV2[String,mutable.HashMap[String,Int]] = {
val copyHash = new CustomerAcc()
// 创造一个copy的累加器,然后用synchronized方法设置同步操作
_hash.synchronized{
copyHash._hash++=_hash
}
copyHash
}
// 重置累加器
override def reset(): Unit = {
_hash.clear()
}
// 每一个分区中用于添加数据的方法 小Sum
override def add(v: String) ={
_hash.get(v) match {
case None=>_hash+=((v,1))
case Some(x)=>_hash+=((v,x+1))
}
}
// 合并每一个分区的输出 总Sum
override def merge(other: AccumulatorV2[String,mutable.HashMap[String,Int]]) = {
other match{
case o:AccumulatorV2[String,mutable.HashMap[String,Int]]=>{
for ((k,v)<- o.value){
_hash.get(k) match {
case None=>_hash+=((k,v))
case Some(x)=>_hash+=((k,v+x))
}
}
}
}
}
// 输出值
override def value(): mutable.HashMap[String,Int] = {
_hash
}
}
object CustomerAcc {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("Partition1").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val hash = new CustomerAcc()
sc.register(hash)
val rdd = sc.makeRDD(Array("a","b","c","a","b","c","d"))
rdd.foreach(hash.add(_))
for((k,v)<-hash.value){
println("["+k+":"+v+"]")
}
sc.stop()
}
}
总结:
1.创建一个累加器的实例
2.通过sc.register()注册一个累加器
3.通过累加器实例名.add添加数据
4.通过累加器实例名.value来获取累加器的值
注:1.不要在转换中访问累加器,要在行动中访问。
2.转换或者行动中不能访问累加器的值,只能.add
(2)广播变量
1.当在定义的方法中定义了一个本地变量,想要和RDD中变量结合发送给其他节点,那么这个本地变量会在每一个分区中产生一个拷贝
2.但是在使用了广播变量的情况下,每一个Executor中会有该变量的次copy,[大大节约在分区中占有的缓存]
使用方法
scala> val broadcaster = sc.broadcast(Array(1,2,3))
broadcaster: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(2)
scala> broadcaster.value
res2: Array[Int] = Array(1, 2, 3)
适用于高效分发较大的数据对象。