生成树原来这么简单
文章目录
- 前言摘要
- 什么是生成树?
- 生成树的作用?
- 一、STP
- 1.1 背景
- 1.2 STP增强特性
- 1.2.1 portfast 端口加速
- 1.2.2 backbonefast 骨干加速
- 1.2.3 uplinkfast 上行链路加速
- 1.2.4 BPDU guard BPDU 防护
- 1.2.5 BPDU filter BPDU 过滤
- 1.3 BPDU
- 1.3.1 重要字段详解(BID、RID、COP、PID)
- 1.3.2 生成时的计时器
- 1.4 工作原理
- 1.4.1 端口角色
- 1.4.2 端口状态
- 1.4.3 选举过程
- 1.4.4 角色与状态的结合
- 1.5 生成树拓扑结构变化
- 1.6 STP控制
- 1.6.1 修改BID、COP、PID
- 1.6.2 修改时间
- 二、RSTP
- 2.1 产生
- 2.2 BPDU
- 2.3 工作原理
- 2.3.1 端口角色
- 2.3.2 端口状态
- 2.3.3 PA机制--选举过程
- 2.4 定义链路类型
- 2.5 802.1W的重收敛
- 2.6 特点
- 三、MSTP
- 3.1 产生
- 3.2 BPDU字段详解
- 3.3 部署
- 3.3.1 说明
- 3.3.2 注意
- 3.3 兼容性
- 3.4 优点
- 四、总结所有生成树
- 问题:
- 1、RSTP与MSTP的BPDU帧格式中比STP多了什么?
- 2、BID与RID的区别?
- 3、简述 STP(802.1D)的作用及工作原理. RSTP(802.1W)收敛速度为什么比 802.1D 快?有哪些方面?
- 4、 MSTP 原理?
前言摘要
什么是生成树?
说起生成树你可能会有如下印象
1、解决二层环路
2、防止广播风暴
广播风暴造成的结果是什么?
广播报文在两个或多个交换机间大量的、重复的、无休止的传递
造成广播风暴的原因是什么?
洪范
冗余链路
3、防止MAC地址表的不稳定
4、防止数据帧的重复拷贝
如何做到以上四点呢?
即逻辑性的阻塞某个接口
我们都知道树形结构是一种无环的拓扑,在动态路由协议OSPF中使用的SPF算法也是一种树形无环的拓扑算法,那么生成树协议到底是如何阻塞接口进而解决二层环路的,这就要从以下几个维度去分析和考究了;在考究之前,首先要明确以下其工作的位置,生成树协议出生在二层,即OSI模型的数据链路层,TCP/IP协议的网络接口层(TCP/IP将物理层与数据链路层合并为网络接口层),二层的典型设备交换机,即生成树协议就是在交换机上运行的;此时再来明确一下上面提到的几个维度,分别为如下
1、端口角色
2、端口状态
3、选举过程
下面我就从这几个维度来对生成树协议进行详解分析
且慢,详解分析之前,首先对生成树进行一个大致的分类,即工业标准与Cisco私有;下图提到的基于VLAN的树,看不懂没关系,详解中会有清晰的解释
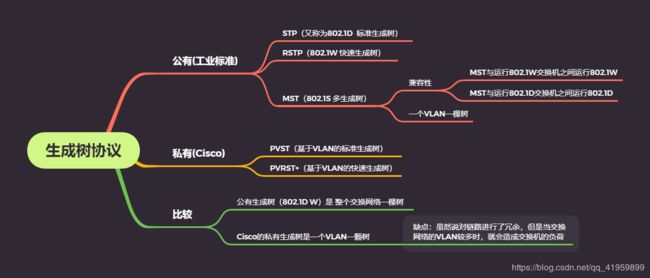
生成树的作用?
交换机之间存在冗余(备份)路径,以及交换机的泛洪机制,导致交换机之间产生二层交换环路。
造成影响:
1.广播风暴
2.MAC地址表不稳定
3.数据帧的重复拷贝
解决方案:逻辑性阻塞某个接口. 使用STP来逻辑的阻塞某一个接口,使其只接收流量,不发送流量从而防止环路。
下面就是以工业公有的生成树协议为准进行详解生成树协议
一、STP
1.1 背景
又叫做802.1D,这是生成树最开始的形态,现在基本上不使用,原因主要有以下几点
1、基于计时器收敛,速度慢(最长50s)
2、不能进行负载分担
但是也有解决方法,即STP的增强特性
1.2 STP增强特性
1.2.1 portfast 端口加速
针对交换机的access接口,连接的是终端用户例如router、PC、server (非网桥,交换机)等等,这些不需要运行生成树的接口。
默认进入listening状态,等待30s进入转发状态.
部署位置:
在接口上:部署在连接终端的access接口上,若部署在trunk上,则失效
在全局上:spanning-tree protfast default
建议部署在所有接入层的接入设备的接口上
1.2.2 backbonefast 骨干加速
若骨干链路发生故障,下行链路经过50s进入forwarding状态;
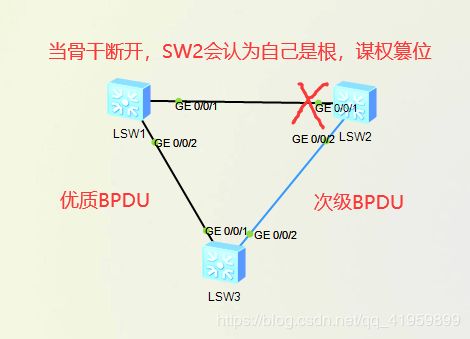
为什么是50s?
注意:若骨干链路发生断裂,即SW1与SW2之间的链路出现故障,SW2此时由于不能收到根网桥发来的BPDU,则SW2就认为自己就是根,他就会向SW3发送BPDU(RID与BID都是SW2),此时,对于SW3而言,虽然与SW2连接的链路是阻塞状态,但是还是会一直收到BPDU,SW3一看通过SW1发来的RID比SW2发来的RID更优,则认为SW2发来的是次级BPDU,SW1发来的是优质的BPDU;SW3会一直忽略,虽然是阻塞接口收到的,但是其有义务检测BPDU是否优质,当过去20s后,SW3还是收到SW2发来的次级BPDU,就会进入listening状态,此时向SW2发送一个BPDU,告诉SW2还有一个RID比你优,之后会经过第一个15s进行重新的选举,经过第二个15s进行MAC地址表学习;即需要50s
部署:
启用backbonefast特性,若收到次级BPDU,通过根端口向根网桥发送RIQ查询(询问优质根是否正常),若正常由根网桥返回RIQ应答,描述根正常,则blocking接口进入listening状态,经过30s进入forwarding.
SW2向SW3发送次级BPDU,通过自己的根端口向根网桥发送RLQ(根链路查询),根网桥对SW3进行根恢复,告诉它优质根的存在(自己的存在),此时SW3的NDP(非指定端口)变Listening状态,并告诉SW2优质根的存在;SW3与SW2重新进行生成树选举,SW2的指定端口变成RP(根端口),SW3的阻塞端口变成DP(指定端口)
建议部署在所有的交换机上
1.2.3 uplinkfast 上行链路加速
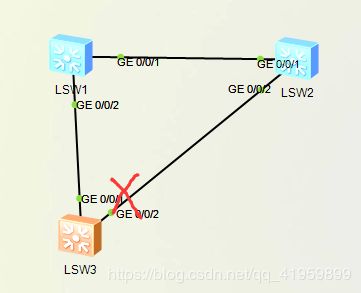
若上行链路发送故障,阻塞端口进入listening 状态;
因为已经收不到来自根的BPDU,没有20s的blocking到listening,默认等待30s进forwarding
如下图,若SW3的G0/0/1down掉,即根端口出现故障,那么G0/0/2这个原本是阻塞的端口要切换成根端口需要30s
部署位置:所有的接入层交换机上(有大量阻塞端口上实施);
部署完成后,有如下的变化,目的是为了离根远一点,即接入层的交换机
交换机的BID优先级会变成32768+4*4096;
Cost增加3000,
uplinkfast enabled

1.2.4 BPDU guard BPDU 防护
目的:为了不让接入层的交换机收到BPDU报文
启用位置: 接入层交换机的portfast接口.
可以全局启用或接口启用(若全局启用,则本交换机上所有启用了portfast接口启用BPDU防护)
接口收到了BPDU之后:处理动作为shutdown(err-disable—BPDUguard)
1.2.5 BPDU filter BPDU 过滤
目的:使接口既不能发送也不能接收任何的BPDU信息,即portfast接口
部署位置: portfast接口
可以全局或接口启用(全局启用仅限于portfast接口)
启用了BPDU filter 接口既不能发送也不能接收任何的BPDU信息,若收到BPDU报文,则直接忽略.
6、root guard 根防护
部署位置: 在可能连接新交换机的接口上实施.
过程:若收到了更优质根ID BPDU报文,则直接丢弃该报文,并将该接口置为boken(root 不一致导致),接口转发行为为blocking,持续30s,若30s之后依然收到,则根被抢占.
若不再收到优质root id 的BPDU ,接口自动恢复
注意: root guard 不能用于需要启用uplinkfast成为root port 的端口上.
7、loop guard 环路防护(以太网)
8、UDLD 单向链路检测(光纤网)
1.3 BPDU
首先介绍以下BPDU,即网桥协议数据单元,这在生成树协议中及其重要,每个交换机通过收发BPDU信息来进行选举于端口状态的确定;BPDU的字段介绍如下图,下面将进行详细的字段介绍


Protocol Identifier:协议 ID=“0”
Protocol Version Identifier:协议版本标识符,STP 为 0,RSTP 为 2,MSTP 为 3
BPDU Type :BPDU 类型
0x00:STP 的 Configuration BPDU
描绘本交换机的基本情况(设备情况、接口情况、接口状态情况)
0x80:STP 的 TCN BPDU(Topology Change Notification BPDU)
当生成树选举完成后,某些接口down后,拓扑结构发生变化后,交换机发送的TCN-BPDU
0x02:RST BPDU(Rapid Spanning-Tree BPDU)或者 MST BPDU(Multiple Spanning-Tree BPDU)
Flags:对于“标记域”(Flags),8bits 注意:在802.1D中只用到了两位;而在802.1W S中会用到其他的位
第一个 bit(左边、高位 bit)表示“TCA(拓扑变更确认)”
最后一个 bit(右边、低位 bit)表示“TC(拓扑变更)”
Root Identifier: 网桥 ID 都是 8 个字节——前两个字节是网桥优先级,后 6 个字节是网桥 MAC 地址
Root Path Cost: 根路径开销,本端口累计到根桥的开销
Bridge Identifier:发送者 BID,本交换机的 BID
Port Identifier:发送端口 PID,发送该 BPDU 的端口 ID
Message Age:该 BPDU 的消息年龄
Max Age :消息老化年龄
Hello Time :发送两个相邻 BPDU 间的时间间隔
Forward Delay :控制 Listening 和 Learning 状态的持续时间。
下面将对几个重要的字段进行详解
1.3.1 重要字段详解(BID、RID、COP、PID)
BID:网桥标识符,用于表示该交换机或网桥在该生成树中的唯一性
构成:BID优先级 + mac地址
注意:
PVST、PVRSTP+,构成是BID优先级+VLAN ID(扩展系统ID sys-id-ext)+mac地址
MST,构成是BID优先级+ instance ID + mac地址
BID优先级:默认值为32768,数值范围0-65535(BID优先级数值必须为4096的倍数,范围也可称为0-61440),小优
Mac 地址:本交换机上背板地址池中最小的MAC地址,小优
交换机本身是没有MAC地址的,这些背板池的MAC地址是给SVI、三层接口用的
RID:根标识符 ,在一棵生成树中表示唯一根,使用最优质的BID表示
BID是干什么的?
用于选举根网桥的,拥有最优BID的交换机为根网桥;其实每个交换机先把自己的BID放到RID里,即都将自己作为根;大家都说比较的是RID,其实呢,比较的是RID里的BID,选举RID小的作为根网桥
COP:Cost of Path,路径开销,描述了本接口到达根的路径开销值,小优;默认根网桥上所有接口的COP值为0,经过不同的链路增加对应的cost
10G万兆-----2
1G千兆--------4
100M百兆-----19
10M十兆-----100
注意:COP的计算是这样的,一个BPDU从根出发是0,每经过一段链路会进行加和,如下进行举例,对于SW2的G0/0/2口而言,其只能从SW3上收到BPDU,即COP就是19+19

PID:端口标识符,用于表示本交换机上接口的唯一性标识
构成: PID优先级+port number
PID优先级:默认为128,数值范围0-255(PID优先级必须为16的倍数,所有范围0-240),小优
Port number:端口号,表示了本交换机该接口的唯一性,一般为接口的端口号标识,小优
1.3.2 生成时的计时器
Hello 时间: 默认2s,配置BPDU的发送间隔,选举完成后,只有根网桥发送BPDU,其他人只是转发BPDU
Max age :最大等待时间,默认20s,hello数据包的超时时间以及从blocking进入listening 状态等待时间
Message age :消息时间,也称消息的老化时间,实际上等于MAC地址老化时间,默认300s,在启portfast等特性时变为15s
Forward delay :转发延时,默认15s ,在生成树中状态切换间隔
Listening进入learning进入forwarding 时间隔
1.4 工作原理
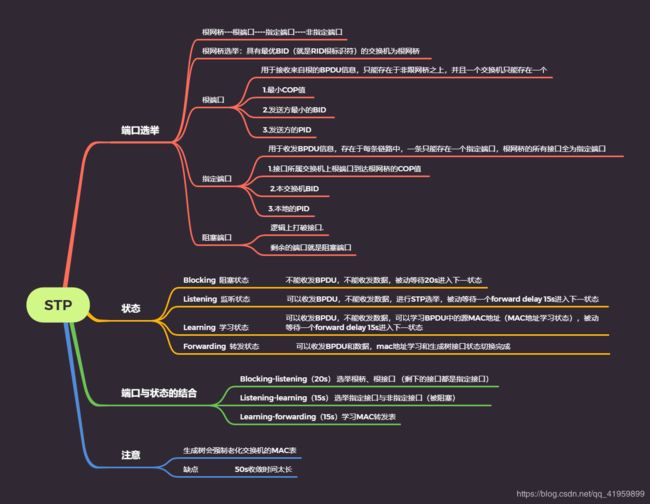
1.4.1 端口角色
STP的端口角色分为三个,如下所示
根端口:用于接收来自根的BPDU信息,只能存在于非跟网桥之上,并且一个交换机只能存在一个
指定端口:用于发送或转发BPDU信息,存在于每条链路中,一条只能存在一个指定端口,根网桥的所有接口全为指定端口
非指定端口(阻塞端口):逻辑上打破环路,即阻塞接口
1.4.2 端口状态
STP的端口状态有四个,如下所示
Blocking:不能收发BPDU,不能收发数据,被动等待20s(最大等待时间)进入下一状态
Listening:可以收发BPDU,不能收发数据,进行STP选举,被动等待一个forward delay 15s(转发延时)进入下一状态
Learning:可以收发BPDU,不能收发数据,可以学习BPDU中的源MAC地址(MAC地址学习状态),被动等待一个forward delay 15s进入下一状态
Forwarding:可以收发BPDU和数据,mac地址学习和生成树接口状态切换完成
Blocking、Forwarding状态是最终的状态;而Listening、Learning是中间态;开始时大家都是Blocking状态
1.4.3 选举过程
选举过程为:根网桥–>根端口–>指定端口–>非指定端口
根网桥选举:上面介绍BPDU中已经提到了,即每个交换机首先将自己作为根网桥,将自己的BID放到RID里,将自己所有的端口作为指定端口,向其他交换机发送给BPDU,这时拥有最小的BID者成为真正的根网桥
总结:拥有最小的BID者为根网桥
根端口选举:首先根端口是用于接收来自根网桥上的指定端口发送的BPDU信息的,这说明了根端口只能存在于非根网桥之上,且一个交换机只能存在一个根端口
1、COP—到根网桥最小的cost
2、BID—发送方最小的BID(谁给我的BPDU)
注意:非根网桥在转发BPDU时,会将自己的BID放到BPDU中,即RID是根的BID,BID是自己的BID
3、PID—发送方最小的PID、若还是不能比较(其实还有优先级可以比较),则选本地最小的PID
举例说明:
1、SW3上选举根端口,COP小则优

2、SW4上选举根端口,发送方BID小则优

3、SW2上选举根端口,发送方的PID小则优

4、SW2上选举根端口,本地的PID小则优

指定端口选举:用来转发或发送BPDU的;首先,根网桥的所有端口都是指定端口,一条链路中有且仅有一个指定端口,对于非根网桥的指定端口的选举如下
1、本交换机所在的根端口的COP,小优
2、BID—本地交换机的BID小者为指定端口,小优
2、PID–本地交换机的OID小者为指定端口,小优
举例说明:
1、SW4与SW5连接的链路进行指定端口的选举,首先比较本交换机上的根端口的COP,小优
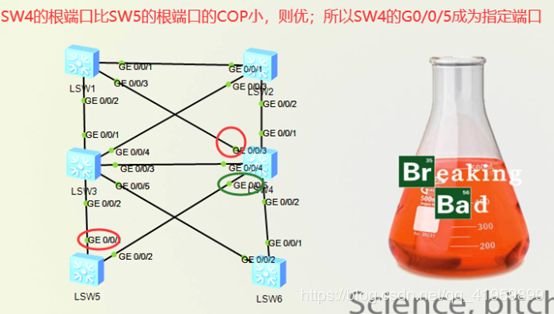
2、SW2与SW3的链路进行指定端口的选举,COP相同,则比较BID,小优
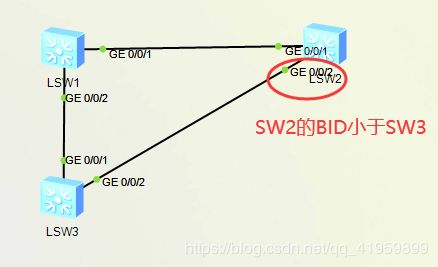
3、SW2上选举指定端口,由于是一个设备所以COP、BID相同,只能比较PID;G0/0/2的PID小于G0/0/3,则其为指定端口

非指定端口的选举:根端口与指定端口选举完成后,剩下的就是非指定端口,即阻塞端口
1.4.4 角色与状态的结合
Blocking-listening(20s) 选举根桥、根端口 (剩下的接口都是指定接口)
Listening-learning(15s) 选举指定接口与非指定接口(被阻塞)
BPDU从出到回的时间为15s,所以选举端口的时间为15s;这就是Forward delay :转发延时,默认15s ,在生成树中状态切换间隔Learning-forwarding(15s)学习MAC转发表
1.5 生成树拓扑结构变化
生成树选举完成后,新增或删除链路时,称为拓扑结构发生了变化;此时由本交换机上的根端口向根网桥发送TC-BPDU(拓扑变更BPDU);当根网桥收到此BPDU后,开始重新进行收敛,收敛完成后,根网桥向发送TC-BPDU的交换机发送一个TCA-BPDU(拓扑变更确认BPDU)
1.6 STP控制
1.6.1 修改BID、COP、PID
Cisco是基于VLAN进行修改的
修改根网桥,即修改BID,BID由BID优先级+MAC地址

若设置主根的话,优先级就是32769-4096*2;备根就是32768-4096
修改根端口,修改COP、PID(真机上是16的倍数,模拟器上是64的倍数)

1.6.2 修改时间
在讲述下一个生成树的协议之前,要明确其为什么出现,显而易见,因为STP存在诸多的缺点,随便拉出来一个很难让人接受
1、基于计时器收敛,速度太慢
最慢得50s,即从阻塞状态开始算起;最快30s,即接口不需要进行BPDU的接收,如portfast接口2、不能进行负载分担
我们都知道负载是网络当中及其重要的组成部分,可以分流,可以降低设备的负荷等等,而STP并不存在傅瓒分担的特性
PVST
优点:简单、支持负载分担
缺点:收敛速度慢,生成树数量较多
二、RSTP
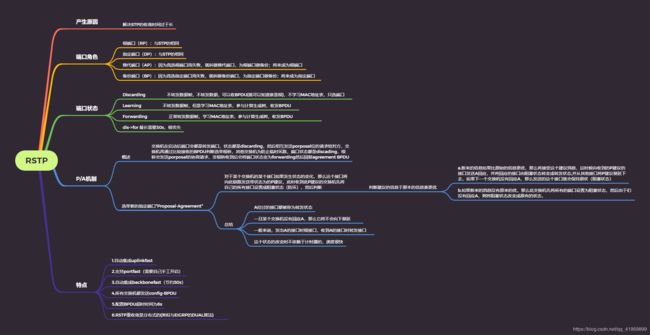
2.1 产生
解决STP的收敛时间过于长
如何解决STP的收敛时间?
概述:
1、STP中的Blocking-Listening其实就是为了选出根网桥而设定的,那么可以将这两个状态合并一下
2、Forward delay 15s的选举时间太慢,只能从这里动刀子,即增加一种预约机制,或者说备胎机制;将来出现故障后,直接上位顶替,就不存在选举了
详细:
1、discarding状态
2、增加两个端口角色;替代端口(AP)、备份端口(BP)
3、PA机制,即分布式收敛
2.2 BPDU
-
在 BPDU 的格式上,除了保证和 STP 格式基本一致之外,RSTP 作了一些小的变化。一个是在 Type 字段,配置 BPDU 类型不再是 0 而是 2;版本号也变成了 2。所以运行 STP 的交换机收到该类 BPDU 时会丢弃
-
另一个变化是在 Flag 字段,把原来保留的中间 6 位使用起来。这样改变了的配置 BPDU 叫做 RST BPDU
-
RSTP Flag 字段格式:
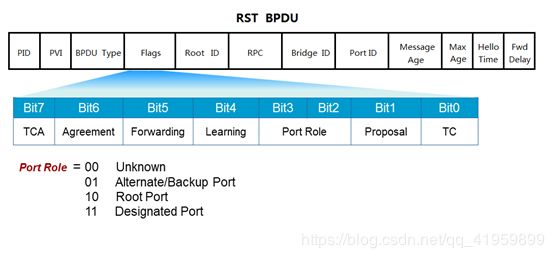
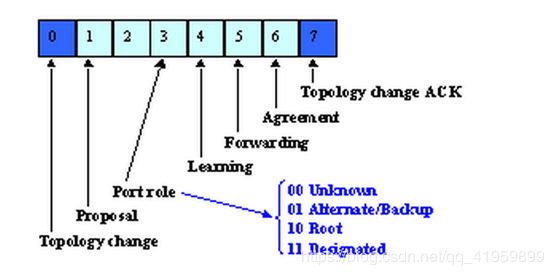
Bit7:TCA Topology Change Acknowledge 拓扑变更确认 Bit6:Agreement 同意 Bit5:Forwarding 转发状态 Bit4:Learning 学习状态 Bit3 和 Bit2:Port Role端口角色 00:Unknown 未知 01:Alternate/Backup 替代端口/备份端口 10:Root Port 根端口 11:指定端口 Bit1:Proposal 请求 Bit0:TC Topology Change 拓扑变更 1,6 用来生成树选举 2,3 描述端口角色 4,5 描述端口状态
抓包查看帧格式,比较STP与RSTP
STP

RSTP

2.3 工作原理
2.3.1 端口角色
根端口(RP):与STP的相同
指定端口(DP):与STP的相同
替代端口(AP):因为竞选根端口而失败,就叫做替代端口,为根端口做备份;将来成为根端口
备份端口(BP):因为竞选指定端口而失败,就叫做备份端口,为指定端口做备份;将来成为指定端口
注意:AP、BP替代的都是本交换机上的端口角色的
RSTP中定义的端口角色,但是这个功能十分的鸡肋
边缘端口:edge port ,非trunking,access接口, 对于这种不做生成树选举的端口直接进入forwarding状态;但是需要手工开启
非边缘端口:nonedge port ,trunking 接口
2.3.2 端口状态
Discarding :丢弃状态,不转发数据帧,不学习MAC地址表,能发BPDU,只选端口
Learning:学习状态,不转发数据帧,但是学习MAC地址表,参与计算生成树,收发BPDU
forwarding:转发状态,正常转发数据帧,学习MAC地址表,参与计算生成树,收发BPDU
注意:在802.1W中为了加快收敛,初始时所有的交换机都是discarding状态,即都可以发送BPDU
2.3.3 PA机制–选举过程
概述:
交换机在启动后端口会都是转发端口,状态都是discarding,然后相互发送带porposal位的请求给对方,交换机再通过比较接收的BPDU判断选举根桥,其他交换机为防止临时环路,端口状态都是discading,根桥会发送porposal的协商请求,非根桥收到后会将端口状态变为forwarding然后回复agreement BPDU
详细举例:
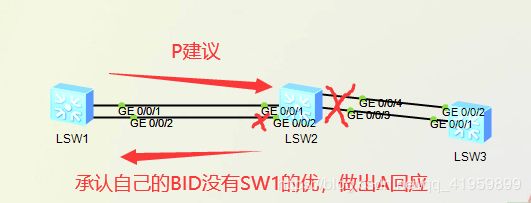
刚开始时,大家都将自己作为根向所有人发送RID是自己的BID的BPDU,SW1向SW2发送BPDU 并将自己的proposal位置为1,SW2收到此P位为1的BPDU后,将自己所有的接口阻塞,然后判断是否此RID优于自己,很明显是优于自己的,然后SW2向收到P建议的接口发送A回应,将回应的接口由阻塞状态变为转发状态。并从其他接口将P建议蔓延下去,如果下一个交换机没有回应A,那么发送的这个接口就会保持原状(阻塞状态);
2.4 定义链路类型
802.1W中定义了链路类型:在P2P中才可以启用RSTP,在shared中不支持RSTP,向下兼容为STP
P2P:点对点链路类型
Shared :共享性链路类型
什么时候链路类型为P2P、shared?
全双工链路上(G口、GE口、F口) 100M百兆、 1000M千兆、10G万兆
半双工链路上(E口以太网链路) 10M十兆
2.5 802.1W的重收敛
由于802.1W中每个交换机都有发送BPDU的能力,出现拓扑变化的交换机会自己发送TC-BPDU;
而802.1D则十分的慢,过程如下,由本交换机上的根端口向根网桥发送TC-BPDU(拓扑变更BPDU);当根网桥收到此BPDU后,开始重新进行收敛,收敛完成后,根网桥向发送TC-BPDU的交换机发送一个TCA-BPDU(拓扑变更确认BPDU)
2.6 特点
1.自动集成uplinkfast
2.支持portfast(需要自己手工开启)
3.自动集成backbonefast(节约50s)
4.所有交换机都发送config-BPDU
5.配置BPDU超时时间为6s
6.RSTP重收敛是分布式的(类似与EIGRP的DUAL算法)
三、MSTP
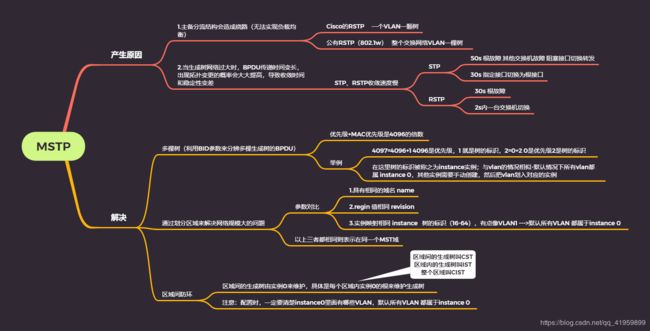
3.1 产生
MSTP 使用多生成树桥协议数据单元 MST BPDU(Multiple Spanning Tree Bridge Protocol Data Unit)作为生成树计算的依据。 MST-BPDU 报文用来计算生成树的拓扑、维护网络拓扑以及传达拓扑变化记录
解决了STP、RSTP的负载分担
如何解决?
采用多颗树来实现负载分担,引入一个概念,即实例;一个实例一棵树,可以将不同的VLAN划分到实例中,这样就能实现流量的负载分担、链路的冗余备份
3.2 BPDU字段详解
MSTP的BPDU帧格式

注意:
无论是域内的 MST BPDU 还是域间的,前 35 个字节和 RST BPDU 相同;从第 36 个字节开始是 MSTP 专有字段。最后的 MSTI 配置信息字段由若干 MSTI 配置信息组连缀而成
虽然在详解STP时已经对BPDU字段进行了解释,这里简单回顾一下,重要说明的是从36字节以后的MSTP专有字段
ProtocolIdentifier:协议标识符
Protocol Version Identifier:协议版本标识符,STP 为 0,RSTP 为 2,MSTP 为 3
BPDU Type :BPDU 类型,MSTP 为 0x02。
0x00:STP 的 Configuration BPDU 0x80:STP 的 TCN BPDU(Topology Change Notification BPDU)
0x02:RST BPDU(Rapid Spanning-Tree BPDU)或者 MST BPDU(Multiple Spanning-Tree BPDU)
CIST Flags :CIST 标志字段
CIST Root Identifier:CIST 的总根交换机 ID
CIST External Path Cost:CIST 外部路径开销指从本交换机所属的 MST 域到 CIST 根交换机的累计路径开销;CIST 外部路径开销根据链路带宽计算
CIST Regional Root Identifier:CIST 的域根交换机 ID,即 IST Master 的 ID。 如果总根在这个域内,那么域根交换机 ID 就是总根交换机 ID
CIST Port Identifier:本端口在 IST 中的指定端口 ID
Message Age BPDU :报文的生存期
Max Age :BPDU 报文的最大生存期,超时则认为到根交换机的链路故障
Hello Time :Hello 定时器,缺省为 2 秒
Forward Delay :转发延时,缺省为 15 秒36字节开始的MSTP专有字段
Version 1 Length :Version1 BPDU 的长度,值固定为 0
Version 3 Length :Version3 BPDU 的长度MST Configuration Identifier:MST 配置标识,表示 MST 域的标签信息,包含 4 个字段
Configuration Identifier Format Selector:固定为 0
Configuration Name:“域名”,32 字节长字符串
Revision Level:2 字节非负整数
Configuration Digest:利用 HMAC-MD5 算法将域中 VLAN 和实例的映射关系加密成 16 字节的摘要
注意:只有 MST Configuration Identifier 中的四个字段完全相同的,并且互联的交换机,才属于同一个域CIST Internal Root Path Cost :CIST 内部路径开销指从本端口到 IST Master 交换机的累计路径开销。CIST 内部路径开销根据链路带宽计算
CIST Bridge Identifier:CIST 的指定交换机 ID
CIST Remaining Hops:BPDU 报文在 CIST 中的剩余跳数MSTI Configuration Messages (may be absent):MSTI配置信息。每个MSTI的配置信息占16bytes,如果有n个MSTI就占用n×16bytes。单个MSTI Configuration Messages 的字段说明如下:
MSTI Flags:MSTI 标志
MSTI Regional Root Identifier:MSTI 域根交换机 ID
MSTI Internal Root Path Cost:MSTI 内部路径开销指从本端口到 MSTI 域根交换机的累计路径开销
MSTI 内部路径开销根据链路带宽计算
MSTI Bridge Priority:本交换机在 MSTI 中的指定交换机的优先级
MSTI Port Priority:本交换机在 MSTI 中的指定端口的优先级
MSTI Remaining Hops:BPDU 报文在 MSTI 中的剩余跳数


3.3 部署
MST 配置要求:
1.具有相同的域名 name
2.regin 值相同 revision
3.实例映射相同 instance 树的标识(16-64),有点像VLAN1 —>默认所有VLAN 都属于instance 0
3.3.1 说明
1、以上三者都相同则表示在同一个MST域
2、整个MST域的生成树由主根的实例0来维护,每个区域内由自己根的实例0的来维护生成树
3、区域间的生成树叫CST、区域内的生成树叫IST、整个区域叫CIST、不支持MSTP的设备,自己成为一个区叫做SST
4、Cisco与Huawei对接时需要修改cost计算的方式
如何分辨多颗生成树的BPDU?
通过BID参数;优先级+MAC优先级是4096的倍数
例如: 4097=4096+1 4096是优先级,1 就是树的标识,2=0+2 0是优先级2是树的标识。在这里树的标识被称之为instance实例。与vlan的情况相似-默认情况下所有vlan都属于instance 0,其他实例需要手动创建,然后把vlan划入对应的实例。
3.3.2 注意
1、要将实例0放到核心交换机上
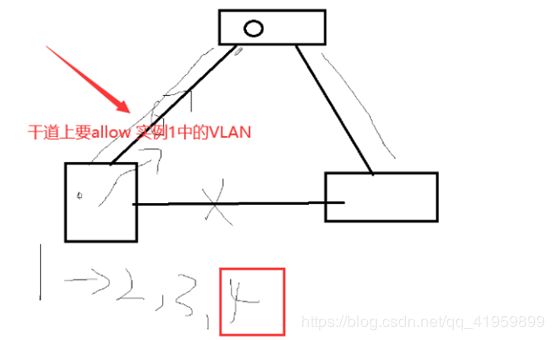
2、在Trunk干道上要allow实例1中的VLAN
3.3 兼容性
向下兼容:
在不同MST域之间使用802.1W 快速生成树
MST与运行802.1W交换机之间运行802.1W
MST与运行802.1D交换机之间运行802.1D
注意:在MST交换机工作在非MST上,默认使用MSTinstance 0 的BPDU与其他版本进行生成树的选举
3.4 优点
1、采用单树变为多树,减少了单台交换机的计算负荷
2、每一个实例只有实例0的根才能转发BPDU,即只有实例0的根才能参与整个大树的选举;可以将每个实例都当作是一个交换机,如下图,路逻辑上就变成了三个交换机

四、总结所有生成树
归结到底,就是生成树的缺点
1、线路利用率低
2、路径不能做到最优,只能做到相对优
3、不能再一颗树上做冗余
不适合大型数据中心的交换网络场景,因为数据中心存在大量的横向流量,即内部交互的流量;而传统企业基本上都符合二八定律
二八定律:80%的流量是要出去的,20%的流量是在内部的
问题:
1、RSTP与MSTP的BPDU帧格式中比STP多了什么?
STP的Flags字段的8bits只用到了两位,即最高位的“TCA(拓扑改变响应)”,最低位的“TC(拓扑改变)”;而RSTP的Flags中用到了中间的6位,如下图所示


详细说明其FLags字段
Bit7:TCA Topology Change Acknowledge 拓扑变更确认
Bit6:Agreement 同意
Bit5:Forwarding 转发状态
Bit4:Learning 学习状态
Bit3 和 Bit2:Port Role端口角色
00:Unknown 未知
01:Alternate/Backup 替代端口/备份端口
10:Root Port 根端口
11:指定端口
Bit1:Proposal 请求
Bit0:TC Topology Change 拓扑变更
1,6 用来生成树选举
2,3 描述端口角色
4,5 描述端口状态
2、BID与RID的区别?
BID:网桥标识符,用于表示该交换机或网桥在该生成树中的唯一性
构成:BID优先级 + mac地址
注意:
PVST、PVRSTP+,构成是BID优先级+VLAN ID+mac地址
MST,构成是BID优先级+ instance ID + mac地址
BID优先级:默认值为32768,数值范围0-65535(BID优先级数值必须为4096的倍数,范围也可称为0-61440),小优
Mac 地址:本交换机上背板地址池中最小的MAC地址,小优
RID:根标识符 ,在一棵生成树中表示唯一根,使用最优质的BID表示
BID是干什么的?
用于选举根网桥的,拥有最优BID的交换机为根网桥;其实每个交换机先把自己的BID放到RID里,即都将自己作为根;大家都说比较的是RID,其实呢,比较的是RID里的BID,选举RID小的作为根网桥