自动机器学习:最近进展研究综述
深度学习已经运用到多个领域,为人们生活带来极大便利。然而,为特定任务构造一个高质量的深度学习系统不仅需要耗费大量时间和资源,而且很大程度上需要专业的领域知识。
因此,为了让深度学习技术以更加简单的方式应用到更多的领域,自动机器学习(AutoML)逐渐成为人们关注的重点。
本文首先从端到端系统的角度总结了自动机器学习在各个流程中的研究成果(如下图),然后着重对最近广泛研究的神经结构搜索(Neural Architecture Search, NAS)进行了总结,最后讨论了一些未来的研究方向。

一、数据准备
众所周知,数据对于深度学习任务而言至关重要,因此一个好的AutoML系统应该能够自动提高数据质量和数量,我们将数据准备划分成两个部分:数据收集和数据清洗。
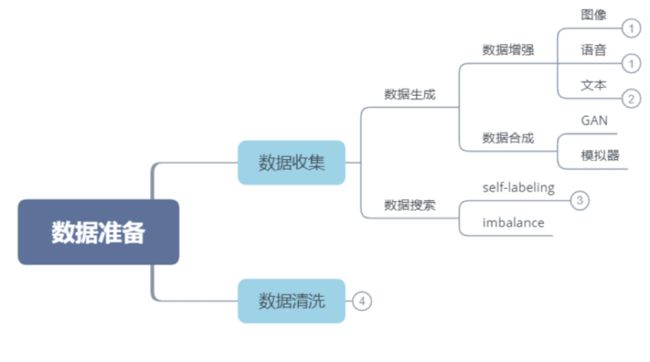
1、数据收集
现如今不断有公开数据集涌现出来,例如MNIST,CIFAR10,ImageNet等等。我们也可以通过一些公开的网站获取各种数据集,例如Kaggle, Google Dataset Search以及Elsevier Data Search等等。但是对于一些特殊的任务,尤其是医疗或者涉及到个人隐私的任务,由于数据很难获取,所以通常很难找到一个合适的数据集或者数据集很小。解决这一问题主要有两种思路:数据生成和数据搜索。
1)数据生成
图像:
-
Cubuk, EkinD., et al. "Autoaugment: Learning augmentation policies fromdata." arXiv preprint arXiv:1805.09501 (2018).
语音:
-
Park, DanielS., et al. "Specaugment: A simple data augmentation method for automaticspeech recognition." arXiv preprint arXiv:1904.08779(2019).
文本:
-
Xie, Ziang,et al. "Data noising as smoothing in neural network languagemodels." arXiv preprint arXiv:1703.02573 (2017).
-
Yu, Adams Wei,et al. "Qanet: Combining local convolution with global self-attention forreading comprehension." arXiv preprint arXiv:1804.09541 (2018).
GAN:
-
Karras, Tero, Samuli Laine, and Timo Aila. "A style-basedgenerator architecture for generative adversarial networks." Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
模拟器:
-
Brockman, Greg, et al. "Openai gym." arXiv preprintarXiv:1606.01540 (2016).
2)数据搜索
-
Roh, Yuji, Geon Heo, and Steven Euijong Whang. "A survey ondata collection for machine learning: a big data-ai integrationperspective." arXiv preprint arXiv:1811.03402(2018).
-
Yarowsky, David. "Unsupervised word sense disambiguationrivaling supervised methods." 33rd annual meeting of the associationfor computational linguistics. 1995.
-
Zhou, Yan, and Sally Goldman. "Democraticco-learning." 16th IEEE International Conference on Tools withArtificial Intelligence. IEEE, 2004.
2、数据清洗
-
Krishnan,Sanjay, and Eugene Wu. "Alphaclean: Automatic generation of data cleaningpipelines." arXiv preprint arXiv:1904.11827 (2019).
-
Chu, Xu, etal. "Katara: A data cleaning system powered by knowledge bases andcrowdsourcing." Proceedings of the 2015 ACM SIGMOD InternationalConference on Management of Data. ACM, 2015.
-
Krishnan,Sanjay, et al. "Activeclean: An interactive data cleaning framework formodern machine learning." Proceedings of the 2016 InternationalConference on Management of Data. ACM, 2016.
-
Krishnan,Sanjay, et al. "SampleClean: Fast and Reliable Analytics on DirtyData." IEEE Data Eng. Bull. 38.3 (2015): 59-75.
二、特征工程
特征工程可分为三个部分:
1、特征选择
2、特征构造
-
H. Vafaie and K. De Jong, “Evolutionary feature spacetransformation,” in Feature Extraction, Construction and Selection. Springer,1998, pp. 307–323
-
J. Gama, “Functional trees,” Machine Learning, vol. 55, no. 3, pp.219–250, 2004.
-
D. Roth and K. Small, “Interactive feature space construction usingsemantic information,” in Proceedings of the Thirteenth Conference onComputational Natural Language Learning. Association for Computational Linguistics,2009, pp. 66–74.
3、特征提取
-
Q. Meng, D. Catchpoole, D. Skillicom, and P. J. Kennedy, “Relationalautoencoder for feature extraction,” in 2017 International Joint Conference onNeural Networks (IJCNN). IEEE, 2017, pp. 364–371.
-
O. Irsoy and E. Alpaydın, “Unsupervised feature extraction withautoencoder trees,” Neurocomputing, vol. 258, pp. 63–73, 2017.

三、模型生成
模型生成的方式主要有两种:一是基于传统的机器学习方法生成模型,例如SVM,decision tree等,已经开源的库有Auto-sklearn和TPOT等。另一种是是神经网络结构搜索(NAS)。我们会从两个方面对NAS进行总结,一是NAS的网络结构,二是搜索策略。
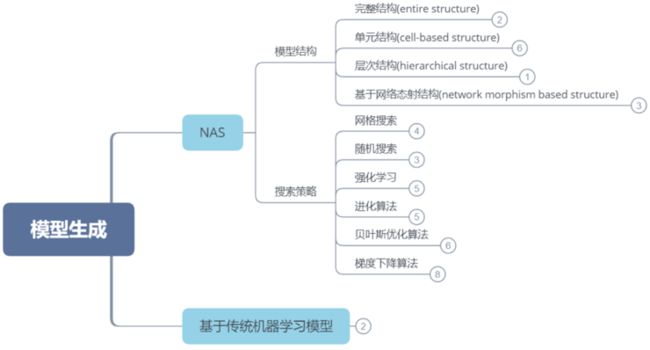
1、网络结构
1)整体结构(entire structure):
该类方法是生成一个完整的网络结构。其存在明显的缺点,如网络结构搜索空间过大,生成的网络结构缺乏可迁移性和灵活性。
-
B. Zoph and Q. V. Le, “Neural architecture search with reinforcementlearning.” [Online]. Available:http://arxiv.org/abs/1611.01578
-
H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean, “Efficientneural architecture search via parameter sharing,” vol. ICML. [Online].Available: http://arxiv.org/abs/1802.03268
2)基于单元结构(cell-based structure):
为解决整体结构网络搜索存在的问题提出了基于单元结构设计的方法。如下图所示,搜索到单元结构后需要叠加若干个单元结构便可得到最终的网络结构。不难发现,搜索空间从整个网络缩减到了更小的单元结构,而且我们可以通过增减单元结构的数量来改变网络结构。但是这种方法同样存在一个很明显的问题,即单元结构的数量和连接方式不确定,现如今的方法大都是依靠人类经验设定。

-
H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean, “Efficientneural architecture search via parameter sharing,” vol. ICML. [Online].Available: http://arxiv.org/abs/1802.03268
-
B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learningtransferable architectures for scalable image recognition.” [Online].Available: http://arxiv.org/abs/1707.07012
-
Z. Zhong, J. Yan, W. Wu, J. Shao, and C.-L. Liu, “Practicalblock-wise neural network architecture generation.” [Online]. Available:http://arxiv.org/abs/1708.05552
-
B. Baker, O. Gupta, N. Naik, and R. Raskar, “Designing neuralnetwork architectures using reinforcement learning,” vol. ICLR. [Online].Available: http://arxiv.org/abs/1611.02167
-
E. Real, S. Moore, A. Selle, S. Saxena, Y. L. Suematsu, J. Tan, Q.Le, and A. Kurakin, “Large-scale evolution of image classifiers.” [Online].Available: http://arxiv.org/abs/1703.01041
-
E. Real, A. Aggarwal, Y. Huang, and Q. V. Le, “Regularized evolutionfor image classifier architecture search.” [Online]. Available:http://arxiv.org/abs/1802.01548
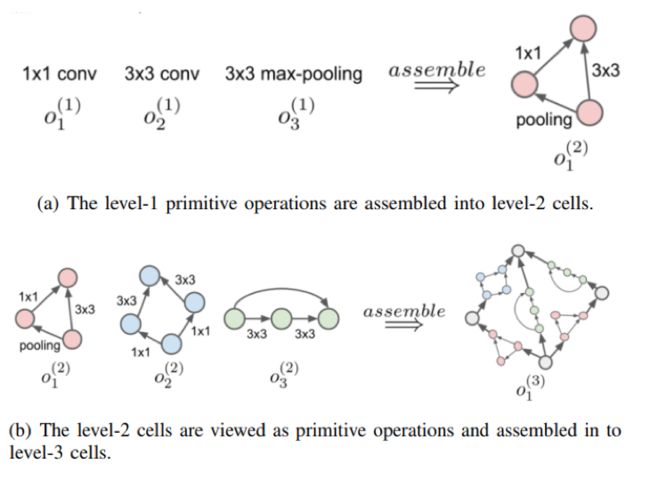
3)层次结构(hierarchical structure)
不同于上面将单元结构按照链式的方法进行连接,层次结构是将前一步骤生成的单元结构作为下一步单元结构的基本组成部件,通过迭代的思想得到最终的网络结构。如下图所示,(a)中左边3个是最基本的操作,右边是基于这些基本操作生成的某一个单元结构;(b)中左边展示了上一步骤中生成的若干个单元结构,通过按照某种策略将这些单元结构进行组合得到了更高阶的单元结构。
-
H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu,“Hierarchical representations for efficient architecture search,” in ICLR, p.13
4)基于网络态射结构(network morphism-based structure):
一般的网络设计方法是首先设计出一个网络结构,然后训练它并在验证集上查看它的性能表现,如果表现较差,则重新设计一个网络。可以很明显地发现这种设计方法会做很多无用功,因此耗费大量时间。而基于网络态射结构方法能够在原有的网络结构基础上做修改,所以其在很大程度上能保留原网络的优点,而且其特殊的变换方式能够保证新的网络结构还原成原网络,也就是说它的表现至少不会差于原网络。
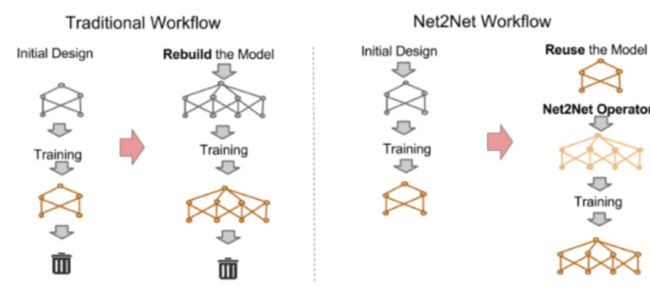
-
T. Chen, I. Goodfellow, and J. Shlens, “Net2net: Acceleratinglearning via knowledge transfer,” arXiv preprint arXiv:1511.05641, 2015.
-
T. Elsken, J. H. Metzen, and F. Hutter, “Efficient multi-objectiveneural architecture search via lamarckian evolution.” [Online]. Available:http://arxiv.org/abs/1804.09081
-
H. Cai, T. Chen, W. Zhang, Y. Yu, and J. Wang, “Efficientarchitecture search by network transformation,” in Thirty-Second AAAIConference on Artificial Intelligence, 2018
2、搜索策略
1)网格搜索
-
H. H. Hoos, Automated Algorithm Configuration and Parameter Tuning,2011
-
I. Czogiel, K. Luebke, and C. Weihs, Response surface methodologyfor optimizing hyper parameters. Universitatsbibliothek Dortmund, 2006.
-
C.-W. Hsu, C.-C. Chang, C.-J. Lin et al., “A practical guide tosupport vector classification,” 2003.
-
J. Y. Hesterman, L. Caucci, M. A. Kupinski, H. H. Barrett, and L. R.Furenlid, “Maximum-likelihood estimation with a contracting-grid searchalgorithm,” IEEE transactions on nuclear science, vol. 57, no. 3, pp.1077–1084, 2010.
2)随机搜索
-
J. Bergstra and Y. Bengio, “Random search for hyper-parameteroptimization,” p. 25.
-
H. Larochelle, D. Erhan, A. Courville, J. Bergstra, and Y. Bengio,“An empirical evaluation of deep architectures on problems with many factors ofvariation,” in Proceedings of the 24th international conference on Machinelearning. ACM, 2007, pp. 473–480.
-
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar,“Hyperband: A novel bandit-based approach to hyperparameter optimization.”[Online]. Available: http://arxiv.org/abs/1603.06560
3)强化学习
-
B. Zoph and Q. V. Le, “Neural architecture search with reinforcementlearning.” [Online]. Available: http://arxiv.org/abs/1611.01578
-
B. Baker, O. Gupta, N. Naik, and R. Raskar, “Designing neuralnetwork architectures using reinforcement learning,” vol. ICLR. [Online].Available: http://arxiv.org/abs/1611.02167
-
H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean, “Efficientneural architecture search via parameter sharing,” vol. ICML. [Online].Available: http://arxiv.org/abs/1802.03268
-
B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learningtransferable architectures for scalable image recognition.” [Online].Available: http://arxiv.org/abs/1707.07012
-
Z. Zhong, J. Yan, W. Wu, J. Shao, and C.-L. Liu, “Practical block-wiseneural network architecture generation.” [Online]. Available:http://arxiv.org/abs/1708.05552
4)进化算法
-
L. Xie and A. Yuille, “Genetic CNN,” vol. ICCV. [Online]. Available:http://arxiv.org/abs/1703.01513
-
M. Suganuma, S. Shirakawa, and T. Nagao, “A genetic programmingapproach to designing convolutional neural network architectures.” [Online].Available: http://arxiv.org/abs/1704.00764
-
E. Real, S. Moore, A. Selle, S. Saxena, Y. L. Suematsu, J. Tan, Q.Le, and A. Kurakin, “Large-scale evolution of image classifiers.” [Online].Available: http://arxiv.org/abs/1703.01041
-
K. O. Stanley and R. Miikkulainen, “Evolving neural networks throughaugmenting topologies,” vol. 10, no. 2, pp. 99–127. [Online]. Available:http://www.mitpressjournals.org/doi/10.1162/106365602320169811
-
T. Elsken, J. H. Metzen, and F. Hutter, “Efficient multi-objectiveneural architecture search via lamarckian evolution.” [Online]. Available:http://arxiv.org/abs/1804.09081
5)贝叶斯算法
-
J. Gonzalez, “Gpyopt: A bayesian optimization framework in python,”http://github.com/SheffieldML/GPyOpt, 2016
-
J. Snoek, H. Larochelle, and R. P. Adams, “Practical bayesianoptimization of machine learning algorithms,” in Advances in neural informationprocessing systems, 2012, pp. 2951–2959.
-
S. Falkner, A. Klein, and F. Hutter, “BOHB: Robust and efficienthyperparameter optimization at scale,” p. 10.
-
F. Hutter, H. H. Hoos, and K. Leyton-Brown, “Sequential model-basedoptimization for general algorithm configuration,” in Learning and IntelligentOptimization, C. A. C. Coello, Ed. Springer Berlin Heidelberg, vol. 6683, pp.507–523. [Online]. Available:http://link.springer.com/10.1007/978-3-642-25566-3 40
-
J. Bergstra, D. Yamins, and D. D. Cox, “Making a science of modelsearch: Hyperparameter optimization in hundreds of dimensions for visionarchitectures,” p. 9.
-
A. Klein, S. Falkner, S. Bartels, P. Hennig, and F. Hutter, “Fastbayesian optimization of machine learning hyperparameters on large datasets.”[Online]. Available: http://arxiv.org/abs/1605.07079
6)梯度下降算法
-
H. Liu, K. Simonyan, and Y. Yang, “DARTS: Differentiablearchitecture search.” [Online]. Available: http://arxiv.org/abs/1806.09055
-
S. Saxena and J. Verbeek, “Convolutional neural fabrics,” inAdvances in Neural Information Processing Systems, 2016, pp. 4053–4061.
-
K. Ahmed and L. Torresani, “Connectivity learning in multi-branchnetworks,” arXiv preprint arXiv:1709.09582, 2017.
-
R. Shin, C. Packer, and D. Song, “Differentiable neural networkarchitecture search,” 2018.
-
D. Maclaurin, D. Duvenaud, and R. Adams, “Gradient-basedhyperparameter optimization through reversible learning,” in InternationalConference on Machine Learning, 2015, pp. 2113–2122.
-
F. Pedregosa, “Hyperparameter optimization with approximategradient,” arXiv preprint arXiv:1602.02355, 2016.
-
S. H. Han Cai, Ligeng Zhu, “PROXYLESSNAS: DIRECT NEURAL ARCHITECTURESEARCH ON TARGET TASK AND HARDWARE,” 2019
-
G. D. H. Andrew Hundt, Varun Jain, “sharpDARTS: Faster and MoreAccurate Differentiable Architecture Search,” Tech. Rep. [Online]. Available:https://arxiv.org/pdf/1903.09900.pdf
三、模型评估
模型结构设计好后我们需要对模型进行评估,最简单的方法是将模型训练至收敛,然后根据其在验证集上的结果判断其好坏。但是这种方法需要大量时间和计算资源。因此有不少加速模型评估过程的算法被提出,总结如下:
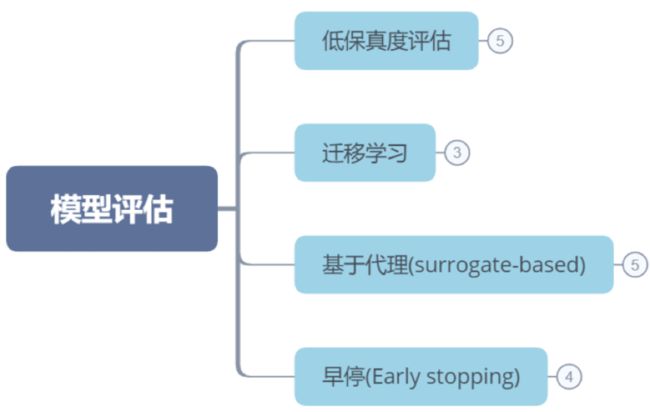
1、低保真度评估
-
Klein, S. Falkner, S. Bartels, P. Hennig, and F. Hutter, “Fastbayesian optimization of machine learning hyperparameters on large datasets.”[Online]. Available: http://arxiv.org/abs/1605.07079
-
B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learningtransferable architectures for scalable image recognition.” [Online]. Available:http://arxiv.org/abs/1707.07012
-
E. Real, A. Aggarwal, Y. Huang, and Q. V. Le, “Regularized evolutionfor image classifier architecture search.” [Online]. Available:http://arxiv.org/abs/1802.01548
-
A. Zela, A. Klein, S. Falkner, and F. Hutter, “Towards automateddeep learning: Efficient joint neural architecture and hyperparameter search.” [Online].Available: http://arxiv.org/abs/1807.06906
-
Y.-q. Hu, Y. Yu, W.-w. Tu, Q. Yang, Y. Chen, and W. Dai,“Multi-Fidelity Automatic Hyper-Parameter Tuning via Transfer Series Expansion,” p. 8, 2019.
2、迁移学习
-
C. Wong, N. Houlsby, Y. Lu, and A. Gesmundo, “Transfer learning withneural automl,” in Advances in Neural Information Processing Systems, 2018, pp.8356–8365.
-
T. Wei, C. Wang, Y. Rui, and C. W. Chen, “Network morphism,” inInternational Conference on Machine Learning, 2016, pp. 564–572.
-
T. Chen, I. Goodfellow, and J. Shlens, “Net2net: Acceleratinglearning via knowledge transfer,” arXiv preprint arXiv:1511.05641, 2015.
3、基于代理(surrogate-based)
-
K. Eggensperger, F. Hutter, H. H. Hoos, and K. Leyton-Brown,“Surrogate benchmarks for hyperparameter optimization.” in MetaSel@ ECAI, 2014,pp. 24–31.
-
C. Wang, Q. Duan, W. Gong, A. Ye, Z. Di, and C. Miao, “An evaluationof adaptive surrogate modeling based optimization with two benchmark problems,”Environmental Modelling & Software, vol. 60, pp. 167–179,2014.
-
K. Eggensperger, F. Hutter, H. Hoos, and K. Leyton-Brown, “Efficientbenchmarking of hyperparameter optimizers via surrogates,” in Twenty-Ninth AAAIConference on Artificial Intelligence, 2015.
-
K. K. Vu, C. D’Ambrosio, Y. Hamadi, and L. Liberti, “Surrogate-basedmethods for black-box optimization,” International Transactions in OperationalResearch, vol. 24, no. 3, pp. 393–424, 2017.
-
C. Liu, B. Zoph, M. Neumann, J. Shlens, W. Hua, L.-J. Li, L.Fei-Fei, A. Yuille, J. Huang, and K. Murphy, “Progressive neural architecturesearch.” [Online]. Available: http://arxiv.org/abs/1712.00559
4、早停(early-stopping)
-
A. Klein, S. Falkner, J. T. Springenberg, and F. Hutter, “Learningcurve prediction with bayesian neural networks,” 2016.
-
B. Deng, J. Yan, and D. Lin, “Peephole: Predicting networkperformance before training,” arXiv preprint arXiv:1712.03351, 2017.
-
T. Domhan, J. T.Springenberg, and F. Hutter, “Speeding up automatic hyperparameter optimizationof deep neural networks by extrapolation of learning curves,” in Twenty-FourthInternational Joint Conference on Artificial Intelligence, 2015.
-
M. Mahsereci, L. Balles, C. Lassner, and P. Hennig, “Early stoppingwithout a validation set,” arXiv preprint arXiv:1703.09580, 2017.
四、NAS算法性能总结
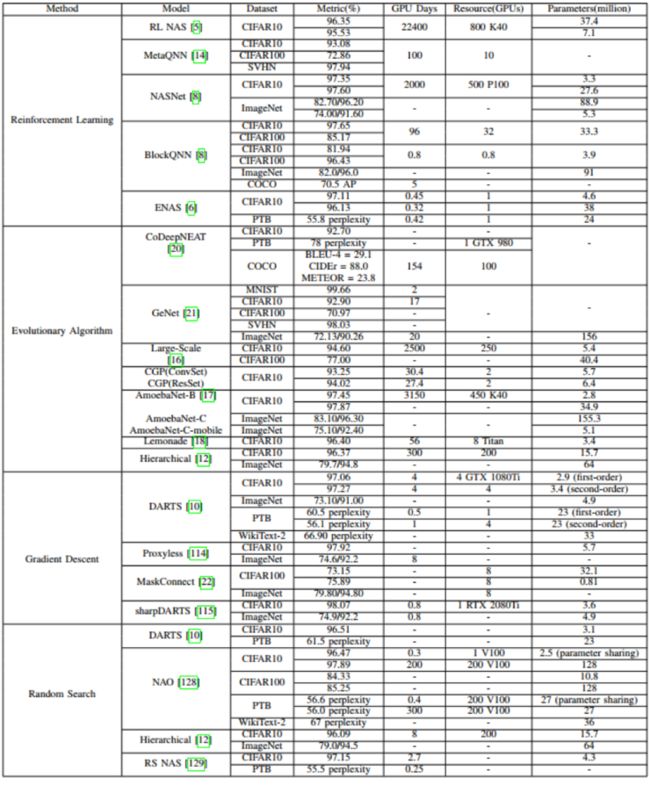
下图总结了不同NAS算法在CIFAR10上的搜索网络所花费的时间以及准确率。可以看到相比于基于强化学习和进化算法的方法,基于梯度下降和随机搜索的方法能够使用更少的时间搜索得到表现优异的网络模型。

五、总结
通过对AutoML最新研究进展的总结我们发现还有如下问题值得思考和解决:
1、完整pipeline系统
现如今有不少开源AutoML库,如TPOT,Auto-sklearn都只是涉及整个pipeline的某一个或多个过程,但是还没有真正实现整个过程全自动,因此如何将上述所有流程整合到一个系统内实现完全自动化是未来需要不断研究的方向。
2、可解释性
深度学习网络的一个缺点便是它的可解释性差,AutoML在搜索网络过程中同样存在这个问题。目前还缺乏一个严谨的科学证明来解释
为什么某些操作表现更好,例如
就基于单元结构设计的网络而言,很难解释为什么通过叠加单元结构就能得到表现不错的网络结构。另外为何ENAS提出的权值共享能够work同样值得思考。
3、可复现性
大多数的AutoML研究工作都只是报告了其研究成果,很少会开源其完整代码,有的只是提供了最终搜索得到的网络结构而没有提供搜索过程的代码。另外较多论文提出的方法难以复现,一方面是因为他们在实际搜索过程中使用了很多技巧,而这些都没有在论文中详细描述,另一方面是网络结构的搜索存在一定的概率性质。因此如何确保AutoML技术的可复现性也是未来的一个方向。
4、灵活的编码方式
通过总结NAS方法我们可以发现,所有方法的搜索空间都是在人类经验的基础上设计的,所以最终得到的网络结构始终无法跳出人类设计的框架。例如现如今的NAS无法凭空生成一种新的类似于卷积的基本操作,也无法生成像Transformer那样复杂的网络结构。因此如何定义一种泛化性更强,更灵活的网络结构编码方式也是未来一个值得研究的问题。
5、终身学习(lifelong learn)
大多数的AutoML都需要针对特定数据集和任务设计网络结构,而对于新的数据则缺乏泛化性。而人类在学习了一部分猫狗的照片后,当出现未曾见过的猫狗依然能够识别出来。因此一个健壮的AutoML系统应当能够终身学习,即既能保持对旧数据的记忆能力,又能学习新的数据。
本文作者为香港浸会大学贺鑫,雷锋网AI科技评论获其授权发表。
英文标题 | AutoML:A survey of State-of-the-art
作 者 | Xin He, Kaiyong Zhao, Xiaowen Chu
单 位 | Hong Kong Baptist University(香港浸会大学)
论文链接 | https://arxiv.org/abs/1908.00709
IJCAI 2019 MACAO 现场直播,人工智能领域中最主要的学术会议之一,明早八点半开始噢~