不得不会的Flink Dataset的DeltaI 迭代操作
flink作为一个优秀的流处理框架,自有其独到之处,前面浪尖已经分享了很多了,比如下面几篇文章:
Flink异步IO第一讲
flink的神奇分流器-sideoutput
Flink特异的迭代操作-bulkIteration
本节内容是继上次的bulkIteration迭代操作的后续篇,delta迭代操作。
与bulkIteration不同的是,Delta迭代操作就是为了解决增量迭代需求。增量迭代就是有选择的修改要迭代的元素,逐步计算,而不是全部重新计算。
这在某些情况下会使得算法更加高效,因为并不是所有的元素在每次迭代的时候都需要重新计算。这样就可以专注于热点元素进行处理,而剩余的冷元素不处理。通常情况下,是只需要进行局部计算的。
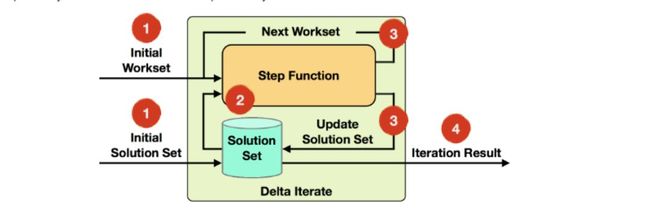
迭代输入:迭代计算读取要读取的workset和solutionset 。
step函数:每次迭代都要执行的函数,是由map,reduce,join等函数组成的数据流,具体要取决于你的业务逻辑。
Next Workset/update solution set:nextworkset驱动这迭代计算的执行,并将反馈到下次迭代。此外,solution set会被更新同时隐士向前传输(它不需要重新构建)。两个数据集都可以被step函数的不同操作更新。
迭代结果:最后一次迭代结束之后,solution set会被写入datasink 或者作为下个操作算子的输出。
Delta迭代的默认终止条件是返回的workset为空或者达到最大迭代次数。自定义聚合和收敛标准也是可以的。
案例
在一个图中传递最小值。例子中,每个顶点都有一个ID和一种颜色。每个顶点都会将其ID传递给相邻的顶点,目标是将最小值传遍整个图。如果一个顶点接收到的ID比自己当前的小,就将颜色替换成接收到ID的顶点颜色。在社区分析和联通性计算中常用。
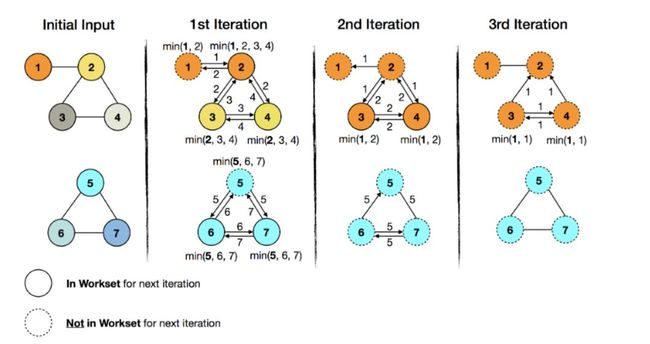
上图颜色代表着solution set的演进过程。随着迭代次数的增加,最小ID的颜色在各自的子图中蔓延,同时计算内容(交换和比较顶点ID)在减少。相应的workset大小也会减少,会使得在3次迭代之后七个顶点变为0个,这时候就会终止迭代。
第一次迭代
对于第一个子图,ID 1 会和ID2进行比较,并且ID 2变成ID 1的颜色。ID 3 和ID 4会接收到ID 2 并与其进行比较,使得ID 3 ID4变成ID 2的颜色。此时就可以next worker里就会减去未改变的顶点1.
对于第二个子图,第一次遍历ID 6 ID7就会变成ID 5的颜色,结束遍历。Next work里会减去未改变的顶点5.
第二次迭代
此时next work里的顶点由于已经减去顶点 1 和顶点5,所以只剩顶点(2,3,4,6,7)。在第二次迭代之后,第二个子图就不会在变化了,next workset里不会有其顶点,然而第一个子图,由于顶点3和4又一次变化,所以还需要第三次迭代。此时,第一个子图就是热数据,第二个子图就是冷数据。计算就变成了针对第一个子图的局部计算,针对第一个子图的顶点3和顶点4进行计算。
第三次迭代
由于顶点3和4都不会变化,next workset就为空了,然后就会终止迭代。
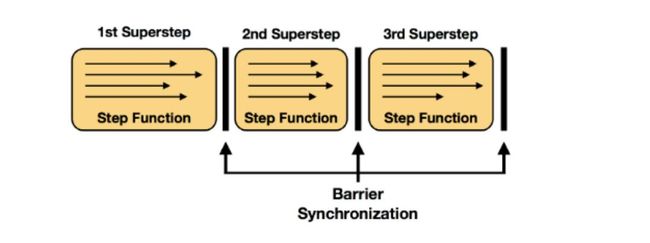
超级同步
我们将step函数的每次执行称为单次迭代。在并行情况下,step函数的多个实例会并行的处理迭代状态的不同分区。在许多设置中,对所有并行实例的step函数的一个计算形成所谓的超级步骤,其也是同步的粒度。因此,迭代的所有并行任务都需要在初始化下一个超级步骤之前完成超级步骤。终止标准也将在超级障碍处计算。
代码案例
delta迭代依赖于每次大部分算法的每次迭代仅仅只需要计算部分数据的事实。
定义delta迭代器根bulkIteration类似。不过,对于delta迭代器,有两个输入数据集(next workset 和solution set),而且每个数据集都是每次迭代的输出结果。
调用iterateDelta(Dataset,int,int)或者iterateDelta(Dataset,int,int[] )就可以创建一个DeltaIteration。要用initialSolutionSet调用该方法,同时传入deltaset,最大迭代次数,和key位置。通过创建的DeltaIteration,我们也可以获取得到workset和solution set。
详细代码案例,可以关注浪尖公众号输入 delta 获取。
