《机器学习实战》2.K-近邻算法分析与源码实现(文末附官方勘误表)
结合源码分析第二章中实现的Demo
本人安装的是Anaconda,程序在Jupyter Notebook上运行的。
第一次实战,注解比较多。另外我将一些函数做了总结与对比,见我的这篇文章
前言
k近邻是一种基本分类与回归方法。k近邻法的输入为实例的特征向量,对应于特征空间的点,输出为实例的类别,可以取多类。k近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其K个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻不具有显示的学习过程(训练时间开销为0)。k值的选择,距离度量及分类决策规则是k近邻法的三个基本要素。
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算复杂度高,空间复杂度高
适用数据范围:数值型和标称型
1.k近邻算法的一般流程
- 收集数据
- 准备数据:距离计算所需要的数值(最好是结构化的数据格式)<从文本中解析数据,归一化数值>
- 分析数据:可以使用任何方法(不局限于Matplotlib画二维散点图等)
- 训练算法:此步骤不适合KNN
- 测试算法:计算错误率<数据集=训练集+测试集>
- 使用算法:产生简单的命令行程序,然后每轮输入一些特征数据以判断对方是否为自己喜欢的类型。
2.1.1 准备:使用Python导入数据
输入:
import numpy as np
from numpy import *
def createDataSet():
group = np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labelsgroup,labels=createDataSet()
group输出:
array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]])输入
labels输出:
['A', 'A', 'B', 'B']2.1.2 实施KNN算法
#语法:numpy.argsort(a, axis=-1, kind='quicksort', order=None)
#功能:将a中的元素从小到大排列,最后返回其所对应的索引。
# 示例:
# import numpy as np
# a=np.array([1,4,3,-1,6,9])
# a.argsort()
# 输出结果:
# array([3, 0, 2, 1, 4, 5], dtype=int64)
# 很多函数根据axis的取值不同,得到的结果也完全不同
# 总结为一句话:设axis=i,则numpy沿着第i个下标变化的方向进行操作。 # 输入为四个参数
# 用于输入向量是inX,输入的训练样本集为dataSet,标签向量为labels,k
# 表示用于选择最近邻居的数目。
# 注意:labels元素数目和矩阵dataSet的行数相同
# 程序使用欧式距离公式。此外,还有Lp距离或Minkowski距离
def classify0(inX, dataSet, labels, k):
#1.距离计算
dataSetSize = dataSet.shape[0] #获取训练样本数据集的个数
#print('dataSetSize(训练样本数据集的个数):',dataSetSize)
diffMat = tile(inX,(dataSetSize,1)) - dataSet #具体这一步的操作就是生成和训练样本对应的矩阵,并与训练样本求差
#语法:numpy.tile(A,reps)
#tile:列—dataSetSize表示复制的行数 行—1表示对inX的重复的次数
#print((inX,(dataSetSize,1)))
#print('tile的功能(将inX复制了dataSetSize行):')
#print(tile(inX,(dataSetSize,1)))
sqDiffMat = diffMat**2 #求平方
sqDistances = sqDiffMat.sum(axis=1) #对平方后的矩阵每一行进行相加
distance=sqDistances**0.5 #开根号
sortedDistIndicies=distance.argsort() #距离从小到大(从近到远)的排列,并返回其所对应的索引
#print('sortedDistIndicies(距离由近到远的点的索引):',sortedDistIndicies)
#2.选择距离最小的k个点
classCount={} #定义一个字典
#print('labels(标签分别是):',labels)
for i in range (k): #range(k) 创建一个有序数组,具体为[0,1,2....k-1]
#找到该样本的类型
voteIlabel = labels[sortedDistIndicies[i]]
#get 返回键值key对应的值;如果key没有在字典里,则返回default参数的值,默认为0。
#功能是计算每个标签类别的个数
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 #在字典中将该类型加一
#语法:dict.get(key, default=None)
#key --字典中要查找的值;default --如果指定键的值不存在时,返回该默认值值。(默认为None)
#3.排序并返回出现最多的那个类型
#语法:dict.items() 功能:以列表返回可遍历的(键,值)元组数组
#例如: dict = {'Name': 'zhangzhiming', 'Age': 23} print('value: %s' % dict.items())
#输出:value: dict_items([('Name', 'zhangzhiming'), ('Age', 23)])
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#语法:sorted(iterable,*,key=None,reverse=False)
#key按第一个域进行排序,默认False为升序排序。此处True为逆序,即按照频率从大到小次序排序。
#sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
#sort是在原有基础上排序,sorted 排序是产生一个新的列表。
#语法: operator.itemgetter(item)
#功能: 用于获取对象的指定维数据,参数为序号
#注意: operator.itemgetter函数获取的不是值,而是定义了一个函数。通过该函数作用到对象上,才能获取值。
#示例:import operator
# a=[1,2,3]
# b=operator.itemgetter(1)
# b(a)
#输出:2 <获取对象的第一个域的值>
#print('sortedClassCount:',sortedClassCount)
return sortedClassCount[0][0] #最后返回发生频率最高的元素标签。为了预测数据所在分类,输入下列命令:
#调用函数
classify0([0,0],group,labels,2)输出:
'B'到现在为止,我们已经构造了第一个分类器,使用这个分类器可以完成很多分类任务。从这个实例出发,构造使用分类算法将会更将容易。
2.2 示例:使用K-近邻算法改进约会网站的配对效果
2.2.1 准备数据:从文本文件中解析数据
#准备数据:从文本中解析数据
# 输入:文件名字符串(文件路径)
# 功能:返回训练样本矩阵returnMat和类标签向量classLabelVector
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #获得文件中的数据行的行数
#print('numberOfLines(数据行数):',numberOfLines)
#语法:len(s)
#功能:返回对象长度或项目个数
#语法:fileObject.readlines( );
#功能:用于读取所有行(直到结束符 EOF)并返回列表
#zeros(2,3)生成一个2*3的矩阵,元素全为0
returnMat = zeros((numberOfLines, 3)) #prepare matrix to return
classLabelVector = [] # prepare labels return
#print('returnMat(构造的一个空矩阵):',returnMat)
fr = open(filename)
index = 0
for line in fr.readlines():
#语法:str.strip([chars])
#功能:返回移除字符串头尾指定的字符生成的新字符串(默认是去除首尾空格)
line = line.strip()
#语法:str.split(str="", num=string.count(str))
# str 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
# num 分割次数
#功能: 返回分割后的字符串列表
listFromLine = line.split('\t') #以'\t'切割字符串
#每列的属性数据
returnMat[index, :] = listFromLine[0:3] #[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3
#每列的类别数据,就是label标签数据
classLabelVector.append(int(listFromLine[-1])) #-1作索引,获取最后一列数据
#int告诉它列表中存储的元素值为整型,否则会将这些元素当做字符串处理!
index += 1
#返回数据矩阵returnMat和classLabelVector
return returnMat, classLabelVector接着在Jupyter中输入下列命令:
datingDataMat,datingLabels = file2matrix(r'C:\Users\Rujin_shi\Apache_cn\datingTestSet2.txt')
#这里将路径换成你的路径,每个人不一样datingDataMat输出:
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])输入:
datingLabels[0:20]输出:
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3]2.2.2分析数据:使用Matplotlib创建散点图
输入:
#分析数据:使用Matplotlib画二维散点图
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax=fig.add_subplot(111) #
plt.xlabel('percentage of time spent playing video games')
plt.ylabel('liters of ice cream consumed per weak')
ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
plt.show()输出:
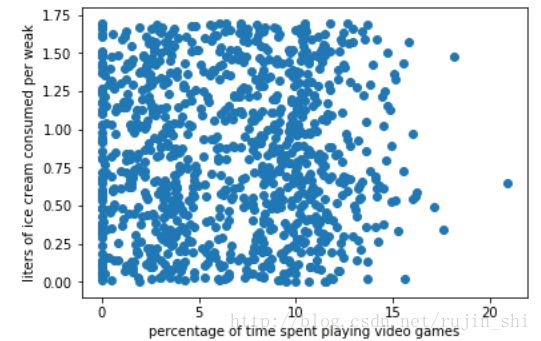
由于没有使用样本分类的特征值,所以我们很难从上面的图片中看到任何有用的数据模式信息(潜在的联系)。故尝试使用彩色或其他的记号来标记不同样本分类,以便更好地理解数据信息。
做代码调整输入:
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2], 15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()输出:
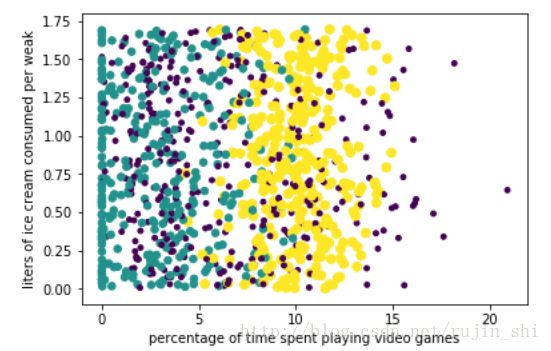
上图中使用了datingDataMat矩阵的第二列第三列属性来展示数据,虽然可以区别,但是若使用矩阵的第一列和第二列属性却可以得到更好的展示效果。
做代码调整输入:
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1], 15*array(datingLabels),15*array(datingLabels))
plt.xlabel('frequent flier miles earned per year')
plt.ylabel('percentage of time spent playing video games')
plt.show()输出:
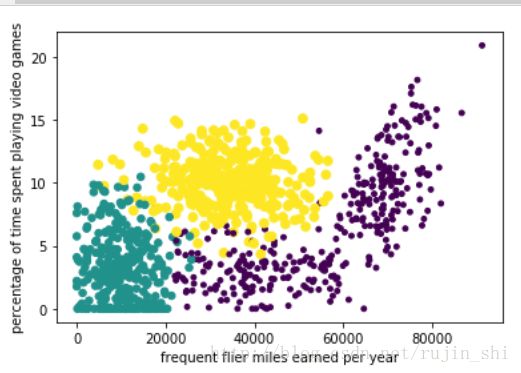
图中清晰地标识了三个不同样本分类区域,具有不同爱好的人其类别区域也不同。
2.2.3 准备数据:归一化数值
归一化的必要性:消除属性之间量级不同导致的影响
常用的归一化方法有:1.min-max 2.z-score
本例中使用min-max方法,公式为:Y = (X-Xmin)/(Xmax-Xmin)
具体程序清单:
#输入:数据集
#功能:返回归一化后的数据集,最大值和最小值之差以及最小值(后两者并没有实际用到)
def autoNorm(dataSet):
minVals = dataSet.min(0)
#print('minVals(特征的极小值):',minVals)
maxVals = dataSet.max(0)
#print('maxVals(特征的极大值):',maxVals)
ranges = maxVals - minVals #计算极差
#print('ranges(特征的极差):',ranges)
normDataSet = zeros(shape(dataSet)) ##prepare matrix to return
m = dataSet.shape[0]
#print('m(数据集行数):',m)
normDataSet = dataSet - tile(minVals,(m,1))
normDataSet = normDataSet / tile(ranges,(m,1)) #在numpy中矩阵除法需要使用函数linalg.solve(matA,matB)
return normDataSet, ranges ,minVals输入:
autoNorm(datingDataMat)输出:
(array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]]),
array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00]),
array([ 0. , 0. , 0.001156]))2.2.4测试算法:作为完整程序验证分类器
程序清单:
#测试算法:验证分类器的正确率
#功能:返回分类错误率
def datingClassTest():
hoRatio = 0.10 #测试集所占的比例
datingDataMat,datingLabels = file2matrix(r'C:\Users\Rujin_shi\Apache_cn\datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 1)
print("the classifierResult came back with :%d,the real answer is : %d" %(classifierResult,datingLabels[i]))
if (classifierResult != datingLabels[i]) : errorCount += 1.0
print("the total error rate is: %f " %(errorCount/float(numTestVecs)))输入:
datingClassTest()输出:
the classifierResult came back with :3,the real answer is : 3
the classifierResult came back with :2,the real answer is : 2
the classifierResult came back with :1,the real answer is : 1
......
the classifierResult came back with :2,the real answer is : 1
the classifierResult came back with :1,the real answer is : 1
the total error rate is: 0.080000 2.2.5 使用算法:构建完整可用系统
#使用算法,构建完整可用系统
#找到某人并输入他的信息,程序会给出她对对方喜欢程度的预测值
def classifyPerson():
resultList = ['一点不喜欢','魅力一般的人','极具魅力']
percentTats = float(input('玩游戏所耗时间百分比?'))
ffMiles = float(input('每年获得的飞行常客里程数?'))
iceCream = float(input('每周消费的冰激淋公升数?'))
datingDataMat,datingLabels = file2matrix(r'C:\Users\Rujin_shi\Apache_cn\datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffMiles,percentTats,iceCream])
classifierResult = classify0((inArr - minVals)/ranges,normMat,datingLabels,3)
print('You will probably like this person:',resultList[classifierResult - 1])输入:
classifyPerson()玩游戏所耗时间百分比?10
每年获得的飞行常客里程数?10000
每周消费的冰激淋公升数?0.6运行结果如下:
You will probably like this person: 魅力一般的人