【搜索】ElasticSearch
1.引言
ElasticSearch是一个开源的全文搜索引擎,是一个基于Lucene的面向文档的数据库,它像mogodb一样将数据按照json格式存储,然后你就可以通过查询获取他们了。

1.1 应用场景
1.1.1 blog系统的文章搜索,
文章可以存储在数据库,数据库将文章同步到ES,用户可以通过搜索框数据搜索关键字找到相关文章。

1.1.2 日志分析
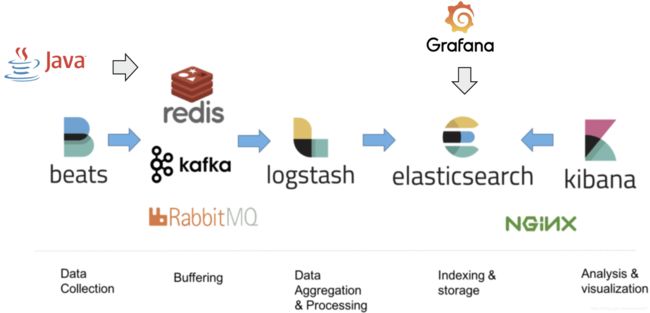
应用日志传入kafka等MQ,logstash采集处理后传入ES,通过kibana界面查询日志,通过Grafana页面观看指标等信息。
2 入门使用
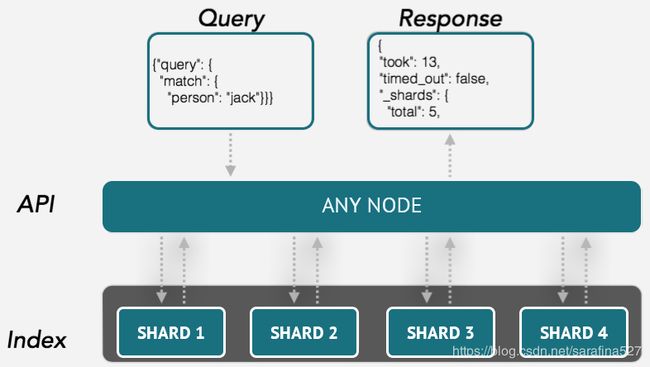
安装参考,启动服务后一般监听9200端口,一般IDE可装插件ElasticSearch,连接本机后可以使用Rest API进行交互。
也可安装kibana,安装启动后http://localhost:5601/app/kibana#/dev_tools/console 有提示补全,更友好
1.1 核心概念
ES就是每个index中有很多的文档doc

| 概念 | 含义 | 类比数据库 |
|---|---|---|
| index 索引 | 具有相同结构的文档集合 | Database数据库 |
| type 类型 | 索引的逻辑分区 一种类型被定义为具有一组公共字段的文档 7以后默认是_doc |
Table表 |
| document 文档 | JSON格式的字符串,类似于mongo中的文档含义,包含kv字段 可搜索的最小单位 |
Row行 |
| field 字段 | 文档中包含零个或者多个字段,字段类似于关系数据库中表的列 | Column列 |
| term 分词 | 索引词 | 模糊搜素的字面量? |
| mapping 映射 | 类似于关系数据库中的表结构 | Schema表结构 |
| Query DSL | Domain Specific Language | SQL |
1.2 常用API
| API | 样例&解释 |
|---|---|
| _cluster | Get /_cluster/health # 查看集群状态,绿主备正常,黄主ok无备,红主无 |
| _cat | 查看索引和分配等 |
1.2.1 文档增删改查操作
| 操作类型 | api操作 | 作用 | 类比数据库 |
|---|---|---|---|
| DDL操作 Index |
PUT school | 创建索引 | 创建数据库school |
| Put Mapping
|
设置索引下文档的schema 定义index的字段、类型,控制mobile字段不加索引 |
alter table set | |
| 增(Create) |
put my_index/_create/1 {} POST school/_doc/ {} |
创建type _doc, _source保存post的body |
创建表_doc insert into _doc |
| 删(Delete) |
DELETE | 删除文档 curl -X DELETE |
delete from |
| 改(Update) |
POST /school/_update/1 {} |
修改id为1的文档 文档必须存在,增量更新 |
update school xxx=xxx where id =1 |
| 查(Read) |
Get | 获取文档 Get school/_doc/10 |
select * from school where id=10 |

| 操作 | 响应 |
|---|---|
 |
|
 |
  |
1.2.2 Bulk批量修改
| API操作 | 响应 |
|---|---|
 |
  |
1.3.3 mget 批量读取
| 操作 | 获取多个index的docs |
|---|---|
 |
 |
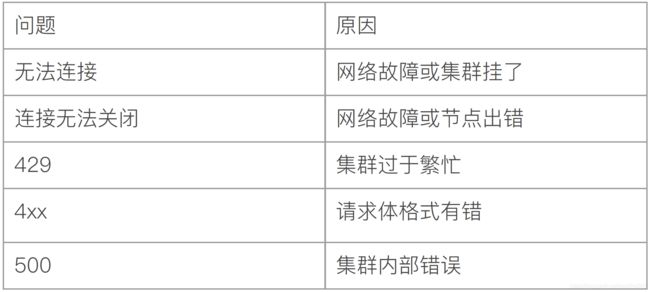
常见错误码
2.搜索_search
检索通常分为结构化检索和全文检索和其它,本文只着眼于前两种


GET /em_chinese/_search
{
"_source": ["content","author"], # 过滤字段,select content,auther
"sort": [
{
"id": {
"order": "asc" # 根据id生序排序
}
}
],
"from": 10, # 分页查询
"size": 20,
"query": {
"match": {
"annotation": "山桃" #annotation字段包含
}
}
}2.1 结构化
结构化检索非常类似于关系型数据库的查询,以下列数据为例,在本机插入4行数据,类似于mongo会自动创建index=my_store库和type=products的表,表中数据如下:
| _id | price | productId |
|---|---|---|
| 1 | 10 | XHDK-A-1293-#fJ3 |
| 2 | 20 | KDKE-B-9947-#kL5 |
| 3 | 30 | JODL-X-1937-#pV7 |
| 4 | 30 | QQPX-R-3956-#aD8 |
curl -X POST "localhost:9200/my_store/products/_bulk?pretty" -H 'Content-Type: application/json' -d'
{ "index": { "_id": 1 }}
{ "price" : 10, "productID" : "XHDK-A-1293-#fJ3" }
{ "index": { "_id": 2 }}
{ "price" : 20, "productID" : "KDKE-B-9947-#kL5" }
{ "index": { "_id": 3 }}
{ "price" : 30, "productID" : "JODL-X-1937-#pV7" }
{ "index": { "_id": 4 }}
{ "price" : 30, "productID" : "QQPX-R-3956-#aD8" }
'
其中一条结构如下,包含了_index库、_type表、_id、_score评分和_source是Post时的数据:
{
"_index": "my_store",
"_type": "products",
"_id": "1",
"_score": 1.0,
"_source": {
"price": 10,
"productID": "XHDK-A-1293-#fJ3"
}
}2.1.1 term查询
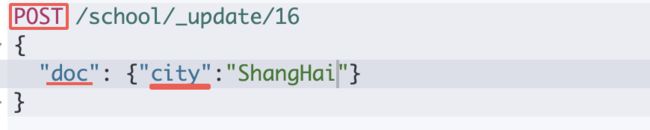
GET /school/_search?q=city:ShangHai
SELECT * FROM my_store.products WHERE price = 20{
"term" : {
"price" : 20
}
}
2.1.2 bool过滤器
bool后间的对象可以包含多个must、should、must not字段,must必须匹配=AND、must not=not
should后边的列表中表示多个条件中or关系
SELECT product
FROM products
WHERE (price = 20 OR productID = "XHDK-A-1293-#fJ3")
AND (price != 30)GET /my_store/products/_search
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 20}},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : 30}
}
}
}
}
}
}2.1.3 range
range可以比较数字、字符串字段。
SELECT document
FROM products
WHERE price BETWEEN 20 AND 40"range" : {
"price" : {
"gte" : 20,
"lte" : 40
}
}2.1.4 terms
select * from products where price in (20,30){
"terms" : {
"price" : [20, 30]
}
}2.2 全文搜索
以my_index/my_type为例,仅有一个字段title,是个较长的文本串,string是个analyzed已分析的字段
| _id | title |
|---|---|
| 1 | The quick brown fox |
| 2 | The quick brown fox jumps over the lazy dog |
| 3 | The quick brown fox jumps over the quick dog |
| 4 | Brown fox brown dog |
2.2.1 match查询
单个词查询
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "QUICK!"
}
}
}1.检查字段类型:title是string全文字段
2.分析查询字符串:QUICK!传入分析器,单个项quick,底层使用term查询
3.查找:用term在倒排索引中查找quick,返回包含其的文档
4.评分:计算文档的相关度评分_score,与词频、反向文档频率、字段长度有关。
返回id :1、2、3号文档,都包含quick这个iterm
也可以多个词查询:
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "BROWN DOG!"
}
}
}3. 全文搜索原理
全文搜索(full-text search) :怎样在全文字段中搜索到最相关的文档。
ES的json文档默认每个字段都有自己的倒排索引,可以指定对某些字段不做索引来节省空间,但是这样的话这个字段就不能被搜索到了。
全文搜索时,根据条件分词term,再用term去索引中查找,找到对应的文档,进行相关性计算算出一个score,可以根据score进行过滤或者排序。
3.1 倒排索引(inverted index)
| 领域\类型 | 正排 | 倒排 |
|---|---|---|
| 图书 | 目录页 | index关键词索引页 |
| 搜索引擎 | 根据id索引到文档内容 | 根据文档中单词索引到文档id |
以下图为例,左侧是个正排索引,有3个文档,建立倒排索引先对句子分词term,分完词后对term进行排序,unic group后就产生了从term分词到文档的映射关系。
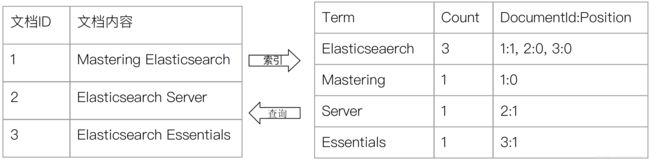
索引组成
- 单词词典term dict :记录所有单词,及倒排列表的关联关系
- 倒排列表posting List: 文档id+词频TF+position+偏移offset 列表
3.1.1 分词 Analyzer
ES的Analysis也叫分词,将文本转换为一系列单词的过程,是通过Analyzer分析器来实现的,ES有内置的,也可以按需定制。
为了更好的匹配,需要确保在写入数据时用的分析器和查询所使用的一致,否则搜索效果不好。
分析器包含3个部分,
| 组件 | 功能 |
|---|---|
| Character Filter | 处理原始文本,过滤一些html标签等 |
| Tokenizer | 按照规则切分为单词 |
| Token Filter | 对单词加工,小写,增加同义词等等 |

ES的内置分词器
| Analyzer | 功能 |
|---|---|
| Standard | 默认,按词切分,转小写 |
| Simple | 按非字母切分,小写处理 |
| Stop | 小写,停用词(the a is)过滤 |
| Whitespace | 空格切分,不转小写 |
| Keyword | 不分词 |
| Patter | 正则,非字符分割 |
| Language | 常见语言 |
| Customer | 自定义 |
中文分词
analysis-icu插件提供了unicode支持,更好地支持亚洲语言,需要安装。
bin/elasticsearch-plugin install analysis-icu |
 |
还有其它的中文分词器,IK、Thulac等等。