Cross-relation Cross-bag Attention for Distantly-supervised Relation Extraction 论文笔记
原文: Cross-relation Cross-bag Attention for Distantly-supervised Relation Extraction
AAAI 2019的一片文章。这篇文章也是针对DS的噪声问题,旨在构造一个noise-robust的训练方法。
- cross-relation attention
句子级的attention策略,即构造bag representation时每个句子权重的计算方法。作者指出传统的attention方法忽视了relation之前的联系而去独立预测,比如两个实体间有"live_in"关系,那么"died_in"就几乎不可能成立。因此在计算sentence attention时不但要考虑target relation,还要计算与other relations的打分。本质上类似多标签学习,但并不是用一个bag feature来预测多个relation,而是为每个relation构造一个bag feature,由此得名“cross-relation”。
在计算attention时用了Bayes公式:

作者假设 P ( j t h s e n t e n c e ) P(j_{th}sentence) P(jthsentence)服从均匀分布,因此在计算概率时可省略。为了方便表示将上式写成

其中 n b n_b nb是bag中的句子数目, α j , k = P ( k t h r e l a t i o n ∣ j t h s e n t e n c e ) \alpha_{j,k}=P(k_{th}relation | j_{th}sentence) αj,k=P(kthrelation∣jthsentence)由第i个bag的第j个sentence( x i , j x_{i,j} xi,j)和第k个relation( r k r_k rk)的余弦相似度构造:

可以看到 β j , k \beta_{j,k} βj,k表示在给定relation k k k的情况下,bag中每个句子 j j j的重要程度,由此得出当前bag B i B_i Bi对relation k k k的bag feature:

下面这张图表示得更清晰一些。Similarity matrix即由 S i , j , k S_{i,j,k} Si,j,k计算得到,而Correlation matrix即为 β j , k \beta_{j,k} βj,k。先从每个句子出发计算它们与各个relation的相似度并归一化(得 α j , k \alpha_{j,k} αj,k),再在relation角度归一化(得 β j , k \beta_{j,k} βj,k)描述句子的重要程度。图中 x 2 x_2 x2和 x 4 x_4 x4与 r 1 r_1 r1有相似的similarity打分,但 x 4 x_4 x4与 r 3 r_3 r3的打分更高,归一化后 r 1 r_1 r1更倾向于使用 x 2 x_2 x2的feature来学习representation。
- cross-bag attention
得到所有包对每个relation的representation后,我们可以从relation的角度重新打包,即为每个relation构造一个bag,称为superbag。这样做的好处有两种,一是superbag的标签只有一个,更“干净”。二是若原始bag中全是noisy sentences,在构造superbag时即可通过低权重把它近似舍去,减轻完全noisy bag的影响。cross-bag attention即构造superbag时的attention计算方法。
计算相对简单,也是用余弦相似度计算similarity,再归一化打分即可:
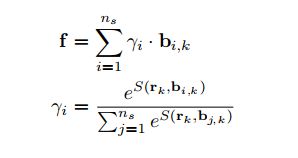
最终损失函数:
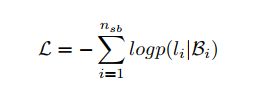
在实验中有一个超参是superbag size,设置为3,表示在构造superbag时只考虑3个原始句子bag。感觉相当于取了前三名?后续找一找代码。

实验做得挺全的。