零基础掌握百度地图兴趣点获取POI爬虫(python语言爬取)(代码篇)
好,现在进入高阶代码篇。
目的:
爬取昆明市中学的兴趣点POI。
关键词:中学
已有ak:9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
昆明市坐标范围:
左下角:24.390894,102.174112
右上角:26.548645,103.678942
URL模板:
http://api.map.baidu.com/place/v2/search?query=中学& bounds=24.390894,102.174112,26.548645,103.678942&page_size=20&page_num=0&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
工具:python2.7
我们将使用python语言来写爬虫代码。
1.功能分解
先把这个爬虫要实现的功能做一个分解。
已经知道在这个URL中,变量是bounds和page_num的值。
Bounds范围值要采取矩形分割,分4个矩形,就是4组坐标范围,page_num的值从0到19之间。
1组坐标范围20个page_num值,4×20=80。要生成的URL阵列是80个。
每个URL都能生成一个网页,每个网页上的信息都要被爬下来,保存到一个txt文件中。
A.根据bounds和page_num组合生成URL。
B.根据URL爬取网页数据,添加到txt文件中。
这将是一个循环代码:
Bounds=[矩形1,矩形2,矩形3,矩形4]
Page_nums=[0、1、2……19]
For 矩形 in bounds:
For page_num in page_nums:
URL=http://api.map.baidu.com/place/v2/search?query=中学& bounds=矩形&page_size=20&page_num=page_num&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
URL内容爬取,添加入txt文件
Next
Next
End
这个代码的框架说完了。
然后进入每个功能的代码如何实现环节。
2.功能代码实现。
代码要实现的功能是哪几个呢?
按照步骤分:
A.bounds列表的生成。
B.URL列表的生成。
C.爬取的网页内容保存到txt文本中。
(1)bounds列表生成
再说一下,因为这个是零基础教程,所以我会讲解得非常细致,python代码会由浅入深,从最简单最基础的开始。
我们看一下坐标范围:
左下角:24.390894,102.174112
右上角:26.548645,103.678942
纬度差是2.157751,经度差是1.50483。
用代码表示一下坐标范围:
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942
lat是纬度的英文,lon是经度的英文。
我们切分矩形的话,这个矩形的坐标肯定是由上面这几个坐标范围计算的来的,内插运算。
为了计算简便,我们就切方形吧,这个方形的边长我们设定一个值,假设是las(length of a side,边长英文)。
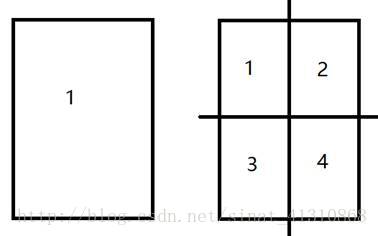
那么第一个矩形的左下角坐标是lat_1+las,lon_1,右上角坐标是lat_1+las*2,lon_1+las;第二个矩形的左下角坐标是lat_1+las,lon_1+las,右上角坐标是lat_1+las*2,lon_1+las*2……
我们设定的计算规则是:
整个坐标范围的大矩形我们叫它矩形A,切分的小矩形我们叫它矩形B。
矩形A的左下角坐标是:lat_1,lon_1,右上角坐标是lat_2,lon_2;
矩形B的边长是las。
那么计算一下矩形B的数量:
(int((lat_2-lat_1)/las)+1)*(int((lon_2-lon_1)/las)+1)
int是一个取整函数。
int(1.334)=1
int((lat_2-lat_1)/las)+1计算的是在纬度上切了几个,int((lon_2-lon_1)/las)+1计算的是在经度上切了几个,乘积就是一共几个矩形。
我们看下面一段代码:
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942 #坐标范围
las=1 #给las一个值1
lat_count=int((lat_2-lat_1)/las+1)
lon_count=int((lon_2-lon_1)/las+1)
for lat_c in range(0,lat_count):
lat_b1=lat_1+las*lat_c
for lon_c in range(0,lon_count):
lon_b1=lon_1+las*lon_c
print str(lat_b1)+','+str(lon_b1)
#这段代码生成的是矩形B的左下角坐标在IDLE中敲入这些代码,运行结果是:
24.390894,102.174112
24.390894,103.174112
25.390894,102.174112
25.390894,103.174112
26.390894,102.174112
26.390894,103.174112
因为我把las设置为1了,所以切出来6个矩形,这是这六个矩形的左下角坐标。
这行代码很简单,只涉及到两组内嵌的循环语句:for lat_c in range(0,lat_count):
用VB语言翻译一下这行就是 for lat_c=0 to lat_count step 1。
说明几个注意点:
a.python语言不需要声明变量。
b.for语句后面的:别忘了。
c.range(0,3)是[0,1,2],3不在数组里面,好好理解一下函数关系,这么个算法,说明左下角坐标是正好的,不会多一个。
d.python没有结束循环的语句,靠回车,表示嵌套关系靠的“ ”,四个空格,for语句冒号后面跟着的那行,比for语句后退了四个空格,说明这个语句是在for循环中的,如果语句要跳出for循环的话,那么就删掉四个空格,表示跳出循环。这是一个很有意思的python写码规则。
我们把这段代码改一改,获取矩形B的范围坐标:
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942 #坐标范围
las=1 #给las一个值1
lat_count=int((lat_2-lat_1)/las+1)
lon_count=int((lon_2-lon_1)/las+1)
for lat_c in range(0,lat_count):
lat_b1=lat_1+las*lat_c
for lon_c in range(0,lon_count):
lon_b1=lon_1+las*lon_c
print str(lat_b1)+','+str(lon_b1)+','+str(lat_b1+las)+','+str(lon_b1+las)
#这段代码生成的是矩形B的范围坐标运行结果如下:
24.390894,102.174112,25.390894,103.174112
24.390894,103.174112,25.390894,104.174112
25.390894,102.174112,26.390894,103.174112
25.390894,103.174112,26.390894,104.174112
26.390894,102.174112,27.390894,103.174112
26.390894,103.174112,27.390894,104.174112
好好理解一下这行代码。
(2)URL列表生成:
bounds列表生成之后,page_num在range(0,20)中遍历一遍,就生成了URL列表了。
代码如下:

看看这张图,好好理解一下循环与空格之间的关系,python没有结束循环的语句,就靠空格来做嵌套。
把这段代码完善一下,主要是URL那段怎么写。

其中:
url=’http://api.map.baidu.com/place/v2/search?query=中学& bounds=’+str(lat_b1)+’,’+str(lon_b1)+’,’+str(lat_b1+las)+’,’+str(lon_b1+las)+’&page_size=20&page_num=’+str(page_num)+’&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO’
print url
URL列表也生成了,是不是曙光在望了?
继续!
(3)网页解析
我们先学习一下网页的爬取,依然用这行URL来学习。
http://api.map.baidu.com/place/v2/search?query=中学& bounds=24.390894,102.174112,26.548645,103.678942&page_size=20&page_num=0&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
我用的python2.7,我们写一段代码,把这个URL上的数据爬下来。
打开IDLE,file——new file(ctrl+n),新建一个py文件,在里面敲代码。当然也可以在python shell里面一行一行敲,对于初学者来说,这种方式比较合适,一行一行敲,错了就有提示。
我们简单敲入一段代码,看看怎么爬取网页:
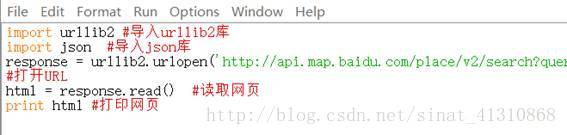
在代码的最开始,我们看到导入了两个库,一个是urllib2库,一个是json,这是要解析百度开放平台URL必须要导入的两个库,urllib2是做网页解析的,而URL中,我们仔细查看,会看到“output=json”,URL的网页输出是以这种格式输出的。
输出结果如下:

但显然,我们不需要这样的数据,在结果“results”中,我们只需要name、lat、lng、address的值,这时候,就需要对json数据格式进行解析了。
我们把这段代码修改一下:
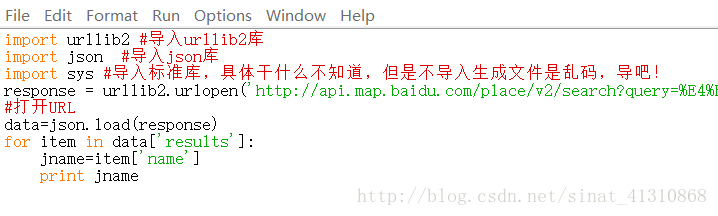
与上文不同的是,我们还导入了一个sys库,解释如图。
用加载的方式,json.load(response)在python中载入了URL生成的json数据,用一个循环读入了json数据中的results中name,仔细观察json数据结构就能理解这些代码。
运行结果如下:

当然,我们要获取的是四个值,name、lat、lng、address,那么把这行代码改写一下吧!
改写的代码部分如下:
for item in data['results']:
jname=item['name']
jlat=item['location']['lat']
jlon=item['location']['lng']
jadd=item['address'](5)python默认编码问题。
python默认的编码是ASCII,不过URL解析的json文件编码是uft-8。
如果不对编码方式进行重新设定,就会出现中文乱码问题。
把python默认编码从ascii转到uft-8的代码是固定的。
# -*- coding:utf-8 -*
import os
import sys
reload(sys)
sys.setdefaultencoding('utf-8')把这段代码放在代码前端即可。
我们将要实现的代码前端如图,保证代码行的顺序。

(6)txt文件写入
f=open(r'D:\python\kunmingschool.txt','a')
f.write('zhongxue')
f.close()这是一段最简单的文本写入代码,打开D:\python\kunmingschool.txt这个文件,以添加方式写入,写入zhongxue,把文件关闭。
A.文件全路径前面加一个r,这是防止字符转译的,就是怕识别不了路径。
B.a的意思是以添加方式写入,如果是w的话,就是覆盖方式写入。
C.写入完成后,要把文件关闭,close(),括号别忘了。
把网页解析和txt文件写入,联合一下。
还是把这个URL上的内容写入txt文件,文件的全路径是D:\python\kunmingschool.txt。
http://api.map.baidu.com/place/v2/search?query=中学& bounds=24.390894,102.174112,26.548645,103.678942&page_size=20&page_num=0&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
这段的代码如下:
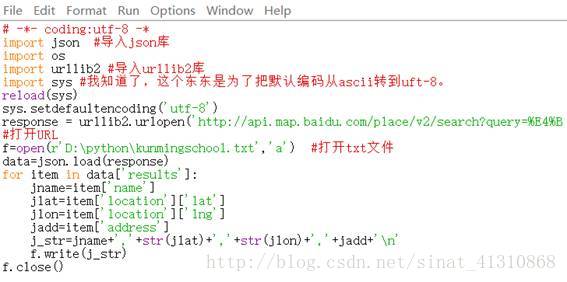
n\是python里面的换行符。
运行结果如下图:

至此,要用到的功能代码,我们都会了,现在只要把它们都组合到一切就可以了。
3.全部代码
# -*- coding:utf-8 -*
import json #导入json库
import os
import urllib2 #导入urllib2库
import sys #我知道了,这个东东是为了把默认编码从ascii转到uft-8。
reload(sys)
sys.setdefaultencoding('utf-8')
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942 #坐标范围
las=1 #给las一个值1
ak='9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO'
keyword='中学'
push=r'D:\python\12345.txt'
#我们把变量都放在前面,后面就不涉及到变量了,如果要爬取别的POI,修改这几个变量就可以了,不用改代码了。
f=open(push,'a')
lat_count=int((lat_2-lat_1)/las+1)
lon_count=int((lon_2-lon_1)/las+1)
for lat_c in range(0,lat_count):
lat_b1=lat_1+las*lat_c
for lon_c in range(0,lon_count):
lon_b1=lon_1+las*lon_c
for i in range(0,20):
page_num=str(i)
url='http://api.map.baidu.com/place/v2/search?query='keyword'& bounds='+str(lat_b1)+','+str(lon_b1)+','+str(lat_b1+las)+','+str(lon_b1+las)+'&page_size=20&page_num='+str(page_num)+'&output=json&ak='+ak
response = urllib2.urlopen(url2)
data=json.load(response)
for item in data['results']:
jname=item['name']
jlat=item['location']['lat']
jlon=item['location']['lng']
jadd=item['address']
j_str=jname+','+str(jlat)+','+str(jlon)+','+jadd+'\n'
f.write(j_str)
f.close()说实话,一个脚本里面嵌入了四个循环,程序员见了能打人,不过能用就行。
接下来将要进入进阶篇教程,在这里会涉及到如何获取区域范围,例如昆明市的bounds值;如何更合理的切分矩形;如何简化代码,如何将代码移植到python3中;可否用别的方式、函数语句获取poi数据;通过什么样的设置可以更高效的获取poi;python中文乱码的解决方式;request、time等模块的应用;过程参考资料汇总……