Python爬虫--爬取豆瓣图书信息
大三时的搜索引擎课程需要做爬虫实验,当时利用python爬取了豆瓣的图书链接。大四为了毕设图书推荐系统的图书信息,在爬取链接的基础再爬取出图书详细信息。本篇博客记录了我的第一爬虫程序的过程和一些心得体会。
一、爬虫的本质
网络爬虫通过程序去获取Web页面上的目标数据(文本、图片等)。本质是模拟浏览器打开网页,获取浏览器的数据。
二、爬虫基础
-
HTML
HTML是描述网页的超文本标记语言,利用类似的标签来识别内容。HTML在浏览器中以DOM形式表示为树形结构。图一为HTML源代码,图二为此源代码的DOM树结构。深入学习HTML,可以前往菜鸟教程学习有关内容。


-
Python语言
推荐廖雪峰老师的Python教程,小白的python新手教程,快速上门。
三、爬虫基本流程
-
发起目标链接(URL)请求:发起一个带有header、请求参数等信息的Request,等待服务器响应;
-
获取响应内容:服务器正常响应后,Response的内容即包含所有页面内容(可以是HTML、JSON字符串、二进制数据(图片、视频)等等)
-
解析数据:得到的内容可能是HTML,可以用正则表达式、页面解析库进行解析;提取出我们想要的数据。
-
保存数据:最后将数据保存到文档或者数据库内。
四、python爬虫库
爬虫有小爬和大爬之分,小爬就是利用爬虫库(BeautifulSoup库和Request库),大爬就是利用爬虫框架。 由于爬取的数据信息量不多,本文采用爬虫库。
1.Request库(用于http请求的库)
基于python自带的urllib库,但比urllib更方便。主要使用request.get(url,header)函数。url为图书信息网页链接,header构造请求头部。如果请求页面响应状态为200,代表成功,返回响应内容(即图书页面的html源代码)
import requests
send_headers = {
"Host": "book.douban.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Connection": "close"
}
response=requests.get('https://book.douban.com/subject/3259440/',headers=send_headers)
if response.status_code==200:
print( response.text)
2 .BeautifulSoup库(用于解析数据)
从HTML或XML文档中提出数据的Python库,比正则表达式re模块更快捷的提取html文档信息。可以去官方文档查看所有详细用法。我主要用到了find、find_all等用法。不同页面的解析方式不同,提取不同数据的方式也不同,要具体页面代码具体分析。以图书详情页面为例,我要提取出图片链接,先找到图片位置,利用find函数提取。
img=soup.find(class_=‘nbg’)[‘href’]

五、实践:爬取一个图书链接
图书详情页面的URL如下
https://book.douban.com/subject/3259440/
我们 传入一个图书详情页面的链接,提取出此图书的书名、图片链接、作者、ISBN、简介、豆瓣评分。
# -*- coding: UTF-8 -*-
import requests
import re
from bs4 import BeautifulSoup
#伪装成浏览器获取网页文本
#接受URL/返回网页文本
def get_html(url):
try:
send_headers = {
"Host": "book.douban.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
'Connection': 'close'
}
response=requests.get(url,headers=send_headers)
if response.status_code==200:
return response.text
except Exception as e:
print(e)
#利用bs4解析书本页面
#接受书本页面/返回书本信息
#get_text()是获取标签之间的文本
def get_bookdata(html):
book_data=[]
soup=BeautifulSoup(html,'lxml')
#提取书名
title=soup.find('h1').get_text(strip=True)
book_data.append(title)
#提取图片
img=soup.find(class_='nbg')['href']
book_data.append(img)
#提取主要内容以字符串形式
i=soup.find('div',id='info').get_text(strip=True)
#去掉空格
info=re.sub(r'\s+','',i)
#分组字符串,提取作者、ISBN
pattern=re.match(r'作者:(.*)出版社.*ISBN:(.*)',info)
book= pattern.groups()
book_data.extend(book)
related_info=soup.find('div',class_='related_info')
indentlist=related_info.find_all(attrs={'class':'indent'})
#提取简介
iro=indentlist[0].get_text('|',strip=True)
intro=re.sub(r'\s+','',iro)
book_data.append(intro)
#提取豆瓣评分
douban_score=soup.find(class_='ll rating_num').get_text(strip=True)
book_data.append(douban_score)
return book_data
#插入数据到文本文档中
def intofile(data,file):
file=open(file,'a',encoding='utf-8')
for i in data:
file.write(str(i))
file.write('\t')
file.write('\n')
file.close()
def main():
#根据图书url爬取书籍数据
u="https://book.douban.com/subject/3259440/"
book_data=[]
book_data=get_bookdata(get_html(u))
print(book_data)
intofile(book_data,'book.txt')
if __name__ =='__main__':
main()


六、实践:爬取多个图书链接(以小说类为例)
只爬取一本图书肯定不能满足我们的需求。我们需要得到一个图书链接集合爬取多本图书。
1.进入豆瓣图书的‘小说’类图书,会呈现所有小说类型的图书。
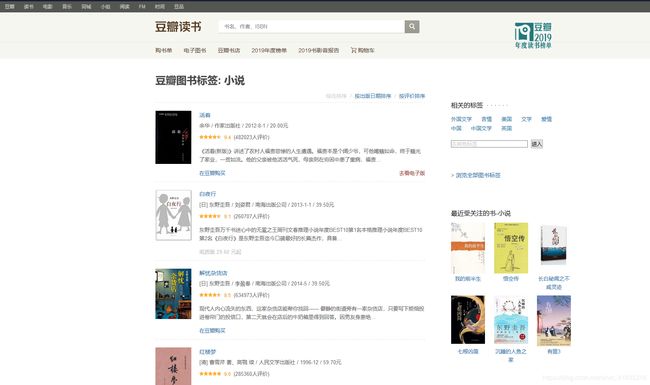
2.分析此页面源代码。利用bs4获取详细图书详情页面的URL
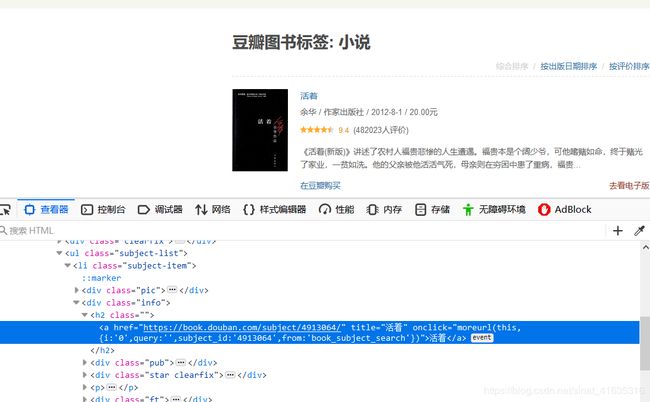 先找所有a标签,再利用正则式匹配符合图书详情页面的链接(https://book.douban.com/subject/xxxxxxxx/),实现代码为
先找所有a标签,再利用正则式匹配符合图书详情页面的链接(https://book.douban.com/subject/xxxxxxxx/),实现代码为
urllist=[]
#提取出图书的href属性
for x in soup.find_all('a'):
url=x['href']
if re.match(r'https://book.douban.com/subject/\d{8}/\Z',url):
urllist.append(url)
3.但一个主页面只有20本图书,只能提取20个图书详情链接

我们不停的翻页,页面URL的改变如下图所示。
https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=0&type=T
https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=20&type=T
https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=40&type=T
https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=60&type=T
可以看出页面有规律的变化(0,20,40,60…)以此为依据构造主页面,再从每个主页面得到图书详情页面链接
for a in [120,140,160,180] :
url = 'https://book.douban.com/tag/%E7%A7%91%E6%8A%80?start='+str(a)+'&type=T'
#注意:连续爬取多个链接页面时,可以设置爬取时间间隔(其实还有动态换ip、设置更复杂的header,但设置时间是最简单有效,虽有有点笨),否则对方会把你认为是恶意访问,在一段时间内禁止你再爬取此网站。
下面是爬取的全部代码
# -*- coding: UTF-8 -*-
import requests
import re
from bs4 import BeautifulSoup
import time
#伪装成浏览器获取网页文本
#接受URL/返回网页文本
def get_html(url):
try:
send_headers = {
"Host": "book.douban.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
'Connection': 'close'
}
response=requests.get(url,headers=send_headers)
if response.status_code==200:
return response.text
except Exception as e:
print(e)
#解析主页面提取链接属性
#接受主页面/返回书本链接
def get_bookurl(html):
soup=BeautifulSoup(html,'lxml')
print(soup)
urllist=[]
#提取出图书的href属性
for x in soup.find_all('a'):
url=x['href']
if re.match(r'https://book.douban.com/subject/\d{8}/\Z',url):
urllist.append(url)
urllist=urllist[: :2]
return urllist
#利用bs4解析书本页面
#接受书本页面/返回书本信息
#get_text()是获取标签之间的文本
def get_bookdata(html):
book_data=[]
soup=BeautifulSoup(html,'lxml')
#提取书名
title=soup.find('h1').get_text(strip=True)
book_data.append(title)
#提取图片
img=soup.find(class_='nbg')['href']
book_data.append(img)
#提取豆瓣评分
douban_score=soup.find(class_='ll rating_num').get_text(strip=True)
book_data.append(douban_score)
return book_data
#插入数据到文本文档中
def intofile(data,file):
file=open(file,'a',encoding='utf-8')
for i in data:
file.write(str(i))
file.write('\t')
file.write('\n')
file.close()
def main():
#第一步:构造出主页面的url,获得所有图书链接
book_url=[]
for a in [0,20,40,60,80] :
url = 'https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start='+str(a)+'&type=T'
book_url.extend(get_bookurl(get_html(url)))
#去除重复的链接
book_url=list(set(book_url))
print(book_url)
#第二步:根据图书链接爬取图书信息
book_data=[]
for u in book_url:
book_data=get_bookdata(get_html(u))
time.sleep(1) # 定义时间间隔
intofile(book_data,'book.txt')
if __name__ =='__main__':
main()

七、小结
1、对不同页面的爬虫不同分析,源代码不同,爬取的信息都位于不同HTML标签内
2、在解析数据时其实挺麻烦的,比如图书详情页面有的有总页数,有的没有,需要考虑到是否提取的信息在所有页面适用
3、在解析页面使用bs4库时可以选择最高效的方式找到信息所在的标签
4、经常爬取需要知道一些反爬虫的技巧了