深度学习笔记——理论与推导之Reinforcement Learning(十三)
Reinforcement Learning(强化学习)
Reinforcement Learning
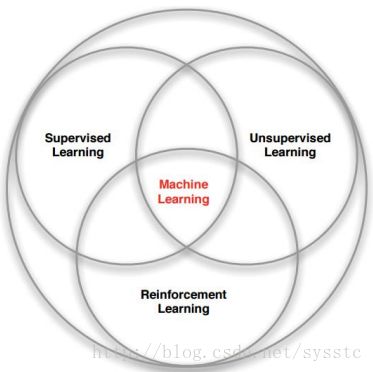
- 机器学习的分支:
有监督学习是机器学习任务的一种,它从有标记的训练数据中推导出预测函数。有标记的训练数据是指每个训练实例都包括输入和期望的输出。即:给定数据,预测标签。
无监督学习是机器学习任务的一种,它从无标记的训练数据中推断结论。最典型的无监督学习就是聚类分析,它可以在探索性数据分析阶段用于发现隐藏的模式或者对数据进行分组。即给定数据,寻找隐藏的结构。
强化学习是机器学习的另一个领域。它关注的是软件代理如何在一个环境中采取行动以便最大化某种累积的回报。即给定数据,学习如何选择一系列动作,以最大化长期收益。
- Reinforcement Learning有什么不同呢?
a) 它没有监督,只有一个收益信号。
b) 反馈会延时,而不是实时的。
c) 时序是非常重要的(比如顺序等)
d) 代理人的行为影响后续数据获得的信息 - Deep Reinforcement Learning:AI = DL+RL

Scenario of Reinforcement Learning(RL的场景):
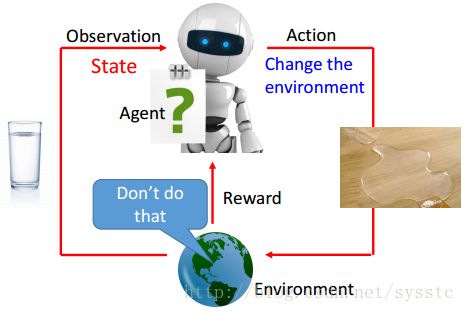
Agent与环境的互动,在与环境互动中,Agent会observation一些信息,也叫做State。接下来Machine会根据它看到的东西采取一些Action做一些事情,这些事情会对环境造成一些改变,环境就会给Agent的Reward(Postive Reward/Negtivate Reward),Agent就是尽量使自己得到的Reward最大化:
比如说一个机器人,端一杯水,这时候它把水打翻了(Action),得到一个“Don’t do that”(Negtivate Reward)。
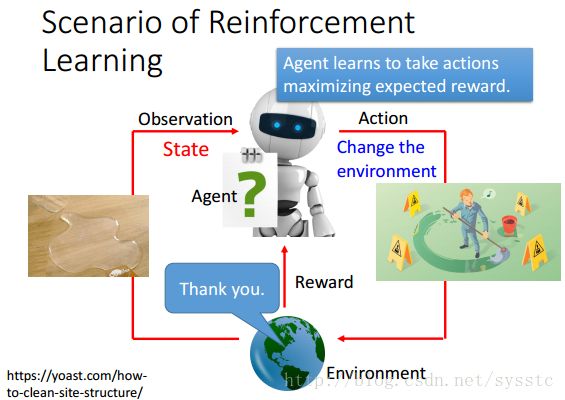
接下来这个Agent会采取行动使得获得的reward最大化,所以现在它就查了地板(Action),得到了一个”Thank you”(Postive Reward)。
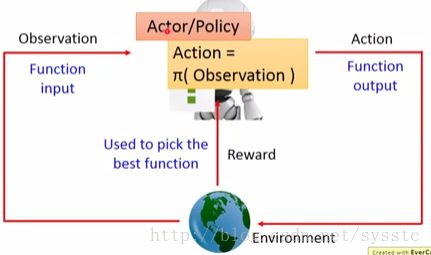
我们说过Machine Learning其实就是在找一个Function,而Reinforcement Learning也是在找一个function,我们把这个function称为Action = π(Observation),它的输入是一个Observation,输出是一个Action,也就是Agent要采取的动作(也叫做Actor/Policy)。我们如何pick the best funtion呢?即根据现在环境给我们的reward去找出一个function,可以让machine得到的reward最大。
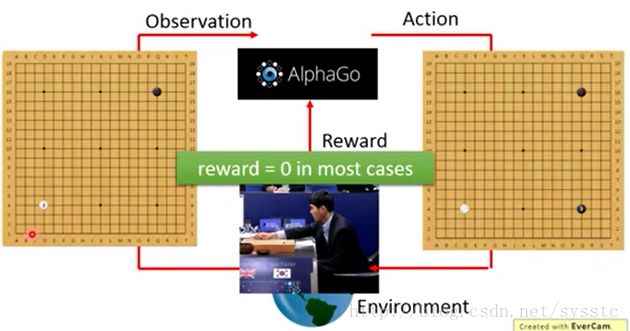
那么AlphaGo是怎么下围棋的呢?
首先在下围棋时,AlphaGo会先观察这个棋盘,然后他将棋子下在(3,3)的位置:

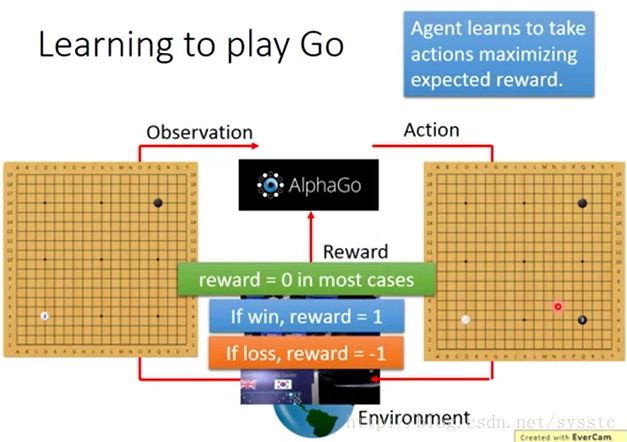
接下来,它的对手会放入另外一个白子,也就是Agent的Observation变了。这也就促使它做了另外一个Action,这个过程会反复不断的继续下去,通常情况下它得到的Reward是0,棋盘获胜时,reward=1,棋盘输时reward=-1:
- Supervised vs Reinforcement Learning:
- Supervised看到棋盘是情况A时,人类会下5*5,所以知道要走5-5,看到棋盘是情况B时,知道人类会下3 * 3,所以他以后也会下3-3。是Learing from teacher。
- Reinforcement Learning:让Machine和某个人下棋,最后赢了他就知道这么下是好的。如果输了,他就知道这么下不好,但他也不知道那一步不好。RL是Learning fromexperience
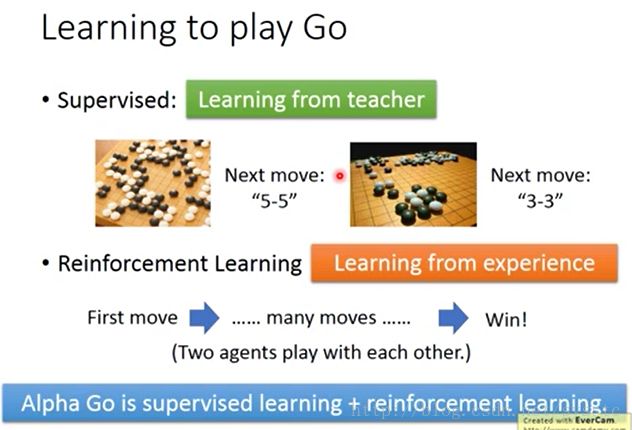
如果AlphaGo只用Reinforcement Learning去learn可能永远学不起来,只有经过Supervised Learning先和棋谱学习一段时间再用RL。
那么chat-bot也是一样的:
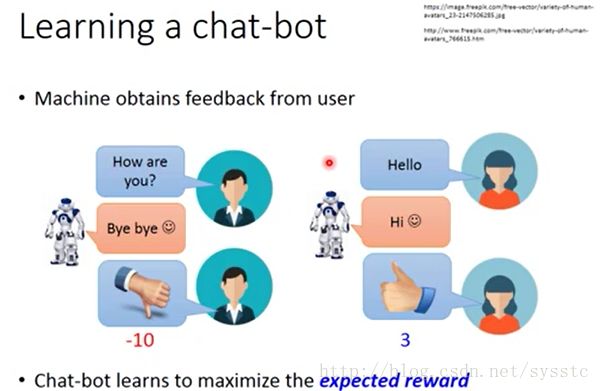
那么如何让chat-bot聊天呢?
我们可以定义两个agent让它们互聊:

互聊后就会得到好多条记录,接下来你就可以定义一个rule去评估这些dialogue的好坏:

总结:
Supervised:每一个都chat-bot有正确答案。
Reinforcement:如果得到负反馈说明之前没有讲好,如果得到正反馈说明之前讲好了。
- RL有很多其他的应用:

- Example:Playing Video Game

- Space invader:
结果就只有两种:一是所有外星人都会被杀掉,二是你的spaceship会被毁坏。


游戏开始的时候:
首先观察s1,Agency做出一个Action a1表示向右移动,因为它并没有杀掉外星人,所以它的reward = 0,接下来它会观察到新的画面(Observation s2),在此基础上,Agency做出一个Action a2表示开火,因为它杀掉了一个外星人,所以会获得一个reward = 5。

互动很多回合后,当spaceship被destroy后游戏就结束了:

Agency要做的就是采取某些行动使得reward得到最大值。
- Space invader:
- Reinforcement Learning的两个重要的特性(这两个特性也使得RL产生很大的挑战):
- Reward delay:有时候采取一个Action,可能在短时间内看不到任何的reward,而在长时间内可以得到reward。比如说:在space invader中,只有”fire”才会获得reward,而在之前的”right”or”left”中并不能获得到reward。或者在某些游戏中,我们可能会牺牲当前的利益去换取长期的利益。
- Agent的actions会影响往后所观察到的oberservation,RL的training data是来源于Agent和环境的互动。

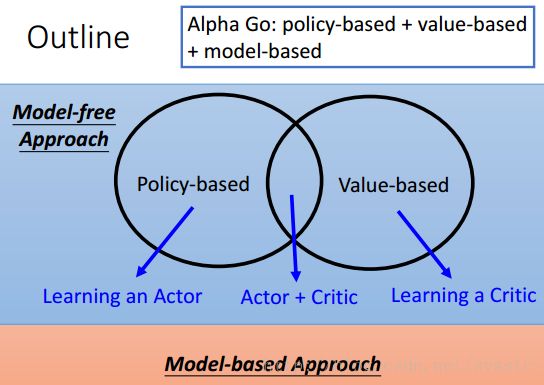
Outline
Model-free Approach
Model-free Approach:不需要对环境做理解,Machine对环境的理解是隐藏的,它并没有个模型去描述环境。Model-free Approach就是看到现在的Observation直接做出Action。
Model-free Approach又可以分成两大类:一类是Policy-based,一类是Value-based。在Policy-based中我们可以Learn一个Actor;在Value-based中我们可以learn一个Critic,这个Critic可以反推出一个Actor。
Policy-based Approach(Learning an Actor)
- 从DL入手的3 steps:
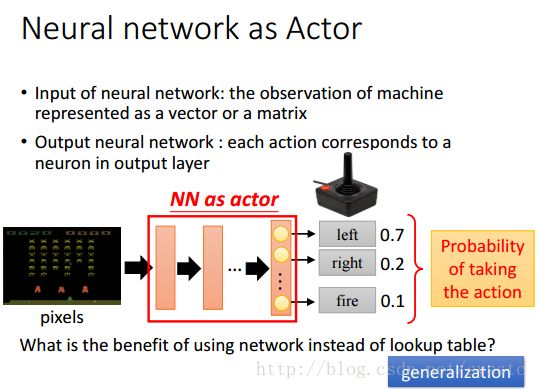
- Find a function:RL很火的一部分原因就是我们把原来要找的function用NN来表示,那么用NN来表示function有什么好处呢?它这真正的好处就是generalization,即Machine不需要看过所有的input才知道应该如何output。

NN as Actor:
输入一些pixels,通过NN,输出一个vector,每一个dimension代表采取这个行动的可能性。
- goodness of function:
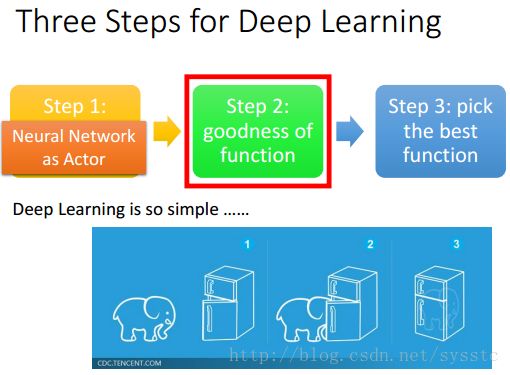
如何评估这function的好坏呢?
- Review:Supervised Learning
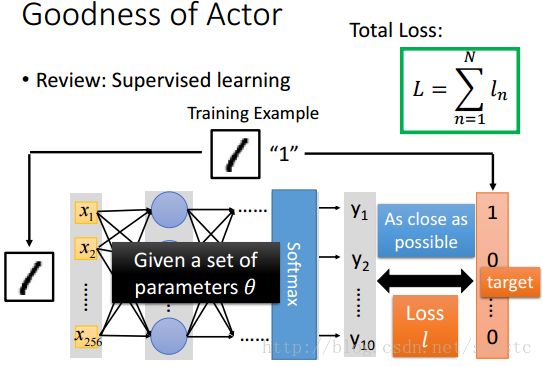
- Goodness of Actor:用这actor去玩这个游戏,计算total reward。注意:因为环境是random的,所以相同的actor玩同一个游戏也未必会得到同一个reward,并且actor也是有随机性的,我们看到Actor得到的output是一个distribution,所以就算是在同样的情景,Actor的回应也是具备随机性的。因为actor玩同一个游戏每一次的结果都可能不一样,所以我们计算reward是要求计算很多次游戏的reward,然后再计算reward的期望值。所以这个期望值就可以衡量actor π有多好。

那么这个期望值应该怎么计算呢?
首先,τ的产生是基于actor的,s1表示的是agency观察到的state,是环境给的;a1是agency采取的action;r1是环境给actor的reward。那么如何看待一个actor(或者说一个actor的参数θ)产生τ的几率呢?首先就计算P(τ|θ) = P(s1)P(a1|s1,θ)P(r1,s2|s1,a1)P(a2|s2,θ)P(r2,s3|s2,a2)……
因为s1是环境随机产生的,s1和θ得到动作a1,a1和s1得到反馈r1和下一个环境s2,以此类推。
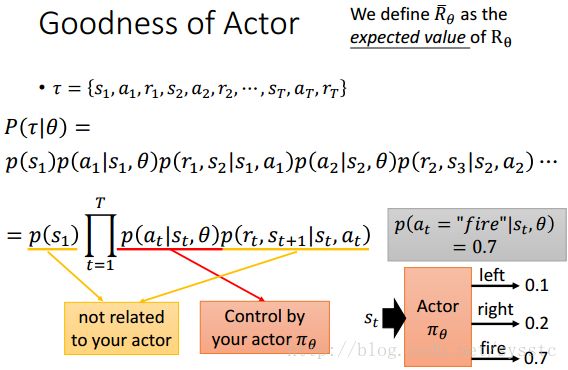
接下来,我们就可以估算reward,那么reward的期望值怎么计算呢?穷举是不可能的,所以我们使用actor πθ玩N次游戏,获得{τ1,τ2,τ3……τN}。

- Review:Supervised Learning
- pick the best function
Gradient Ascent:
- Problem statement:

- 如何计算Policy Gradient:
我们之前可以把summation over τ换成sample是因为summation中有P(τ|θ)这一项,你看到summation over τ和P(τ|θ)就可以换成sample,而现在变成了▽P(τ|θ),已经没有P(τ|θ)了,所以就不能替换。我们现在说的策略是Policy Gradient,我们说没有P(τ|θ)所以我们可以创造一个P(τ|θ)。

如何计算▽log[P(τ|θ)]?

接下来我们就可以化出下面公式:
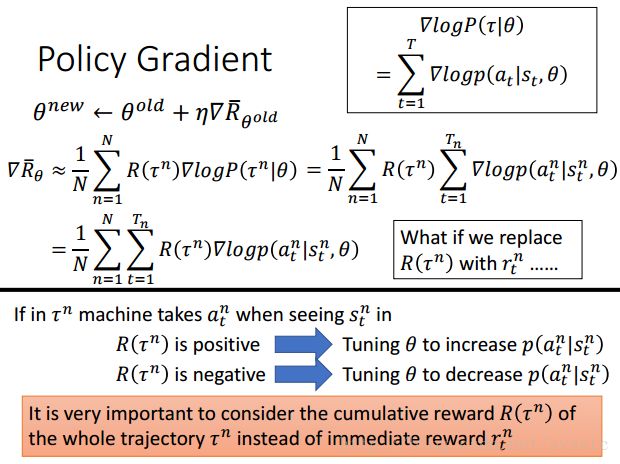
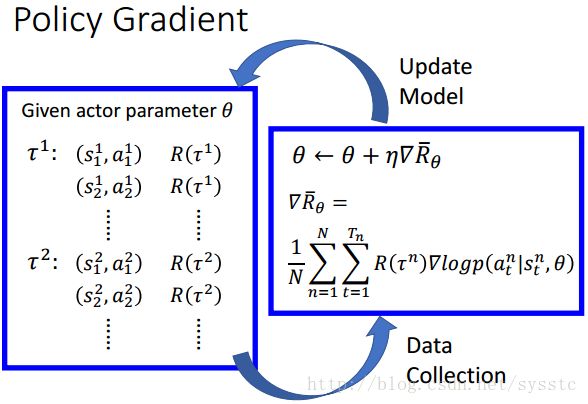
我们让machine和环境互动N次,得到N个轨道(trajectory,即我们说的τ),每个trajectory都有Tn个state,在每个state st^n 上machine采取了at^n,我们计算几率求log再取gradient,再把前面乘上R(τ^n)。它的物理含义就是:在τ^n的trajectory中state st^n上machine采取at^n这个action,如果R(τ^n)是正的,那么machine就会增加在这个state采取这个action的几率。
注意:R(τ^n)必须是整个trajectory的reward的和。如果把R(τ^n)换成rτ^n那么machine就只会考虑当下的reward,比如说fire才会有reward,但是right or left就没有reward,就会导致machine一直在fire,而不right or left。
- Policy Gradient实际应用:
首先random parameter θ,再用这个θ去玩n次游戏后就会得到n个trajectory,接下来你可以拿这些数据去update你的参数θ,再用新的θ去玩新的游戏:
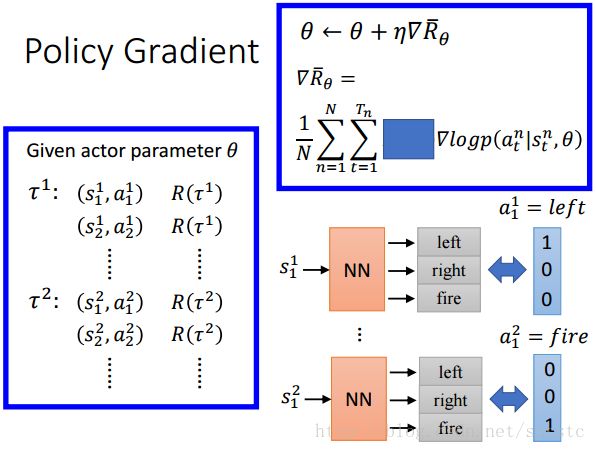
如果我们把由State推出action这个看成是一个分类问题(分为3类),那么我们知道我们应该最小化的是一个交叉熵,那么由于我们需要得到的正确答案是yi = left,并且我们找到logyi = logP(“left”|s),因此我们可以把这个gradient ascend 方程变成下图这种(因为其他的也都是真实值都是0):

现在我们这么看,假设Reward都等于1,输入一个state,经过NN后输出action,这样看起来好像有点类似分类问题了:
但由于gradient中还有一项reward,所以它和普通的NN并不同。就相当于给每一笔training data都乘上R(τ^n)。那这么做是什么意思呢?如下图,假设R(τ^1) = 2,那么相当于给(s1^1,a1^1)乘以2倍。这样做其实就很简单,就相当于我们只需要修改weight的地方(即赋上Reward)。
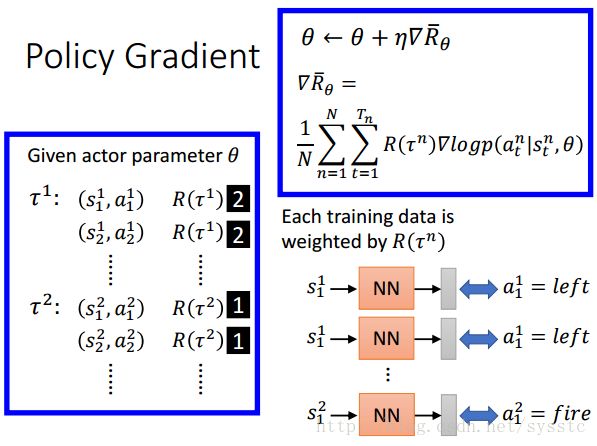
RL和NN在train的时候不一样的地方就是:NN只需要整理好training data就可以直接做NN了,而RL在收集好第一笔data后都要解一次分类问题去train一次NN,然后再收集好一笔data在train一次NN,以此类推。 - Baseline:如果所有的reward都是正的那么会有一定问题:
- 在理想情况下是没什么问题的,假设state状态下,有三个action:a,b,c,它们的reward都是positive,那么由于c的reward比较大,b的reward比较小,所以c可能提高的比较多,那么由于最后会通过一个softmax,所以就相当于c和a被增加了,b被减小了。
- 然而我们其实并不是处于理想状态下,因为我们做的是sample操作,假设state状态下有三个action:a,b,c,除了a,b和c都被sample到了,那么由于a没被sample到,也就相当于其的reward = 0,而其他reward>0,因此not sample的action就变成了最差的。
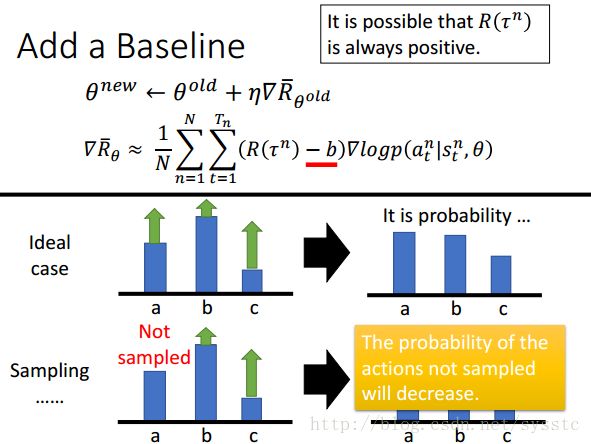
所以一般情况下我们可以在Reward后面减去一个baseline(这个baseline可以由自己定义),这样可以控制reward,让它们不要都大于0。
- Policy Gradient实际应用:
- Problem statement:
- Find a function:RL很火的一部分原因就是我们把原来要找的function用NN来表示,那么用NN来表示function有什么好处呢?它这真正的好处就是generalization,即Machine不需要看过所有的input才知道应该如何output。
Value-based Approach(Learning an Critic)
- Critic:并不真的决定action,只是用来评估actor有多好或者多不好。可以从critic function去推出一个actor,比如说Q-learning。

- State value function V^π(s):input的是一个state,output是一个reward的总和(从state开始到最后的),value function,depend on actor,即不同的actor在同一个state接下来会得到的reward也会不一样,因为不同的actor做的事情不一样,到游戏结束的,total reward也会不一样。下面的V^π要标记为π,代表的是我们evaluate的actor是π。最后的output会是一个scalar,如果今天actor比较强,那么output就比较大,如下:
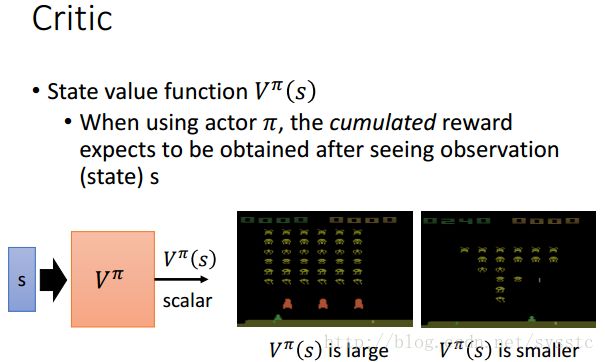
举个小栗子:

- 如何estimate V^π(s)呢?
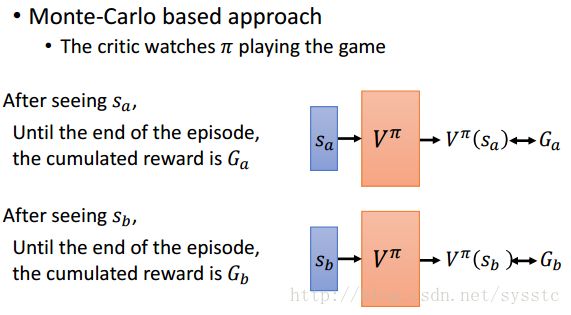
- Monte-Carlo based approach:
- 观察我们要evaluate的那个actor玩游戏
- 我们发现这个actor在看到state sa后,它在整场游戏结束后得到的reward是Ga,如下:
- Temporal-difference approach:
- 假设我们只观察到互动的其中一部分:….st,at,rt,st+1…接下来我们会这么learn:我们希望他们的差值和rt越接近越好。
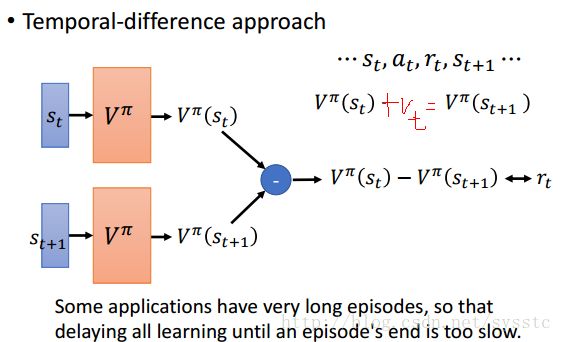
- 假设我们只观察到互动的其中一部分:….st,at,rt,st+1…接下来我们会这么learn:我们希望他们的差值和rt越接近越好。
- MC vs TD:
- MC:我们Sample到的Ga,我们观察到actor在某个state后得到的reward的总和,它是V^π的unbiased的estimation,也就是说如果今天machine可以重复走到某个state sa很多很多次,我们每次都去衡量他的Ga,但每次衡量出的结果都不一定一样,因为machine的环境都有他的随机性,但是我们把每次我们衡量出的结果都做平均,它是unbiased estimate V^π,但是它的variance是比较大的,因为Ga是好多个timestep的reward的总和,每个timestep都有随机性,所以总和就有很大的随机性。
- TD:TD的特性和MC相反,因为TD的target的r,r是某个step得到的reward,所以r相较于Ga得到的variance比较小。
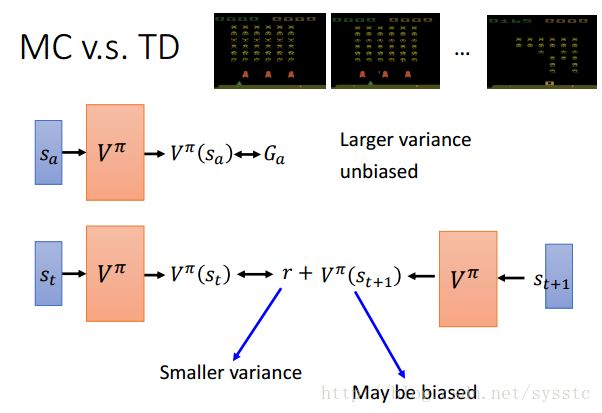
举个栗子:
有下面有8个序列,我们发现通过MC和TD计算sb,V^π(sb) = 3/4;那么针对sa呢?对于MC,因为sa只sample到一次,并且reward的总和是0,所以V^π(sa) = 0,对于TD,因为V^π(sb) + r = V^π(sa)而V^π(sb) = 3/4,所以V^π(sa) = 3/4。解释上来说,当V^π(sa) = 3/4,可以解释成sample的数据太少,而V^π(sa) = 0可以解释为如果前面遇到sa,后面的sb的reward就会等于0。两者的解释都是合理的。

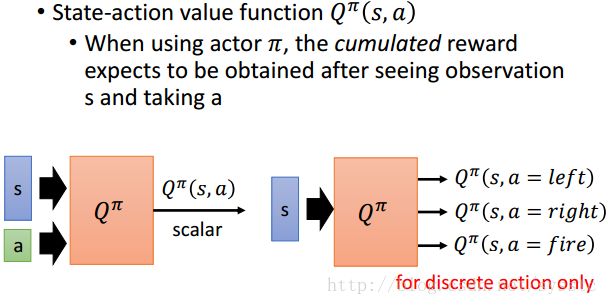
- Another Critic:State-action value function Q^π(s,a):输入的是state和action,输出的是reward。我们常见的是右手边的这种,输入s,输出的是离散的几个action得到reward。
- Monte-Carlo based approach:
Q-Learning
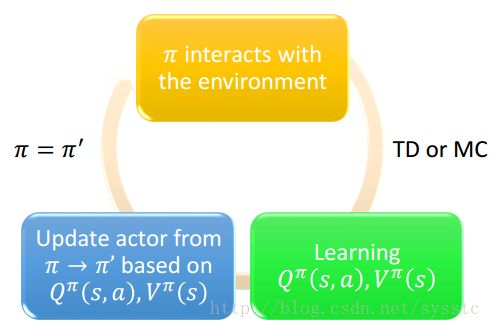
π和环境多次互动后,通过TD or MC得到Q^π(s,a),得到Q function后可以得到一个新的更好的π’。
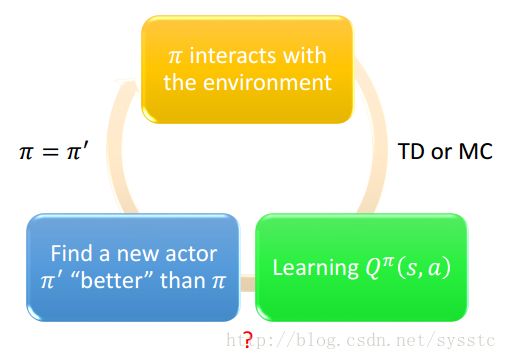
这个π’不一定要存在,它其实就是state下会采用最好的那个action的actor,当然它无法处理连续的action,它只能处理action可数的情况。

Model-based Approach
Model-based Approach:可以对环境建模,这就需要Machine对环境有一定理解。可以推论接下来会发生的事情,直接对未来做预测。这种方法并不是都适用的,因为你需要machine直接去预测接下来会发生的事情,machine必须对环境有比较深刻的理解。因此Model-based可能说在下围棋的时候是有些用处的,而在做video game的时候就没什么用处了。
Deep Reinforcement Learning(Actor-Critic)
Actor-Critic
actor π与环境互动多次后,通过TD or MC,可以得到Q function和V function,通过Q和V,得到一个π,这个就可以处理连续的action。