##haohaohao#######蘑菇街自研服务框架如何提升在线推理效率?
Online Serving 简介
从本质而言,在线服务就是提供 (http, rpc) 等接口,用户输入 X, X 经过 pre-process 处理成符合模型输入的参数,经由模型推理后得到 Y,Y 经过 post-process 处理成符合用户认知的数据格式,最后将结果返回。
第 2 步和训练中的 evalute/test 相应步骤几乎一样,只是在线推理下的 batch size 往往为 1,远远小于训练过程中的 batch size,故在线推理下的显卡和显存的利用率相对训练更低。
1. X = pre_process(X)
2. Y = model.predict(X)
3. Y = post_process(Y)
以 mnist 为例,其模型输入为 28 * 28 的图片,模型输出为 1 * 10 的向量。从用户体验角度来看,客户端更期望的输入是一张图片的 URL,返回结果是预测的数字,相比 10 维向量,数字更符合人类的认知。所以从易用性出发,在线服务不仅需要预测模块 (2),还需要预处理 (1) 和后处理模块 (3),方能为用户提供友好的服务。很遗憾的是,当前大部分开源的在线服务框架或者云服务,仅仅提供了模型预测功能。
开源的 Online Serving 现状
纵观业界,开源的在线服务项目可谓形态灵活、百花齐放,但也呈现出微服务化、容器化部署的特点,本节选择几个具备代表性的开源项目进行分析。
Tensorflow
TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments.
正如官网所述,基于 C++ 编写的 Tensorflow Serving 注定是一个高性能的在线服务系统框架,它支持 Tensorflow,Pytorch 等深度学习框架训练导出的模型 (通常基于 ONNX 完成模型转换),而且部署非常方便,支持多个版本的模型,详细的例子请见官网。特别在结合 K8S + Docker,完美的解决了资源管理和调度、服务弹性部署、服务发现等痛点,从而对外提供稳定可靠的服务。
Tensorflow Serving 的缺点也很明显,正如本文第一节所讲,它缺乏预处理和后处理相关的逻辑,所以影响用户体验,这点由官网样例也能看出来,用户需要关注调用 API 时传入的数据及其维度和格式,解析 protobuf 等等。另外一个痛点是 Tensorflow 对其它深度学习框架生成的模型不够友好,比如卷积和池化时的 padding 参数,不同的深度学习框架的存在差异,例如博文 Running Pytorch models in Tensorflow。
Pytorch
对于 Pytorch 的 Online Serving,社区并没有提供相关的框架,仅在官网文档 model-serving-in-pyorch 给出了一个概述,为不同场景下的 Online Serving 介绍了一些可行性的方案。
- 云化场景:基于 AWS Sagemaker、Azure Machine Learning 等公有云服务进行部署。
- 本地场景:采用 flask 构建自己的微服务进行部署,例如 Deploy your PyTorch model to Production。
- 开源 Model Server:如 Kubeflow 中的 KFServing 等等,详情请见下文。
KFServing
KFServing 是 Kubeflow 的子项目,旨在 Kubernetes 的基础上提供 Serverless 的在线推理服务,它支持多种机器学习框架,具备弹性伸缩、服务治理、A/B Test、金丝雀发布等重要功能,允许用户扩展 pre-processing、post-processing 逻辑,从而对外提供完整易用的服务,它主要有两部分组成:
- KFServing Controller:基于 K8S 定义了在线推理服务相关资源 K8S CRD(Custom Resource Definition) 和生命周期管理 API,这部分主要为 golang 代码。
- Model Server: 基于 tornado 提供了一套 Restful Web 框架,支持 Tensorflow、Pytorch 等深度学习框架,这部分为 Python 代码。

如上图所示,KFServing 的弱点也很明显,深度依赖 Knative、Istio 等模块,这些模块比较复杂,且稳定性有待商榷,其次 200+Stars 的 KFServing 的成熟度亦欠佳。但长远来看,待 Knative、Istio 稳定和普及后,KFServing 或将释放更大能力。
蘑菇街 Online Serving 实践
蘑菇街计算视觉有大几十个在线服务 (模型),其中不少运行在 GPU 容器上,每个服务的业务代码通常在数百行以内,依赖 Pytorch、Tensorflow 和 Openvino 等框架完成推理。因此,建设一个易用、支持多深度学习框架、支持异构计算的统一在线服务,将大大提升效率和降低维护成本。
基本需求
易用性主要体现在两方面,一方面是对客户端要提供简单易用的 API,即 HTTP Restful API,由于公司所有图片均存储在对象存储上,故用户只需要在 body 中提供图片的 URL 即可,图片的下载和解析在服务端完成;另外一方面是在线服务模块对算法同学要简单易用,以便快速迭代上线。
此外,在线服务模块不仅需要支持 Tensorflow、Pytorch 和 Openvino 等深度学习框架,还需要同时支持 GPU 和 CPU 计算资源。Batch size 为 1 下的推理无法充分利用 GPU 资源,我们通过单卡运行多个服务以提升 GPU 资源利用率。
最后,支持弹性部署、完善的业务层面的监控和服务发现等功能也非常重要。
技术选型和实现
本节介绍蘑菇街计算视觉在线推理的实践,包括技术选型、架构和一些经验等。
语言和 Web 框架
Java 是公司的"标准"语言,几乎所有的基础技术体系均是基于 Java 建设。但是在机器学习领域,Python 有着无可比拟的丰富的生态,包括主流的深度学习框架和大量的图像数学库。采用 Java 实现在线推理通常碰到对应库和函数缺失的情况,甚至导致准确性下降的问题。其次 Java 并非算法同学常用的语言,导致经常需要工程同学协助实现对应的逻辑,带来大量的沟通成本,影响上线效率。虽然 Java 性能较 Python 高,但权衡准确性和效率等因素,Python 是更好的选择。
现在分析 Python 下的并发方式,主要从进程、线程和协程择优用之。由于 CUDA 对多进程支持不够成熟,容易出现耗尽显存等异常情况,故排除多进程;受 GIL(Global Interpreter Lock) 锁的限制,线程的性能要低于协程,故最终采用高效和成熟的 Gevent 协程库提供并发,选择简单易用的 Flask 作为 WSGI Web 框架,对外提供 Restful API。
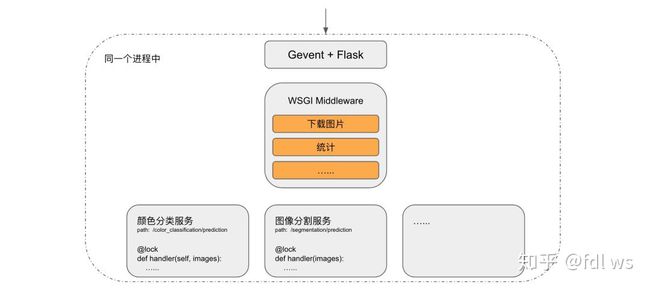
为了进一步提升易用性,可将下载图片、统计等通用功能放置在 WSGI 的 Middleware 中。每当新增一个在线服务,只需增加一个继承基础类的新类,并在新类中实现 load 和 handler 两个方法即可。其中 load 方法仅在服务启动时执行一次,用于完成下载和加载模型、创建 session 等初始化工作;handler 方法实现具体的业务逻辑,通常包含预处理、预测和后处理三个步骤,每当一个请求到来,启动一个协程执行对应在线服务的 handler 方法,并将结果返回给客户端。通过给每个 handler 方法加上各自的互斥锁,使得同一个服务只能串行执行,以避免相同服务并行带来的可能的 GPU 异常,但是不同服务之间可并行执行。
容器化部署
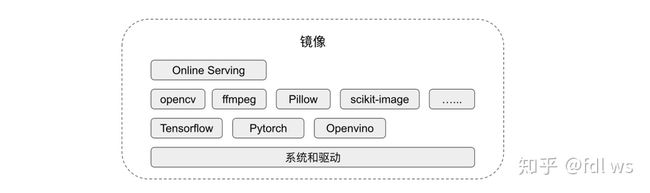
我们采用容器化部署在线服务,针对 CPU 和 GPU 异构资源制作了对应的两个镜像。以 GPU 场景为例,所有服务所依赖的深度学习框架库、图像库、数学库和 GPU 驱动相关已在镜像中安装,虽然这个镜像高达十几个 GB,但是便于使用,特别是算法同学新增一个模型时,极少会碰到库缺失的情况。在线推理的逻辑较训练相比简单许多,对各种库的版本要求比较宽松,通常只需一个版本的镜像即可满足所有 GPU 在线服务的依赖要求。
K8S 不支持显卡虚拟化,且业内暂无开源的解决方案,只能为每个 GPU 容器分配一张真实的显卡,每个容器运行一个在线服务进程,它支持加载多个服务 (模型),其中服务的数量由模型大小和显存大小决定。通常而言,在线推理的显卡,如 P4 通常为 8GB,计算视觉的模型大小普遍在小几百 MB,一张 8G 的 P4 GPU 可加载十几个服务,且不同服务之间可以并行执行,故 GPU 资源可以得到较为充分的利用,使用率可达到 40%,单卡能支持几十 QPS。
借助 K8S 的 StatefulSet,进一步简化部署和弹性扩缩,同时提升可靠性。
架构
每当在线推理的容器启动时,它根据环境变量决定加载哪些服务 (模型),依次从模型管理中心下载和加载模型,完成初始化工作后再注册路由和 API,最后成功启动的服务注册到注册中心。客户端根据服务名称从注册中心获取 IP 信息,然后访问对应的服务。Middleware 的统计模块会采集 QPS 等数据,并上报到监控中心。
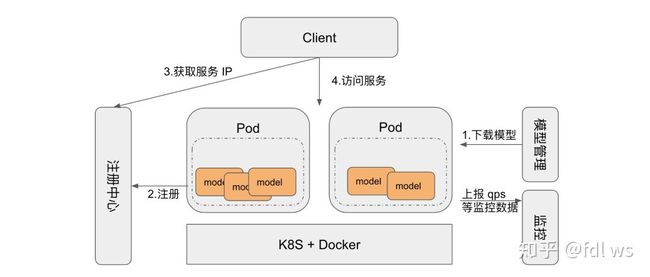
模型管理主要用于存储和管理模型,常用的存储媒介有对象存储、HDFS 等,蘑菇街采用 HDFS 作为模型的存储中心。监控模块因不同公司而异,通常的做法是通过 Kafka 或者监控服务的 API 上传统计数据。注册中心主要用于服务发现,Zookeeper 或 Redis 是常用的方案。我们之所以需要注册中心,是因为有大几十个服务 (模型),同时单个 pod 加载多个服务并且这些服务经常增删,所以 K8S 原生的服务发现功能无法满足需求。但是如果您的服务数量少或者极少变更,那么采用 K8S 的服务发现即可,甚至可部署在虚拟机上,不需要注册中心。
为了提升性能,可以在多个层次增加 Cache。对于业务存在周期性调用的服务,可以将结果缓存在 Redis;计算视觉通常依赖多个在线服务完成一件事情,比如搭配购业务,它需要依次调用目标检测、服装粗分类和服装细分类的服务,将图片缓存在内存可在一定概率上避免重复下载,降低 RTT。对于视频类服务,由于视频较大,可以采用本地磁盘缓存视频和拆帧后的图片。
注意事项
在单卡支持运行多个服务 (模型) 时,主要遇到两个问题:
- 同一个 GPU 上运行同时不同框架的服务时,例如 Tensorflow 和 Pytorch,容易造成异常,故同一个 Pod 只能加载相同框架的服务。
- 同一个进程下 Tensorflow 的 config.gpu_options.per_process_gpu_memory_fraction 仅在第一次初始化 session 时生效,为了避免该值设置过小引起异常,建议 TF Pod 下的所有服务的参数均设置为 0.95。
作者简介
- 范德良,花名揽胜,蘑菇街技术专家,在 IaaS、PaaS 和机器学习工程领域具有丰富经验。
- 杨立,花名浮尘,蘑菇街智能投放平台小组负责人,深度参与了蘑菇街算法在线服务体系 0 到 1 的建设,主导了搜索推荐链路算法相关核心系统平台的建设与持续演进。