Binder机制原理学习笔记(2)_Binder一次Copy原理
因为Android是基于Linux系统内核的,所以在学习Binder一次拷贝原理之前必须先学习一下Linux操作系统的基本知识。
用户空间和内核空间
- linux系统运行模式分为两层:高优先级模式(特权模式),低优先级模式(普通模式)。在 CPU 的所有指令中,有些指令是非常危险的,如果错用,将导致系统崩溃,比如清内存、设置时钟等。如果允许所有的程序都可以使用这些指令,那么系统崩溃的概率将大大增加。所以,CPU 将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通应用程序只能使用那些不会造成灾难的指令。
- linux系统在高优先级模式中运行系统内核代码以及与硬件密切相关的代码。 低优先级运行营运程序与硬件无关部分。应用程序不能直接操控硬件或者调用内核函数,需借助一系列接口函数申请让系统调用相关代码在内核空间运行,获取代码运行权限。
- Linux 操作系统和驱动程序运行在内核空间,应用程序运行在用户空间。每一个系统进程都拥有自己私有的地址空间和数据,用户空间造成的进程错误会被局部化,而不会影响到内核或者其他进程。每个应用程序或者进程都会有自己特定的地址、私有数据空间,程序之间一般不会相互影响。
内核态与用户态:当进程运行在内核空间时就处于内核态,而进程运行在用户空间时则处于用户态。
在内核态下,进程运行在内核地址空间中,此时 CPU 可以执行任何指令。运行的代码也不受任何的限制,可以自由地访问任何有效地址,也可以直接进行端口的访问。在用户态下,进程运行在用户地址空间中,被执行的代码要受到 CPU 的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中 I/O 许可位图(I/O Permission Bitmap)中规定的可访问端口进行直接访问。
内核地址空间划分
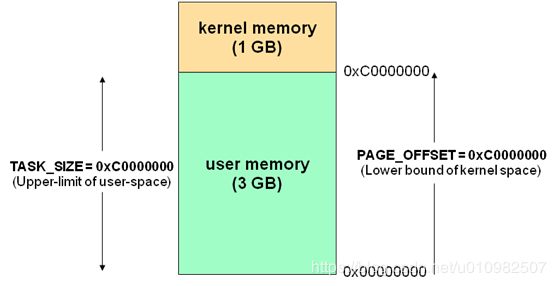
一、32位Linux系统虚拟地址空间
32位Linux内核虚拟地址空间划分0-3G为用户空间,3~4G为内核空间(注意,内核可以使用的线性地址只有1G)。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的(64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存)。如下图所示:用户空间内存分为3G,内核空间内存分为1G。
二、逻辑内存地址与物理内存映射(内存条物理地址)
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射;
假如内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0×0 ~ 0×40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核的地址空间已经全部映射到物理内存地址范围0×0 ~ 0×40000000。
三、Linux内核高端内存
上面提到了内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,所以不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域(从3G~4G计算)如下:
ZONE_DMA: 内存开始的16MBZONE_NORMAL:16MB~896MB,880MZONE_HIGHMEM:896MB ~ 结束(1G),128M

高端内存HIGH_MEM地址空间范围为 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。
所以高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,从而访问所有物理内存。
四、Linux内核高端内存的划分
内核将高端内存划分为3部分:VMALLOC_START ~ VMALLOC_END、KMAP_BASE ~ FIXADDR_START 和 FIXADDR_START ~ 4G。
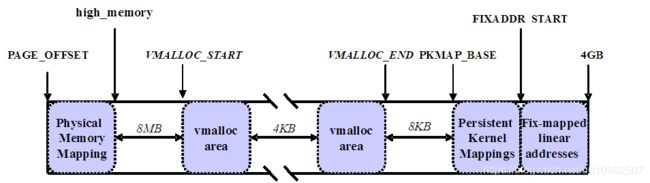
对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行,也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
-
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。 -
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。 -
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
原文:https://blog.csdn.net/tommy_wxie/article/details/17122923/
用户空间与内核空间交互
一、用户空间与内核空间是如何交互的?
所有的系统资源管理都是在内核空间中完成的。比如读写磁盘文件,分配回收内存,从网络接口读写数据等等。应用程序是无法直接进行这样的操作的。但是可以通过内核提供的接口来完成这样的任务。
比如应用程序要读取磁盘上的一个文件,它可以向内核发起一个 “系统调用” 告诉内核:“我要读取磁盘上的某某文件”。其实就是通过一个特殊的指令让进程从用户态进入到内核态(到了内核空间),在内核空间中,CPU 可以执行任何的指令,当然也包括从磁盘上读取数据。具体过程是先把数据读取到内核空间中,然后再把数据拷贝到用户空间并从内核态切换到用户态。此时应用程序已经从系统调用中返回并且拿到了想要的数据。

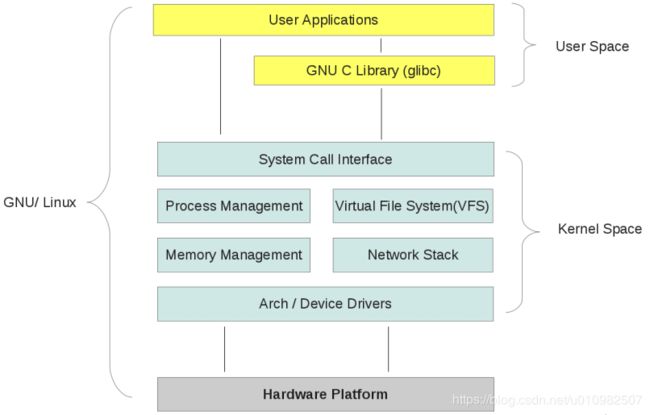
二、从内核空间和用户空间的角度看一看整个 Linux 系统的结构
它大体可以分为三个部分,从下往上依次为:硬件 -> 内核空间 -> 用户空间。如下图所示:用户空间在硬件之上,内核空间中的代码控制了硬件资源的使用权,用户空间中的代码只有通过内核暴露的系统调用接口(System Call Interface)才能使用到系统中的硬件资源。
原文:https://www.cnblogs.com/sparkdev/p/8410350.html
Binder一次拷贝原理
一、常规进程间通信(两次Copy)
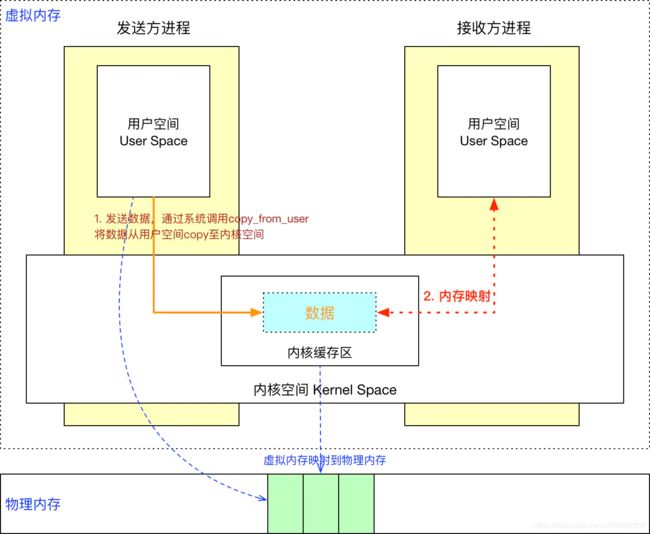
Linux中两个进程之间是相互隔离,无法之间通信,需要通过内核空间进行传输数据。通常的做法是消息发送方将要发送的数据存放在内存缓存区中,通过系统调用进入内核态。然后内核程序在内核空间分配内存,开辟一块内核缓存区,调用 copy_from_user() 函数将数据从用户空间的内存缓存区拷贝到内核空间的内核缓存区中。同样的,接收方进程在接收数据时在自己的用户空间开辟一块内存缓存区,然后内核程序调用 copy_to_user() 函数将数据从内核缓存区拷贝到接收进程的内存缓存区。这样数据发送方进程和数据接收方进程就完成了一次数据传输,我们称完成了一次进程间通信,其中经过了两次数据Copy。

而Binder方式的IPC,首先也是需要把发送方的数据从用户空间拷贝到内核空间,但是后面,Binder驱动程序在内核空间的虚拟内存地址和接收方的虚拟内存地之间做了一个映射,这样接收方就可以直接去读取这个地址上的数据了,减少了一次拷贝。
原文:https://ke.qq.com/user/index/index.html#/plan/cid=2203778&term_id=102306334
二、 Binder一次拷贝原理-mmap
1、Binder 是基于 C/S 架构的。由一系列的组件组成,包括 Client、Server、ServiceManager、Binder 驱动。其中 Client、Server、Service Manager 运行在用户空间,Binder 驱动运行在内核空间。其中 Service Manager 和 Binder 驱动由系统提供,而 Client、Server 由应用程序来实现。Client、Server 和 ServiceManager 均是通过系统调用函数 open、mmap 和 ioctl 来访问设备文件 /dev/binder,从而实现与 Binder 驱动的交互来间接的实现跨进程通信。其中mmap在其中起到了数据一次copy传输的作用(这里只做原理学习,后面再进行源码分析)。
2、mmap函数属于系统调用,mmap会从当前进程中获取用户态可用的虚拟地址空间(vm_area_struct *vma),并在mmap_region中真正获取vma,然后调用file->f_op->mmap(file, vma),进入驱动处理,之后就会在内存中分配一块连续的虚拟地址空间,并预先分配好页表、已使用的与未使用的标识、初始地址、与用户空间的偏移等等,通过这一步之后,就能把Binder在内核空间的数据直接通过指针地址映射到用户空间,供进程在用户空间使用,这是一次拷贝的基础。
3、当数据从进程A的用户空间拷贝到内核空间的时候,是直从当前进程A的用户空间接拷贝到目标进程B的内核空间,这个过程是在请求端线程中处理的,操作对象是目标进程B的内核空间。看源码如下:
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply){
...
// 在通过进行binder事物的传递时,如果一个binder事物(用struct binder_transaction结构体表示)需要使用到内存,
// 就会调用binder_alloc_buf函数分配此次binder事物需要的内存空间。
// 需要注意的是:这里是从目标进程的binder内存空间分配所需的内存
//从target进程的binder内存空间分配所需的内存大小,这也是一次拷贝,完成通信的关键,直接拷贝到目标进程的内核空间
//由于用户空间跟内核空间仅仅存在一个偏移地址,所以也算拷贝到用户空间
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
t->buffer->allow_user_free = 0;
t->buffer->debug_id = t->debug_id;
//该binder_buffer对应的事务
t->buffer->transaction = t;
//该事物对应的目标binder实体 ,因为目标进程中可能不仅仅有一个Binder实体
t->buffer->target_node = target_node;
trace_binder_transaction_alloc_buf(t->buffer);
if (target_node)
binder_inc_node(target_node, 1, 0, NULL);
// 计算出存放flat_binder_object结构体偏移数组的起始地址,4字节对齐。
offp = (size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof(void *)));
// struct flat_binder_object是binder在进程之间传输的表示方式 //
// 这里就是完成binder通讯单边时候在用户进程同内核buffer之间的一次拷贝动作 //
// 这里的数据拷贝,其实是拷贝到目标进程中去,因为t本身就是在目标进程的内核空间中分配的,
if (copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)) {
binder_user_error("binder: %d:%d got transaction with invalid "
"data ptr\n", proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
可以看到binder_alloc_buf(target_proc, tr->data_size,tr->offsets_size, !reply && (t->flags & TF_ONE_WAY))函数在申请内存的时候,是从target_proc进程空间中去申请的,这样在做数据拷贝的时候copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)),就会直接拷贝target_proc的内核空间,而由于Binder内核空间的数据能直接映射到用户空间,这里就不在需要拷贝到用户空间。这就是一次拷贝的原理。内核空间的数据映射到用户空间其实就是添加一个偏移地址,并且将数据的首地址、数据的大小都复制到一个用户空间的Parcel结构体,具体可以参考Parcel.cpp的Parcel::ipcSetDataReference函数。

原文:https://blog.csdn.net/happylishang/article/details/62234127