Multi-Cue Zero-Shot Learning with Strong Supervision阅读笔记CVPR2016收录
论文地址:https://arxiv.org/pdf/1603.08754.pdf
该论文被CVPR2016收录。当时,zero-shot learning的方法中,最好的依然是依靠着人工标注的属性。本文作者希望能够突破这一现状,利用网上多样的非结构化的文本数据实现全自动的算法,并且得到较好的效果。利用外部文本数据(如wikipedia语料库)的方法可以被称为利用附加数据的方法,这类方法的优点是:得到的属性覆盖的范围广,而且能够实现整个算法真正的无监督。此类方法的一个共同问题是:外部数据往往有噪声,而且不容易组织成针对特定分类目的的数据集。为了解决这些问题,作者构建了一个联合嵌入框架(joint embedding framework),将多样的文本信息和语义视觉信息映射到同一个空间中,并使用了一个强监督的方法来表示对象的视觉信息。最终该方法在识别和检索方面的zero-shot learning上取得了当时最好的效果。
本文的贡献:(1)提出了一种基于文本语料库和视觉信息的联合模型;利用外部语料库进行实现;(2)提出了一种新的无监督的词嵌入(language embedding)的方法,针对的是word2vec和BoW;(3)使用了一个强监督的方法,来获取对象的视觉信息表示,用以抵御附加数据带来的负面影响。(4)在zero-shot learning的算法中,该算法在一个数据集上取得了当时最好的结果。
zero-shot learning 多线索嵌入(zero-shot learning multi-Cue Embedding)
目前所有的zero-shot learning算法都基于一个基本理论:利用高维属性代替图片的低维特征,来进行分类器的学习,由于高维特征具有迁移性,因此,这种方式能够达到zero-shot learning的效果。上文已经提到,之前最好的方法利用的是人工的高维描述,这些高维描述比较准确,且针对性强,但是由于需要人工,所以往往很难针作用于大型的任务。为了解决这一问题,才出现了基于外部语料库的方式,使得高维描述的获取变得完全自动。但由于外部数据带有噪声,且针对性不强,使得这种方法最终的效果依然差于人工标注高维描述的效果。针对这一问题,作者使用multiple-cue的思想来联合表示属性,联合文本信息和视觉信息,得到了最终的算法。作者使用的该方法可以被称为多线索嵌入方法(multi-cue embedding)。简单来说,就是先利用外部语料库得到类别的多个方面(multiple language parts)的属性表示,这时属性表示已经确定下来了,再将图片中的对象进行多个方面(multiple visual parts)的表示,训练从样本对象到类别属性之间的映射(分类器),即可实现zero-shot learning。
算法内容
构建算法的方式依旧是建立目标函数,加约束,得到最优化解。(机器学习的一般套路)设输入为x,输出为类别y,则分类器可以被定义为:

即输入x,得到分数最高的y,即为x的类别。其中F(x,y)为

gx代表输入样本x的视觉描述子的集合,gy代表类别y的文本描述子的集合。vi和sj分别属于集合gx和gy,|gx|和|gy|分别表示相应集合的元素个数。vi和sj可以进一步写成

为了学习上述分类器,作者将分类器函数转化为一个目标函数
目标函数中有

对于目标函数的优化,作者只提到了使用SGD(Stochastic Gradient Descent)的方式,以及mini-batch为100,动量为0.9,在数据及上跑了20次,没有提到其他的细节。其实对于上述目标函数,应该是最小化目标函数,对于约束的存在,可以使用拉格朗日法进行求解,逐步调整映射矩阵的值就可以了。
样本X通常是图片,将它转化为算法的输入,即semantic visual parts。这里所说的semantic visual parts可以理解为描述一个物体不同部分或者不同方面的词,例如描述”black footed albatross”可以用”a large sea bird with black feet and curved beak”。其中”large sea bird”、”black feet”和”curved beak”就可以被称为semantic visual parts,它们共同描述了对象”black footed albatross”。作者使用的是一个深度CNN来提取对象的这些semantic visual parts,实验时作者每个图片都有19个bounding box,用来圈出对象不同的部分。
类别y通常是文本的形式,例如“金毛犬”就是一种类别。通常基于外部语料库的方式是:先在语料库中找到有关“金毛犬”的文章,使用LDA抽取文章主题,利用word2vec或者BOW将主题转为词向量的形式。但作者没有使用上述方式,而是提出了新的方法:NAD和MBoW。
这里的NAD指的是Noun-Attribute-Differences。设一个类别集合C={c1,...,cn},共有n类,设属性集合为A={a1,...,am},共有m类属性。设wC()为一个类的word2vec表示,wA()为一个属性的word2vec表示。Word2vec的本质是建立了一个词向量空间,使得词与词之间的相似性可以用词向量空间中的距离来表示。作者提供了三种NAD。
(1)NAD1:该模式下,作者希望能够找到类别ci的最佳对应属性。
这里要注意的是对于一个类别ci,计算了它在词向量空间中和所有属性词向量的距离。
(1)MBow1:对于一个类别,从整个wikipedia文章中选择相应的文章,构成一个BoW直方图(BoW histogram)。
(2)MBow2:将类别对应的文章分为P={2,3,4,5}份,这样可以得到多个向量,由于文章的长度不同,因此短向量需要补0。
(3)MBow3:wikipedia的文章本身是分section的,可以对每一个section对应一个BoW的向量,这样一个类就对应了多个向量。
使用了数据集Caltech UCSD Birds-2011(CUB),包括了200个类,每个类大约有60张图片,每张图片有312个视觉属性,都是关于鸟类的图片。在zero-shot learning中,利用150个类作为训练集,50各类作为测试集。
作者利用VGGnet提取图片的特征,基于wikipedia 数据集得到类别的NAD和MBoW。
作者将论文[1]中的Structured Joint embedding(SJE)方法作为baseline,该方法是当时效果最好的方法,与本文方法进行比较。如表1所示,为算法的结果。其中的supervised是指利用数据集中提供的312个视觉属性,表示样本x和类别y,监督学习出本文算法的映射矩阵Wvisual,和Wlanguage,最终是算法SJE更好。若使用word2vec或Bow非监督学习属性表示,即可将x和y都表示成属性的形式,也可以学习到映射矩阵Wvisual,和Wlanguage。这种方式下,本文算法表现更优。注意这里是将图片里的对象用一个大的bounding box全出来得到的特征,文中称为single visual part(VP=1),并使用single language part LP=1(即NAD1或者MBoW1)。

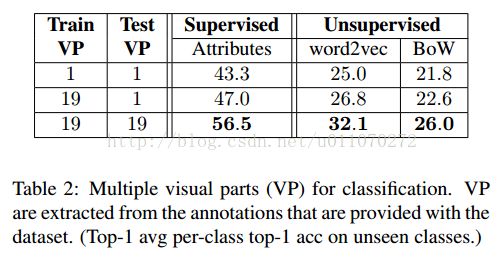





通篇看来,这篇文章的主要贡献在于提出了一种multiple-cue的思想,同时也证明了这种思想的有效性。简单来说就是:通过对于对象多个维度的描述,从而达到更好的结果。构建目标函数的过程,其实借用了跨模态搜索的思想,只是借助了属性向量作为中间表示。但在对图片进行特征提取时,为了达到multiple visual parts的效果,需要先对图片中对应的部分圈出bounding box,这个工作其实现实中并不太好做,可以想象的是,如果bounding box圈得不好,对于结果的影响应该会很大。并且,它的multiple language parts的效果是基于multiple visual parts的,这样一来就更加重了算法对于bounding box的依赖。最终算法得到了当时在该数据集上效果最好的zero-shot learning结果,但是和基于人工定义属性的方法相比,还是相差很多。