基于OGG 实现Oracle到Kafka增量数据实时同步
背景
在大数据时代,存在大量基于数据的业务。数据需要在不同的系统之间流动、整合。通常,核心业务系统的数据存在OLTP数据库系统中,其它业务系统需要获取OLTP系统中的数据。传统的数仓通过批量数据同步的方式,定期从OLTP系统中抽取数据。但是随着业务需求的升级,批量同步无论从实时性,还是对在线OLTP系统的抽取压力,都无法满足要求。需要实时从OLTP系统中获取数据变更,实时同步到下游业务系统。
本文基于Oracle OGG,介绍一种将Oracle数据库的数据实时同步到Kafka消息队列的方法。
Kafka是一种高效的消息队列实现,通过订阅kafka的消息队列,下游系统可以实时获取在线Oracle系统的数据变更情况,实现业务系统。
环境介绍
组件版本
本案例中使用到的组件和版本
| 组件 |
版本 |
描述 |
| 源端Oracle |
Oracle 12.2.0.1.0 Linux x64 |
源端Oracle |
| 源端OGG |
Oracle GoldenGate 12.3.0.1.4 for Oracle Linux x64 |
源端OGG,用于抽取源端Oracle的数据变更,并将变更日志发送到目标端 |
| 目标端OGG |
OGG_BigData_Linux_x64_12.3.2.1.1 |
目标端OGG,接受源端发送的Oracle事物变更日志,并将变更推送到kafka消息队列。 |
| 目标端kafka |
kafka_2.12-2.2.0 |
消息队列,接收目标端OGG推送过来的数据。 |
整体架构图
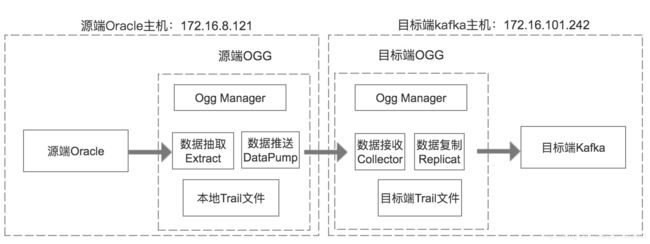
名词解释
1.OGG Manager
OGG Manager用于配置和管理其它OGG组件,配置数据抽取、数据推送、数据复制,启动和停止相关组件,查看相关组件的运行情况。
2.数据抽取(Extract)
抽取源端数据库的变更(DML, DDL)。数据抽取主要分如下几种类型:
- 本地抽取
从本地数据库捕获增量变更数据,写入到本地Trail文件
- 数据推送(Data Pump)
从本地Trail文件读取数据,推送到目标端。
- 初始数据抽取
从数据库表中导出全量数据,用于初次数据加载
3.数据推送(Data Pump)
Data Pump是一种特殊的数据抽取(Extract)类型,从本地Trail文件中读取数据,并通过网络将数据发送到目标端OGG
4.Trail文件
数据抽取从源端数据库抓取到的事物变更信息会写入到Trail文件。
5.数据接收(Collector)
数据接收程序运行在目标端机器,用于接收Data Pump发送过来的Trail日志,并将数据写入到本地Trail文件。
6.数据复制(Replicat)
数据复制运行在目标端机器,从Trail文件读取数据变更,并将变更数据应用到目标端数据存储系统。本案例中,数据复制将数据推送到kafka消息队列。
7.检查点(Checkpoint)
检查点用于记录数据库事物变更。
操作步骤
源端Oracle配置
1.检查归档
使用OGG,需要在源端开启归档日志
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /u01/app/oracle/product/12.2.0/db_1/dbs/arch
Oldest online log sequence 2576
Next log sequence to archive 2577
Current log sequence 25772.检查数据库配置
SQL> select force_logging, supplemental_log_data_min from v$database;
FORCE_LOGG SUPPLEMENTAL_LOG_DATA_MI
---------- ------------------------
YES YES
如果没有开启辅助日志,需要开启:
SQL> alter database force logging;
SQL> alter database add supplemental log data;3.开启goldengate复制参数
SQL> alter system set enable_goldengate_replication = true;4.创建源端Oracle账号
SQL> create tablespace tbs_ogg datafile '/oradata/dtstack/tbs_ogg.dbf' size 1024M autoextend on;
SQL> create user ggsadmin identified by oracle default tablespace tbs_ogg;
SQL> grant dba to ggsadmin;5.创建测试表
SQL> create table baiyang.ora_to_kfk as select OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID, DATA_OBJECT_ID, OBJECT_TYPE from all_objects where object_id < 500;
SQL> alter table baiyang.ora_to_kfk add constraint pk_kfk_obj primary key(object_id);
SQL> select count(*) from baiyang.ora_to_kfk;
COUNT(*)
----------
436源端OGG配置
1.检查源端OGG环境
cd /oradata/oggorcl/ogg
./ggsci
GGSCI (dtproxy) 1> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER STOPPED2.创建相关文件夹
GGSCI (dtproxy) 2> create subdirs
Creating subdirectories under current directory /oradata/oggorcl/ogg
Parameter file /oradata/oggorcl/ogg/dirprm: created.
Report file /oradata/oggorcl/ogg/dirrpt: created.
Checkpoint file /oradata/oggorcl/ogg/dirchk: created.
Process status files /oradata/oggorcl/ogg/dirpcs: created.
SQL script files /oradata/oggorcl/ogg/dirsql: created.
Database definitions files /oradata/oggorcl/ogg/dirdef: created.
Extract data files /oradata/oggorcl/ogg/dirdat: created.
Temporary files /oradata/oggorcl/ogg/dirtmp: created.
Credential store files /oradata/oggorcl/ogg/dircrd: created.
Masterkey wallet files /oradata/oggorcl/ogg/dirwlt: created.
Dump files /oradata/oggorcl/ogg/dirdmp: created.3.配置源端Manager
GGSCI (dtproxy) 4> dblogin userid ggsadmin password oracle
Successfully logged into database.
GGSCI (dtproxy as ggsadmin@dtstack) 5> edit param ./globals
-- 添加
oggschema ggsadmin
GGSCI (dtproxy as ggsadmin@dtstack) 6> edit param mgr
-- 添加
PORT 7810 --默认监听端口
DYNAMICPORTLIST 7811-7820 --动态端口列表
AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3 --进程有问题,每3分钟重启一次,一共重启五次
PURGEOLDEXTRACTS ./dirdat/*, USECHECKPOINTS, MINKEEPDAYS 7 --*/
LAGREPORTHOURS 1 --每隔一小时检查一次传输延迟情况
LAGINFOMINUTES 30 --传输延时超过30分钟将写入错误日志
LAGCRITICALMINUTES 45 --传输延时超过45分钟将写入警告日志
PURGEMARKERHISTORY MINKEEPDAYS 3, MAXKEEPDAYS 7 --定期清理trail文件
ACCESSRULE, PROG *, IPADDR 172.*.*.*, ALLOW --设定172网段可连接
-- 添加同步的表
GGSCI (dtproxy as ggsadmin@dtstack) 9> add trandata baiyang.ora_to_kfk
-- Oracle Goldengate marked following column as key columns on table BAIYANG.ORA_TO_KFK: OBJECT_ID.
GGSCI (dtproxy as ggsadmin@dtstack) 10> info trandata baiyang.ora_to_kfk
-- Prepared CSN for table BAIYANG.ORA_TO_KFK: 192881239目标端OGG配置
1.目标端检查环境
GGSCI (172-16-101-242) 1> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER STOPPED 2.创建目录
GGSCI (172-16-101-242) 2> create subdirs
Creating subdirectories under current directory /app/ogg
Parameter file /app/ogg/dirprm: created.
Report file /app/ogg/dirrpt: created.
Checkpoint file /app/ogg/dirchk: created.
Process status files /app/ogg/dirpcs: created.
SQL script files /app/ogg/dirsql: created.
Database definitions files /app/ogg/dirdef: created.
Extract data files /app/ogg/dirdat: created.
Temporary files /app/ogg/dirtmp: created.
Credential store files /app/ogg/dircrd: created.
Masterkey wallet files /app/ogg/dirwlt: created.
Dump files /app/ogg/dirdmp: created.3.目标端Manager配置
GGSCI (172-16-101-242) 3> edit params mgr
-- 添加
PORT 7810
DYNAMICPORTLIST 7811-7820
AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 3
GGSCI (172-16-101-242) 4> edit param ./GLOBALS
CHECKPOINTTABLE ggsadmin.checkpoint全量数据同步
1.配置源端数据初始化
-- 配置源端初始化进程
GGSCI (dtproxy as ggsadmin@dtstack) 15> add extract initkfk,sourceistable
-- 配置源端初始化参数
GGSCI (dtproxy as ggsadmin@dtstack) 16> edit params initkfk
-- 添加
EXTRACT initkfk
SETENV (NLS_LANG=AMERICAN_AMERICA.AL32UTF8)
USERID ggsadmin,PASSWORD oracle
RMTHOST 172.16.101.242, MGRPORT 7810
RMTFILE ./dirdat/ekfk,maxfiles 999, megabytes 500
table baiyang.ora_to_kfk;2.源端生成表结构define文件
GGSCI (dtproxy as ggsadmin@dtstack) 17> edit param define_kfk
-- 添加
defsfile /oradata/oggorcl/ogg/dirdef/define_kfk.txt
userid ggsadmin,password oracle
table baiyang.ora_to_kfk;
-- 执行
$./defgen paramfile dirprm/define_kfk.prm
-- Definitions generated for 1 table in /oradata/oggorcl/ogg/dirdef/define_kfk.txt
-- 将此文件传输到目标段dirdef文件夹
scp /oradata/oggorcl/ogg/dirdef/define_kfk.txt 172.16.101.242:/app/ogg/dirdef/define_kfk.txt3.配置目标端数据初始化进程
-- 配置目标端初始化进程
GGSCI (172-16-101-242) 3> ADD replicat initkfk,specialrun
GGSCI (172-16-101-242) 6> edit params initkfk
-- 添加
SPECIALRUN
end runtime
setenv(NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
targetdb libfile libggjava.so set property=./dirprm/kafka.props
SOURCEDEFS ./dirdef/define_kfk.txt
EXTFILE ./dirdat/ekfk000000
reportcount every 1 minutes, rate
grouptransops 10000
map baiyang.ora_to_kfk,target baiyang.ora_to_kfk;4.配置kafka相关参数
-- 配置kafka 相关参数
vi ./dirprm/kafka.props
-- 添加
gg.handlerlist=kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
gg.handler.kafkahandler.topicMappingTemplate=test_ogg
gg.handler.kafkahandler.format=json
gg.handler.kafkahandler.mode=op
gg.classpath=dirprm/:/data/kafka_2.12-2.2.0/libs/*:/app/ogg/:/app/ogg/lib/* --*/
vi custom_kafka_producer.properties
-- 添加
bootstrap.servers=172.16.101.242:9092
acks=1
compression.type=gzip
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
batch.size=102400
linger.ms=100005.源端开启全量数据抽取
-- 源端
GGSCI (dtproxy) 20> start mgr
GGSCI (dtproxy) 21> start initkfk6.目标端全量数据应用
GGSCI (172-16-101-242) 13> start mgr
./replicat paramfile ./dirprm/initkfk.prm reportfile ./dirrpt/init01.rpt -p INITIALDATALOAD7.kafka数据验证
使用kafka客户端工具查看topic的数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_ogg --from-beginning
{"table":"BAIYANG.ORA_TO_KFK","op_type":"I","op_ts":"2019-11-11 20:23:19.703779","current_ts":"2019-11-11T20:48:55.946000","pos":"-0000000000000000001","after":{"OWNER":"SYS","OBJECT_NAME":"C_OBJ#","SUBOBJECT_NAME":null,"OBJECT_ID":2,"DATA_OBJECT_ID":2,"OBJECT_TYPE":"CLUSTER"}}
{"table":"BAIYANG.ORA_TO_KFK","op_type":"I","op_ts":"2019-11-11 20:23:19.703779","current_ts":"2019-11-11T20:48:56.289000","pos":"-0000000000000000001","after":{"OWNER":"SYS","OBJECT_NAME":"I_OBJ#","SUBOBJECT_NAME":null,"OBJECT_ID":3,"DATA_OBJECT_ID":3,"OBJECT_TYPE":"INDEX"}}
全量数据已经同步到目标kafka topic增量数据同步
1.源端抽取进程配置
GGSCI (dtproxy) 9> edit param extkfk
-- 添加
dynamicresolution
SETENV (ORACLE_SID = "dtstack")
SETENV (NLS_LANG = "american_america.AL32UTF8")
userid ggsadmin,password oracle
exttrail ./dirdat/to
table baiyang.ora_to_kfk;
-- 添加extract进程
GGSCI (dtproxy) 10> add extract extkfk,tranlog,begin now
-- 添加trail文件的定义与extract进程绑定
GGSCI (dtproxy) 11> add exttrail ./dirdat/to,extract extkfk2.源端数据推送进程配置
-- 配置源端推送进程
GGSCI (dtproxy) 12> edit param pupkfk
-- 添加
extract pupkfk
passthru
dynamicresolution
userid ggsadmin,password oracle
rmthost 172.16.101.242 mgrport 7810
rmttrail ./dirdat/to
table baiyang.ora_to_kfk;
-- 添加extract进程
GGSCI (dtproxy) 13> add extract pupkfk,exttrailsource /oradata/oggorcl/ogg/dirdat/to
-- 添加trail文件的定义与extract进程绑定
GGSCI (dtproxy) 14> add rmttrail ./dirdat/to,extract pupkfk3.配置目标端恢复进程
-- 配置目标端恢复进程
edit param repkfk
-- 添加
REPLICAT repkfk
SOURCEDEFS ./dirdef/define_kfk.txt
targetdb libfile libggjava.so set property=./dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
MAP baiyang.ora_to_kfk, TARGET baiyang.ora_to_kfk;
--添加trail文件到replicate进程
add replicat repkfk exttrail ./dirdat/to,checkpointtable ggsadmin.checkpoint4.源端开启实时数据抓取
./ggsci
GGSCI (dtproxy) 5> start extkfk
Sending START request to MANAGER ...
EXTRACT EXTKFK starting
GGSCI (dtproxy) 6> start pupkfk
Sending START request to MANAGER ...
EXTRACT PUPKFK starting
GGSCI (dtproxy) 7> status all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT RUNNING EXTKFK 00:00:00 00:00:10
EXTRACT RUNNING PUPKFK 00:00:00 00:00:005.目标端开启实时数据同步
./ggsci
GGSCI (172-16-101-242) 7> start replicat repkfk
Sending START request to MANAGER ...
REPLICAT REPKFK starting
GGSCI (172-16-101-242) 8> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT RUNNING REPKFK 00:00:00 00:00:006.测试增量数据同步
- Oracle插入增量数据
SQL> insert into baiyang.ora_to_kfk select OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID, DATA_OBJECT_ID, OBJECT_TYPE from all_objects where object_id >500 and object_id < 1000;
SQL> commit;
SQL> select count(*) from baiyang.ora_to_kfk;
COUNT(*)
----------
905- 查看Kafka消息队列消费数据
{"table":"BAIYANG.ORA_TO_KFK","op_type":"I","op_ts":"2019-11-11 21:04:11.158786","current_ts":"2019-11-11T21:10:54.042000","pos":"00000000000000075298","after":{"OWNER":"SYS","OBJECT_NAME":"APPLY$_READER_STATS","SUBOBJECT_NAME":null,"OBJECT_ID":998,"DATA_OBJECT_ID":998,"OBJECT_TYPE":"TABLE"}}
{"table":"BAIYANG.ORA_TO_KFK","op_type":"I","op_ts":"2019-11-11 21:04:11.158786","current_ts":"2019-11-11T21:10:54.042001","pos":"00000000000000075459","after":{"OWNER":"SYS","OBJECT_NAME":"APPLY$_READER_STATS_I","SUBOBJECT_NAME":null,"OBJECT_ID":999,"DATA_OBJECT_ID":999,"OBJECT_TYPE":"INDEX"}}- 源端Oracle删除数据
SQL> delete from baiyang.ora_to_kfk ;
906 rows deleted.
SQL> commit;- 查看kafka消息队列消费数据
{"table":"BAIYANG.ORA_TO_KFK","op_type":"D","op_ts":"2019-11-11 21:13:11.166184","current_ts":"2019-11-11T21:13:17.449007","pos":"00000000000000216645","before":{"OWNER":"x1","OBJECT_NAME":"SSSSS","SUBOBJECT_NAME":"z1","OBJECT_ID":111000,"DATA_OBJECT_ID":2000,"OBJECT_TYPE":"x1"}}- 源端插入数据
SQL> insert into baiyang.ora_to_kfk values('汉字', 'y1', 'z1', 111000,2000,'x1');
1 row created.
SQL> commit;- 查看kafka消息队列消费数据
{"table":"BAIYANG.ORA_TO_KFK","op_type":"I","op_ts":"2019-11-11 21:14:21.167454","current_ts":"2019-11-11T21:14:26.497000","pos":"00000000000000216794","after":{"OWNER":"汉字","OBJECT_NAME":"y1","SUBOBJECT_NAME":"z1","OBJECT_ID":111000,"DATA_OBJECT_ID":2000,"OBJECT_TYPE":"x1"}}总结
使用OGG可以方便地将Oracle的数据变更情况实时同步到Kafka消息队列。下游业务系统通过订阅kafka的消息队列,能方便地实现各类实时数据的应用。