Hadoop伪分布式部署 - CentOS
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Hadoop伪分布式部署 - CentOS
本文关键字:Hadoop、伪分布式、安装部署、CentOS
文章目录
- Hadoop伪分布式部署 - CentOS
- 一、Hadoop介绍
- 1. Hadoop发展史及生态圈
- 2. Hadoop核心功能及优势
- 3. 部署方式介绍
- 二、Hadoop下载
- 1. 下载地址
- 2. 版本选择
- 3. 安装包下载
- 三、安装步骤
- 1. 前置环境
- 2. Hadoop安装
- 3. Hadoop配置
- 4. SSH免密码登录配置
- 5. 集群启动及确认
一、Hadoop介绍
Hadoop软件库是一个计算框架,可以使用简单的编程模型以集群的方式对大型数据集进行分布式处理。
1. Hadoop发展史及生态圈
- Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一。
- 2006年2月,成为一套完整而独立的软件,并被命名为Hadoop。
- 2008年1月,Hadoop成为Apache顶级项目。
- 2009年7月,MapReduce和HDFS成为Hadoop的独立子项目。
- 2010年5月,Avro脱离Hadoop项目,成为Apache顶级项目。
- 2010年5月,HBase脱离Hadoop项目,成为Apache顶级项目。
- 2010年9月,Hive脱离Hadoop项目,成为Apache顶级项目。
- 2010年9月,Pig脱离Hadoop项目,成为Apache顶级项目。
- 2011年1月,Zookeeper脱离Hadoop项目,成为Apache顶级项目。
- 2011年12月,Hadoop 1.0.0版本发布。
- 2012年10月,Impala加入Hadoop生态圈。
- 2013年10月,Hadoop 2.0.0版本发布。
- 2014年2月,Spark成为Apache顶级项目。
- 2017年12月,Hadoop 3.0.0版本发布。
2. Hadoop核心功能及优势
- 分布式存储系统:HDFS
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的简称,是Hadoop生态系统中的核心项目之一,也是分布式计算中数据存储管理的基础。
- 分布式计算框架:MR
MapReduce是一种计算模型,核心思想就是“分而治之”,可以用于TB级的大规模并行计算。Map阶段处理后形成键值对形式的中间结果;Reduce对中间结果相同的“键”对应的“值”进行处理,得到最终结果。
- 资源管理平台:YARN
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,可以为上层应用提供统一的资源管理和调度,为集群的资源利用率、统一管理、数据共享等方面提供了便利。
- 高扩展
Hadoop是一个高度可扩展的存储平台,可以存储和分发超数百个并行操作的廉价的服务器集群。能够打破传统的关系数据库无法处理大量数据的限制,Hadoop能够提供TB级别数据的运算能力。
- 成本低
Hadoop可以将廉价的机器组成服务器集群来分发处理数据,成本较低,学习者及普通用户也能够很方便的在自己的PC上部署Hadoop环境。
- 高效率
Hadoop能够并发的处理数据任务,并且能够在不同的节点之间移动数据,可以保证各个节点的动态平衡。
- 容错性
Hadoop可以自动维护多份数据的副本,如果计算任务失败,Hadoop能够针对失败的节点重新处理。
3. 部署方式介绍
- 单机模式
单机模式是一个最简的安装模式,因为Hadoop本身是基于Java编写的,所以只要配置好Java的环境变量就可以运行了。在这种部署方式中我们不需要修改任何的配置文件,也不需要启动任何的服务,只需要解压缩、配置环境变量。
虽然配置很简单,但是能做的事情也是很少的。因为没有各种守护进程,所以分布式数据存储以及资源调度等等服务都是不能使用的,但是我们可以很方便的测试MapReduce程序。
- 伪分布模式
伪分布模式是学习阶段最常用的模式,可以将进程都运行在同一台机器上。在这种模式下,可以模拟全分布模式下的运行状态,基本上可以完成全分布模式下的所有操作,伪分布模式是全分布模式的一个特例。
- 全分布模式
在全分布模式下,会在配置文件中体现出主节点与分节点,可以指定哪些机器上运行哪些服务以达到的成本与效率的平衡。在企业中主要采用的都是全分布式模式,节点从数十个到上百个不等。在学习阶段,如果个人PC的性能足够强劲,也可以使用多台虚拟机代替。
二、Hadoop下载
作为一个软件的学习者和开发者,大家一定要培养自己:去官网、查资料的好习惯,摆脱各种一键安装、软件管家之类的东西,把一切掌控在自己手中,用严谨的态度来要求自己,加油!
1. 下载地址
在百度中搜索Hadoop,前两条就会显示我们需要的网站,目前Hadoop属于Apache基金会,所以我们打开网址时注意一下是apache.org。
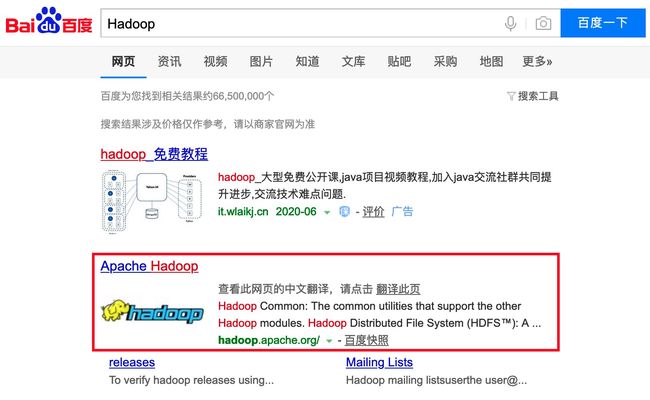
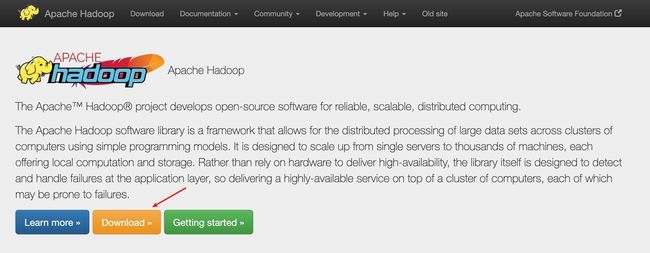
进入后来到Hadoop的官网,点击Download就可以打开下载界面:https://hadoop.apache.org/releases.html。
2. 版本选择
现在我们使用的是开源社区版,目前的主流版本为2.x.y和3.x.y。
在选择Hadoop的版本时,我们应该考虑到与其他生态圈软件的兼容问题。通常的组建方式有两种:
- 根据各组件的兼容性要求手动选择版本并搭建
- 使用CDH(Cloudera’s Distribution Including Apache Hadoop)自动选择版本并解决兼容问题
在学习阶段,由于进行的操作比较简单,不需要特别的在意版本的兼容问题,但是建议两种方式大家都能够去进行了解和实践。
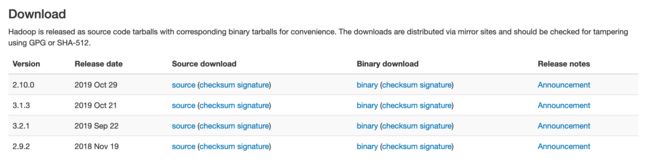
3. 安装包下载
本文选择2.9.2版本进行演示,Source为源码,Binary为我们所需要的软件包,点击对应版本的binary进入下载界面。
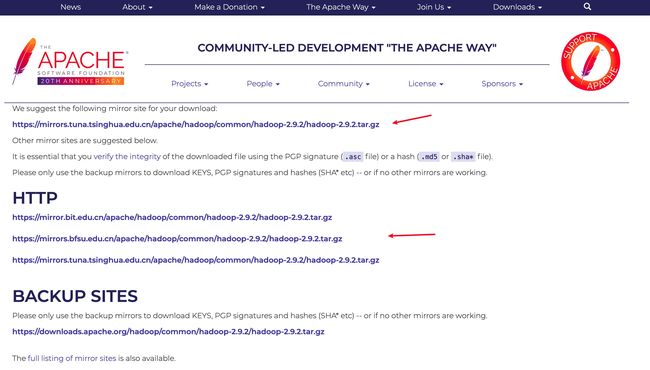
点击任意一个镜像地址开始下载,直击链接:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz。
三、安装步骤
1. 前置环境
在配置Hadoop前,需要先配置好JDK,在安装先需要先卸载历史版本,详细的步骤可以参考我的另一篇文章:JDK的解压安装 - CentOS。
- 查询历史版本(如没有可跳过下一步)
rpm -qa|grep java
rpm -qa|grep jdk
- 卸载历史版本(使用root用户操作)
rpm -e --nodeps 软件包全称(从查询处获得)
- 解压缩
tar -zvxf jdk-8u251-linux-x64.tar.gz
- 配置环境变量(以全局为例-root用户操作)
vi /etc/profile
# 在文件结尾添加以下内容
JAVA_HOME=/opt/jdk1.8.0_251
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export JAVA_HOME
export PATH
- 刷新环境变量
source /etc/profile
- 使用命令测试
java -version

2. Hadoop安装
对于Hadoop软件,通常会新建一个单独的用户来管理,下面以普通用户hadoop为例来进行操作。
# 新建hadoop用户
useradd hadoop
# 为hadoop用户设置密码
passwd hadoop
# 切换至hadoop用户
su - hadoop
- 解压缩
使用hadoop用户新建一个会话,上传Hadoop软件包。
tar -zxvf hadoop-2.9.2.tar.gz
- 配置环境变量(以用户变量为例)
vi ~/.bash_profile
# 在文件结尾添加以下内容
HADOOP_HOME=/home/hadoop/hadoop-2.9.2
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME
export PATH
- 刷新环境变量
source ~/.bash_profile
- 使用命令测试
hadoop version

3. Hadoop配置
如果以伪分布模式运行Hadoop需要先进行相关配置,并启动守护进程(后台运行)。
- 配置文件所在路径
需要修改的配置文件所在路径在Hadoop的安装目录下的etc文件夹中。
$HADOOP_HOME/etc/hadoop
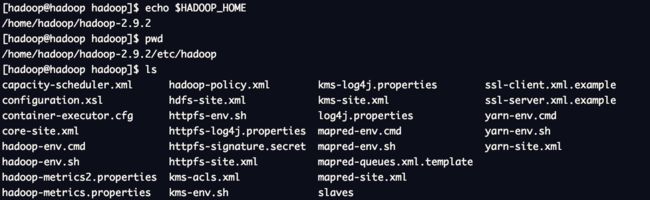
- hadoop-env.sh
在Hadoop启动时会调用执行该文件,需要在其中设置JAVA_HOME,即依赖的Java环境安装位置(25行),确保export前没有井号。
export JAVA_HOME=/opt/jdk1.8.0_251
- core-site.xml
Hadoop的核心配置文件,全部配置项可参考官方文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml。
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/hadoop-2.9.2/datavalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop:9000value>
property>
<property>
<name>fs.trash.intervalname>
<value>60value>
property>
configuration>
- hdfs-site.xml
HDFS核心配置文件,全部配置项可参考官方文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml。
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>hadoop:50070value>
property>
configuration>
- mapred-site.xml(重命名mapred-site.xml.template)
Hadoop计算功能模块相关配置文件,全部配置项可参考官方文档:https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml。
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
- yarn-site.xml
Yarn资源调度相关配置文件,全部配置项可参考官方文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml。
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoopvalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>1536value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
- slaves
从节点配置文件,推荐使用主机名的方式配置。
hadoop
4. SSH免密码登录配置
在CentOS系统中已经默认安装并启动了SSH服务,配置免密码登录可以使Hadoop在使用的过程中更加方便。
- 配置主机名映射(root用户操作)
为方便维护和使用,在配置文件中均使用主机名进行了配置,所以在启动前要确保主机名能够成功解析成ip地址,注意不要使用127.0.0.1,如果之前配置过单机模式,需要修改过来。
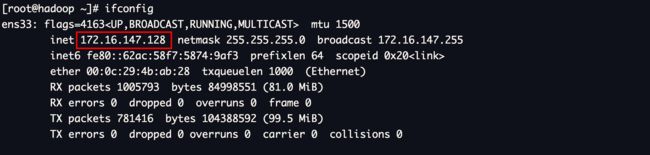
# 查看本机ip地址
ifconfig
# 编辑修改主机名映射文件,在结尾添加映射信息
vi /etc/hosts
172.16.147.128 hadoop
# 配置完成后使用ping命令验证(Ctrl + C终止)
ping hadoop


- 生成密钥
# 整个过程一直回车即可
ssh-keygen -t rsa
- 配置登录到本机的免密码登录
# 第一个hadoop为用户名,第二个hadoop为主机名,可根据实际情况进行修改
ssh-copy-id hadoop@hadoop
# 输入一次hadoop用户的密码即可通过验证
- 使用远程登录命令验证
# 第一次登录可能会出现验证提示,输入yes后回车,如果不需要输入密码直接登录则配置成功
ssh hadoop@hadoop
5. 集群启动及确认
- 格式化namenode
第一次使用Hadoop时需要进行初始化,该操作只需要执行一次,完成后会根据core-site.xml中的配置,在对应的目录下自动创建相应的文件夹。
hdfs namenode -format
- 启动Hadoop进程
由于已经配置了环境变量,可以直接执行sbin目录下的脚本:start-all.sh,如果需要停止可以执行stop-all.sh。
start-all.sh
- jps命令验证
jps为安装JDK环境后的命令,可以查看到当前用户下的Java进程,如果无法使用需检查JDK的环境变量配置。
jps
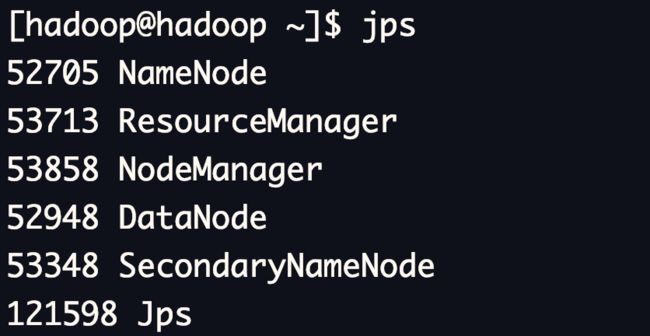
如果能够成功出现5个进程,证明成功(不包括jps本身)。需要注意的是,如果进程在启动一小段时间之后自动消失则证明该进程存在问题,需要根据日志信息进行排查。