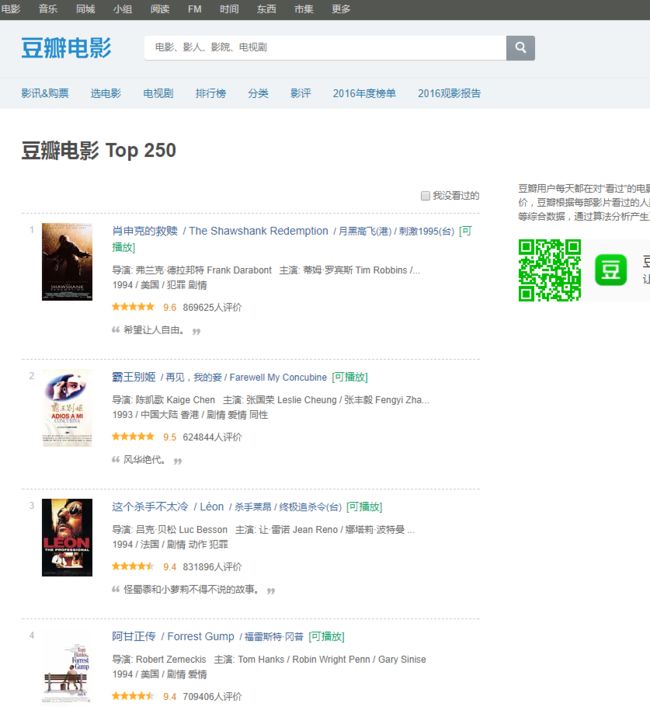
- Python编程:从入门到实践
YC运维
Python_studypython学习开发语言
这是基于《Python编程:从入门到实践》这本书以一个初学者的视角去学习而记录的笔记,浓缩了精华的部分以及分享了一些我自己的见解。做这个既是为了让自己边学边记录也是为了保留自己的问题去和小伙伴一起谈论。一,python是什么以及核心作用Python是一种高级、解释型、面向对象的编程语言,由荷兰人GuidovanRossum于1989年圣诞节期间创建,第一个公开发行版发行于1991年。它的设计哲学强
- Python打卡day6 描述性统计
荣582
python学习打卡python开发语言机器学习
@疏锦行针对其他特征绘制单特征图和特征和标签的关系图,并且试图观察出一些有意思的结论单特征可视化importmatplotlib.pyplotaspltimportseabornassnsimportpandasaspd#读取数据,这里假设数据文件名为data.csv,你需要根据实际情况修改文件名data=pd.read_csv('data.csv')#连续变量可视化示例plt.figure(fi
- 【Python 语法】Python 神经网络项目常用语法
一杯水果茶!
人生苦短我用Pythonpython
基础1.导入模块和包2.修改系统路径(sys.path.append)3.命令行参数解析(argparse模块)4.assert确保正确性5.main()脚本入口点6.辅助函数生成器函数`cycle(dl)`一、常用函数1.`.cuda()`/`.cpu()`和`torch.device`2.`torch.zeros`、`torch.randn`、`torch.arrange`、`torch.po
- python中的字典类型_Python中字典数据类型
石墨稀
python中的字典类型
一.创建字典方法①:>>>dict1={}>>>dict2={'name':'earth','port':80}>>>dict1,dict2({},{'port':80,'name':'earth'})方法②:从Python2.2版本起>>>fdict=dict((['x',1],['y',2]))>>>fdict{'y':2,'x':1}方法③:从Python2.3版本起,可以用一个很方便的内建
- Python 中的列表(List)和元组(Tuple)
shangjg3
Pythonpython开发语言
1.定义与语法差异1.列表的定义列表使用方括号`[]`定义,元素之间用逗号分隔。列表的元素可以是不同数据类型,甚至嵌套其他列表或元组。my_list=[1,"hello",True,[2,3]]2.元组的定义元组使用圆括号`()`定义,同样支持混合数据类型。需要注意的是,定义单元素元组时必须在元素后加逗号,以区别于数学表达式中的括号。my_tuple=(1,"world",False,(4,5))
- Python 列表
列表是由一系列按特定顺序排列的元素组成。在python中用方括号([])来表示列表并用逗号来分隔其中的元素。例如:bicycles=['trek','cannondale','redline']。访问列表元素时,只需将该元素的索引值或位置告诉Python即可。(索引值由0开始)>>>names=['zhao','qian','sun','li']>>>print(names[0])zhao创建的大
- 列表 简单数据类型
天池小晨
python
整型浮点型布尔型容器数据类型列表元组字典集合字符串1.列表的定义列表是有序集合,没有固定大小,能够保存任意数量任意类型的Python对象,语法为[元素1,元素2,...,元素n]。关键点是「中括号[]」和「逗号,」中括号把所有元素绑在一起逗号将每个元素一一分开2.列表的创建创建一个普通列表【例子】1x=['Monday','Tuesday','Wednesday','Thursday','Frid
- Python-难点-获取项目根目录
1需求2接口3示例4参考资料在Python中,“设置根目录”通常指指定项目的基准路径,以便统一管理文件路径。以下是几种常见方法,结合不同场景和兼容性需求:一、基于路径拼接(最常用)通过手动拼接路径来定义根目录,适用于结构固定的项目。importos#方法1:根据当前文件位置向上递归定义(推荐)defset_project_root():current_file=os.path.abspath(__
- JSON和JSONL、python操作
weixin_668
jsonpython
JSONJSON(JavaScriptObjectNotation)是一种轻量级的数据交换格式,基于文本、易于读写,并支持多种数据结构。以下是常见的JSON格式及示例:1.简单对象(键值对){"name":"Alice","age":25,"isStudent":true}2.嵌套对象{"person":{"name":"Bob","address":{"city":"NewYork","zipc
- python 抓取小红书
小五咔咔咔
python开发语言
python相关学习资料:https://edu.51cto.com/video/3832.htmlhttps://edu.51cto.com/video/4102.htmlhttps://edu.51cto.com/video/1158.htmlPython抓取小红书数据的科普文章小红书是一个流行的社交电商平台,用户可以分享购物心得、生活点滴等。本文将介绍如何使用Python语言抓取小红书的数据
- 利用 Python 爬取小红书热门笔记并进行标签关键词分析
程序员威哥
最新爬虫实战项目python笔记开发语言
一、背景与目标小红书(RED)作为中国最活跃的内容社区之一,拥有大量关于美妆、穿搭、美食、旅游等领域的用户生成内容(UGC)。对于产品、品牌方或研究人员来说,提取热门笔记的标签关键词,可以有效捕捉用户关注点、消费趋势及内容热词。本项目目标:使用Python爬取小红书某个话题下的热门笔记;分析每篇笔记中的标题、正文、标签等字段;利用NLP技术提取高频关键词;对关键词进行可视化与聚类分析。二、技术难点
- python JSON Lines (JSONL)的保存和读取;jsonl的数据保存和读取,大模型prompt文件保存常用格式
医学小达人
常用算法NLPpromptJSONLinesJSONLjsonljsonl文件保存读取
1.JSONLines(JSONL)文件保存将一个包含多个字典的列表保存为JSONLines(JSONL)格式的文件,每个字典对应一个JSONL文件中的一行。以下是如何实现这一操作的Python代码importjson#定义包含字典的列表data=[{"id":1,"name":"Alice","age":30,"email":"
[email protected]"},{"id":2,"name"
- 四十行Python代码,带你爬取热门音乐评论,制作评论词云图!
请求页面数据driver.get(‘https://music.163.com/#/song?id=569213220’)#selenium无法直接获取到嵌套页面里面的数据switch_to.frame()切换到嵌套网页driver.switch_to.frame(0)让浏览器加载的时候,等待渲染页面driver.implicitly_wait(10)driver.page_source获取请求页
- Python 处理图像并生成 JSONL 元数据文件 - 固定text版本
Python处理图像并生成JSONL元数据文件-固定text版本flyfishJSONL(JSONLines)简介JSONL(JSONLines,也称为newline-delimitedJSON)是一种轻量级的数据序列化格式,由一系列独立的JSON对象组成,每行一个有效的JSON对象,行与行之间通过换行符(\n)分隔。JSONL是传统JSON的“轻量化”变体,通过“每行一个JSON对象”的设计,解
- jxORM--编程指南
jxandrew
jxWebUI数据库pythonjxWebUIjxORMORM
jxORM是jxWebUI配套的数据库操作库,可以简化python程序员操作数据库。声明数据类定义数据类之前,先导入ORM修饰符:fromjxORMimportORM,DBDataType,ColType然后就可以用ORM修饰符来修饰一个类,从而定义一个数据类:@ORMclassUser:ID:DBDataType.Long=ColType.PrimaryKeyCreateTime:DBDataT
- 深度学习系列----->环境搭建(Ubuntu)
二师兄用飘柔
深度学习历程深度学习ubuntu人工智能pytorchpython
1、前言电脑基础系统硬件情况:系统:ubuntu18.04、显卡:GTX1050Ti;后续的环境搭建都在此基础上进行。此次学习选择Pytorch作为深度学习的框架,选择的原因主要由于PyTorch在研究领域特别受欢迎,较多的论文框架也是基于其开发。2、anaconda+python3安装测试在学习深度学习的过程中会涉及到使用不同版本python包的问题,而anaconda可以便捷获取包且对包能够进
- Python中的enumerate()函数
冉成未来
Servicepython开发语言
文章目录基本用法参数说明特点实际应用与zip()的比较注意事项enumerate()是Python内置的一个非常有用的函数,它用于在遍历可迭代对象(如列表、元组、字符串等)时,同时获取元素的索引和值。基本用法fruits=['apple','banana','cherry']forindex,fruitinenumerate(fruits):print(index,fruit)输出:0apple1
- 空间曲线正交投影及其距离计算的理论与实践
老歌老听老掉牙
python正交投影
引言:正交投影的几何本质在三维空间中,正交投影是一种基础而重要的几何变换,它将空间中的点沿特定方向映射到一个平面上。当我们考虑将空间曲线投影到由给定法向量n\mathbf{n}n定义的平面时,这一问题在计算机图形学、CAD/CAM系统和科学计算中具有广泛应用。本文将从数学原理、Python实现到距离计算的等价性问题,全面探讨这一几何操作的深层内涵。设空间曲线由参数方程r(t)=(x(t),y(t)
- pip是如何卸载你安装的第三方库的
酷python
pythonpython
使用pipuninstall命令可以卸载掉你所安装的第三方库,所有与其相关的文件都将被pip整理出来展示并询问是否真的要删除,类似下面的提示pipuninstallnoxFoundexistinginstallation:nox2020.8.22Uninstallingnox-2020.8.22:Wouldremove:d:\python\lib\site-packages\nox-2020.8.
- 深度学习-常用环境配置
瑶山
AIlinux人工智能windowsCUDAPyTorch
目录Miniconda安装安装NVIDIA显卡驱动安装CUDA和cnDNNCUDAcuDNNPyTorch安装手动下载测试Miniconda安装最新版Miniconda搭建Python环境_miniconda创建python虚拟环境-CSDN博客安装NVIDIA显卡驱动直接进NVIDIA官网:NVIDIAGeForce驱动程序-N卡驱动|NVIDIA在这里有GeForce驱动程序,立即下载,这是下
- Nginx IP授权页面实现步骤
目标:一、创建白名单文件sudomkdir-p/usr/local/nginx/conf/whitelistsudotouch/usr/local/nginx/conf/whitelist/temporary.conf二、创建Python认证服务文件路径:/opt/script/auth_server.pyimportosimporttimefromflaskimportFlask,request
- 高阶知识库搭建实战五、(向量数据库Milvus安装)
伯牙碎琴
大模型数据库milvus大模型AI
以下是关于在Windows环境下直接搭建Milvus向量数据库的教程:本教程分两部分,第一部分是基于docker安装,在Windows环境下直接安装Milvus向量数据库,目前官方推荐的方式是通过Docker进行部署,因为Milvus的运行环境依赖于Linux系统。如果你希望在Windows上直接运行Milvus,可以考虑使用MilvusLite版本,这是一个轻量级的Python库,适用于快速原型
- python分布式事务_分布式事务系列(2.1)分布式事务的概念
#1系列目录#2X/OpenDTPDTP全称是DistributedTransactionProcess,即分布式事务模型。之前我们接触的事务都是针对单个数据库的操作,如果涉及多个数据库的操作,还想保证原子性,这就需要使用分布式事务了。而X/OpenDTP就是一种分布式事务处理模型。##2.1X/OpenDTP模型X/Open是一个组织,维基百科上这样说明:X/Open是1984年由多个公司联合创
- LLM初识
从零到一:用Python和LLM构建你的专属本地知识库问答机器人摘要:随着大型语言模型(LLM)的兴起,构建智能问答系统变得前所未有的简单。本文将详细介绍如何使用Python,结合开源的LLM和向量数据库技术,一步步搭建一个基于你本地文档的知识库问答机器人。你将学习到从环境准备、文档加载、文本切分、向量化、索引构建到最终实现问答交互的完整流程。本文包含详细的流程图描述、代码片段思路和关键注意事项,
- CCF-GESP 等级考试 2025年6月认证Python四级真题解析
1单选题(每题2分,共30分)第1题2025年4月19日在北京举行了一场颇为瞩目的人形机器人半程马拉松赛。比赛期间,跑动着的机器人会利用身上安装的多个传感器所反馈的数据来调整姿态、保持平衡等,那么这类传感器类似于计算机的()。A.处理器B.存储器C.输入设备D.输出设备解析:答案:C。所有传感器都用于采集数据,属于输入设备,故选C。第2题小杨购置的计算机使用一年后觉得内存不够用了,想购置一个容量更
- 推荐开源项目:Milvus Lite —— 轻量级向量数据库,助力AI应用快速起飞
穆希静
推荐开源项目:MilvusLite——轻量级向量数据库,助力AI应用快速起飞项目介绍MilvusLite是知名开源向量数据库Milvus的轻量级版本,专为需要在小型环境中进行向量嵌入和相似性搜索的AI应用设计。通过将MilvusLite导入您的Python应用,您可以直接使用Milvus的核心向量搜索功能。MilvusLite已集成在PythonSDKofMilvus中,只需通过pipinstal
- 【华为419机考真题】服务器能耗统计,JAVA 题解
梦想橡皮擦
华为服务器java华为OD机试华为OD
最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理已参加机试人员的实战技巧本篇题解:服务器耗能题目描述服务器有三种运行状态:空载,单任务,多任务,每个时间片的能耗的分别为111、333、444,每个任务由起始时间片和结束时间片定义运行时
- python2.x里面的input()和raw_input()函数以及3.x中的input()函数的区别
scuter_yu
pythonpythoninput函数raw_input函数3.x中的input函数
在python3.0及以上的版本中,raw_input()函数已经和我们说再见了,但是呢,input()函数则很好地替代了消失了的raw_input()函数。而且现在的input()函数所返回的值都是字符串,所以对于要有int,float等类型的数值必须进行强制的类型转换。下面让我对3.0的input()函数做个小总结:>>>str=input("abc:")abc:15>>>str'15'(虽然
- 代码相关(python)
一个月只能修改一次次
代码python
python程序崩溃提示符用python的时候的各个tips矩阵python判断某个矩阵是否满足要求python生成二维随机数文件/档python检查某个文件存不存在python添加有特定字段的文件到列表python矩阵保存为txt文档python按行读文档python写文档python文档操作字符串python用split来拆分字符串python搜索字符串某个字符的位置给字符串前/后添加字符画图
- python 密码学 模块_Python加密与解密 No module named 'Crypto'
weixin_39827304
python密码学模块
DES加密全称为DataEncryptionStandard,即数据加密标准,是一种使用密钥加密的块算法入口参数有三个:Key、Data、ModeKey为7个字节共56位,是DES算法的工作密钥;Data为8个字节64位,是要被加密或被解密的数据;Mode为DES的工作方式,有两种:加密或解密3DES(即TripleDES)是DES向AES过渡的加密算法使用两个密钥,执行三次DES算法加密的过程是
- Spring4.1新特性——Spring MVC增强
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- mysql 性能查询优化
annan211
javasql优化mysql应用服务器
1 时间到底花在哪了?
mysql在执行查询的时候需要执行一系列的子任务,这些子任务包含了整个查询周期最重要的阶段,这其中包含了大量为了
检索数据列到存储引擎的调用以及调用后的数据处理,包括排序、分组等。在完成这些任务的时候,查询需要在不同的地方
花费时间,包括网络、cpu计算、生成统计信息和执行计划、锁等待等。尤其是向底层存储引擎检索数据的调用操作。这些调用需要在内存操
- windows系统配置
cherishLC
windows
删除Hiberfil.sys :使用命令powercfg -h off 关闭休眠功能即可:
http://jingyan.baidu.com/article/f3ad7d0fc0992e09c2345b51.html
类似的还有pagefile.sys
msconfig 配置启动项
shutdown 定时关机
ipconfig 查看网络配置
ipconfig /flushdns
- 人体的排毒时间
Array_06
工作
========================
|| 人体的排毒时间是什么时候?||
========================
转载于:
http://zhidao.baidu.com/link?url=ibaGlicVslAQhVdWWVevU4TMjhiKaNBWCpZ1NS6igCQ78EkNJZFsEjCjl3T5EdXU9SaPg04bh8MbY1bR
- ZooKeeper
cugfy
zookeeper
Zookeeper是一个高性能,分布式的,开源分布式应用协调服务。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如同步, 配置管理,集群管理,名空间。它被设计为易于编程,使用文件系统目录树作为数据模型。服务端跑在java上,提供java和C的客户端API。 Zookeeper是Google的Chubby一个开源的实现,是高有效和可靠的协同工作系统,Zookeeper能够用来lea
- 网络爬虫的乱码处理
随意而生
爬虫网络
下边简单总结下关于网络爬虫的乱码处理。注意,这里不仅是中文乱码,还包括一些如日文、韩文 、俄文、藏文之类的乱码处理,因为他们的解决方式 是一致的,故在此统一说明。 网络爬虫,有两种选择,一是选择nutch、hetriex,二是自写爬虫,两者在处理乱码时,原理是一致的,但前者处理乱码时,要看懂源码后进行修改才可以,所以要废劲一些;而后者更自由方便,可以在编码处理
- Xcode常用快捷键
张亚雄
xcode
一、总结的常用命令:
隐藏xcode command+h
退出xcode command+q
关闭窗口 command+w
关闭所有窗口 command+option+w
关闭当前
- mongoDB索引操作
adminjun
mongodb索引
一、索引基础: MongoDB的索引几乎与传统的关系型数据库一模一样,这其中也包括一些基本的优化技巧。下面是创建索引的命令: > db.test.ensureIndex({"username":1}) 可以通过下面的名称查看索引是否已经成功建立: &nbs
- 成都软件园实习那些话
aijuans
成都 软件园 实习
无聊之中,翻了一下日志,发现上一篇经历是很久以前的事了,悔过~~
断断续续离开了学校快一年了,习惯了那里一天天的幼稚、成长的环境,到这里有点与世隔绝的感觉。不过还好,那是刚到这里时的想法,现在感觉在这挺好,不管怎么样,最要感谢的还是老师能给这么好的一次催化成长的机会,在这里确实看到了好多好多能想到或想不到的东西。
都说在外面和学校相比最明显的差距就是与人相处比较困难,因为在外面每个人都
- Linux下FTP服务器安装及配置
ayaoxinchao
linuxFTP服务器vsftp
检测是否安装了FTP
[root@localhost ~]# rpm -q vsftpd
如果未安装:package vsftpd is not installed 安装了则显示:vsftpd-2.0.5-28.el5累死的版本信息
安装FTP
运行yum install vsftpd命令,如[root@localhost ~]# yum install vsf
- 使用mongo-java-driver获取文档id和查找文档
BigBird2012
driver
注:本文所有代码都使用的mongo-java-driver实现。
在MongoDB中,一个集合(collection)在概念上就类似我们SQL数据库中的表(Table),这个集合包含了一系列文档(document)。一个DBObject对象表示我们想添加到集合(collection)中的一个文档(document),MongoDB会自动为我们创建的每个文档添加一个id,这个id在
- JSONObject以及json串
bijian1013
jsonJSONObject
一.JAR包简介
要使程序可以运行必须引入JSON-lib包,JSON-lib包同时依赖于以下的JAR包:
1.commons-lang-2.0.jar
2.commons-beanutils-1.7.0.jar
3.commons-collections-3.1.jar
&n
- [Zookeeper学习笔记之三]Zookeeper实例创建和会话建立的异步特性
bit1129
zookeeper
为了说明问题,看个简单的代码,
import org.apache.zookeeper.*;
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ThreadLocal
- 【Scala十二】Scala核心六:Trait
bit1129
scala
Traits are a fundamental unit of code reuse in Scala. A trait encapsulates method and field definitions, which can then be reused by mixing them into classes. Unlike class inheritance, in which each c
- weblogic version 10.3破解
ronin47
weblogic
版本:WebLogic Server 10.3
说明:%DOMAIN_HOME%:指WebLogic Server 域(Domain)目录
例如我的做测试的域的根目录 DOMAIN_HOME=D:/Weblogic/Middleware/user_projects/domains/base_domain
1.为了保证操作安全,备份%DOMAIN_HOME%/security/Defa
- 求第n个斐波那契数
BrokenDreams
今天看到群友发的一个问题:写一个小程序打印第n个斐波那契数。
自己试了下,搞了好久。。。基础要加强了。
&nbs
- 读《研磨设计模式》-代码笔记-访问者模式-Visitor
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
interface IVisitor {
//第二次分派,Visitor调用Element
void visitConcret
- MatConvNet的excise 3改为网络配置文件形式
cherishLC
matlab
MatConvNet为vlFeat作者写的matlab下的卷积神经网络工具包,可以使用GPU。
主页:
http://www.vlfeat.org/matconvnet/
教程:
http://www.robots.ox.ac.uk/~vgg/practicals/cnn/index.html
注意:需要下载新版的MatConvNet替换掉教程中工具包中的matconvnet:
http
- ZK Timeout再讨论
chenchao051
zookeepertimeouthbase
http://crazyjvm.iteye.com/blog/1693757 文中提到相关超时问题,但是又出现了一个问题,我把min和max都设置成了180000,但是仍然出现了以下的异常信息:
Client session timed out, have not heard from server in 154339ms for sessionid 0x13a3f7732340003
- CASE WHEN 用法介绍
daizj
sqlgroup bycase when
CASE WHEN 用法介绍
1. CASE WHEN 表达式有两种形式
--简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE
WHEN sex = '1' THEN
- PHP技巧汇总:提高PHP性能的53个技巧
dcj3sjt126com
PHP
PHP技巧汇总:提高PHP性能的53个技巧 用单引号代替双引号来包含字符串,这样做会更快一些。因为PHP会在双引号包围的字符串中搜寻变量, 单引号则不会,注意:只有echo能这么做,它是一种可以把多个字符串当作参数的函数译注: PHP手册中说echo是语言结构,不是真正的函数,故把函数加上了双引号)。 1、如果能将类的方法定义成static,就尽量定义成static,它的速度会提升将近4倍
- Yii框架中CGridView的使用方法以及详细示例
dcj3sjt126com
yii
CGridView显示一个数据项的列表中的一个表。
表中的每一行代表一个数据项的数据,和一个列通常代表一个属性的物品(一些列可能对应于复杂的表达式的属性或静态文本)。 CGridView既支持排序和分页的数据项。排序和分页可以在AJAX模式或正常的页面请求。使用CGridView的一个好处是,当用户浏览器禁用JavaScript,排序和分页自动退化普通页面请求和仍然正常运行。
实例代码如下:
- Maven项目打包成可执行Jar文件
dyy_gusi
assembly
Maven项目打包成可执行Jar文件
在使用Maven完成项目以后,如果是需要打包成可执行的Jar文件,我们通过eclipse的导出很麻烦,还得指定入口文件的位置,还得说明依赖的jar包,既然都使用Maven了,很重要的一个目的就是让这些繁琐的操作简单。我们可以通过插件完成这项工作,使用assembly插件。具体使用方式如下:
1、在项目中加入插件的依赖:
<plugin>
- php常见错误
geeksun
PHP
1. kevent() reported that connect() failed (61: Connection refused) while connecting to upstream, client: 127.0.0.1, server: localhost, request: "GET / HTTP/1.1", upstream: "fastc
- 修改linux的用户名
hongtoushizi
linuxchange password
Change Linux Username
更改Linux用户名,需要修改4个系统的文件:
/etc/passwd
/etc/shadow
/etc/group
/etc/gshadow
古老/传统的方法是使用vi去直接修改,但是这有安全隐患(具体可自己搜一下),所以后来改成使用这些命令去代替:
vipw
vipw -s
vigr
vigr -s
具体的操作顺
- 第五章 常用Lua开发库1-redis、mysql、http客户端
jinnianshilongnian
nginxlua
对于开发来说需要有好的生态开发库来辅助我们快速开发,而Lua中也有大多数我们需要的第三方开发库如Redis、Memcached、Mysql、Http客户端、JSON、模板引擎等。
一些常见的Lua库可以在github上搜索,https://github.com/search?utf8=%E2%9C%93&q=lua+resty。
Redis客户端
lua-resty-r
- zkClient 监控机制实现
liyonghui160com
zkClient 监控机制实现
直接使用zk的api实现业务功能比较繁琐。因为要处理session loss,session expire等异常,在发生这些异常后进行重连。又因为ZK的watcher是一次性的,如果要基于wather实现发布/订阅模式,还要自己包装一下,将一次性订阅包装成持久订阅。另外如果要使用抽象级别更高的功能,比如分布式锁,leader选举
- 在Mysql 众多表中查找一个表名或者字段名的 SQL 语句
pda158
mysql
在Mysql 众多表中查找一个表名或者字段名的 SQL 语句:
方法一:SELECT table_name, column_name from information_schema.columns WHERE column_name LIKE 'Name';
方法二:SELECT column_name from information_schema.colum
- 程序员对英语的依赖
Smile.zeng
英语程序猿
1、程序员最基本的技能,至少要能写得出代码,当我们还在为建立类的时候思考用什么单词发牢骚的时候,英语与别人的差距就直接表现出来咯。
2、程序员最起码能认识开发工具里的英语单词,不然怎么知道使用这些开发工具。
3、进阶一点,就是能读懂别人的代码,有利于我们学习人家的思路和技术。
4、写的程序至少能有一定的可读性,至少要人别人能懂吧...
以上一些问题,充分说明了英语对程序猿的重要性。骚年
- Oracle学习笔记(8) 使用PLSQL编写触发器
vipbooks
oraclesql编程活动Access
时间过得真快啊,转眼就到了Oracle学习笔记的最后个章节了,通过前面七章的学习大家应该对Oracle编程有了一定了了解了吧,这东东如果一段时间不用很快就会忘记了,所以我会把自己学习过的东西做好详细的笔记,用到的时候可以随时查找,马上上手!希望这些笔记能对大家有些帮助!
这是第八章的学习笔记,学习完第七章的子程序和包之后