【转】redis lru实现策略
浅析LRU(K-V)缓存:
https://www.cnblogs.com/wxisme/p/4889846.html?utm_source=tuicool&utm_medium=referral
地址:https://blog.csdn.net/mysqldba23/article/details/68482894
在使用redis作为缓存的场景下,内存淘汰策略决定的redis的内存使用效率。在大部分场景下,我们会采用LRU(Least Recently Used)来作为redis的淘汰策略。本文将由浅入深的介绍redis lru策略的具体实现。
首先我们来科普下,什么是LRU ?(以下来自维基百科)
Discards the least recently used items first. This algorithm requires keeping track of what was used when, which is expensive if one wants to make sure the algorithm always discards the least recently used item. General implementations of this technique require keeping “age bits” for cache-lines and track the “Least Recently Used” cache-line based on age-bits. In such an implementation, every time a cache-line is used, the age of all other cache-lines changes.
简而言之,就是每次淘汰最近最少使用的元素 。一般的实现,都是采用对存储在内存的元素采用 'age bits’ 来标记该元素从上次访问到现在为止的时长,从而在每次用LRU淘汰时,淘汰这些最长时间未被访问的元素。
这里我们先实现一个简单的LRU Cache,以便于后续内容的理解 。(来自leetcod,不过这里我重新用Python语言实现了)
实现该缓存满足如下两点:
- get(key) - 如果该元素(总是正数)存在,将该元素移动到lru头部,并返回该元素的值,否则返回-1。
- set(key,value) - 设置一个key的值为value(如果该元素存在),并将该元素移动到LRU头部。否则LRU头部插入一个key,且值为value。如果在设置前检查到,该key插入后,会超过cache的容量,则根据LRU策略,删除最近最少使用的key。
分析
这里我们采用双向链表来实现元素(k-v键值对)的存储,同时采用hash表来存储相关的key与item的对应关系。这样,我们既能在O(1)的时间对key进行操作,同时又能利用Double LinkedList的添加和删除节点的便利性。(get/set都能在O(1)内完成)。
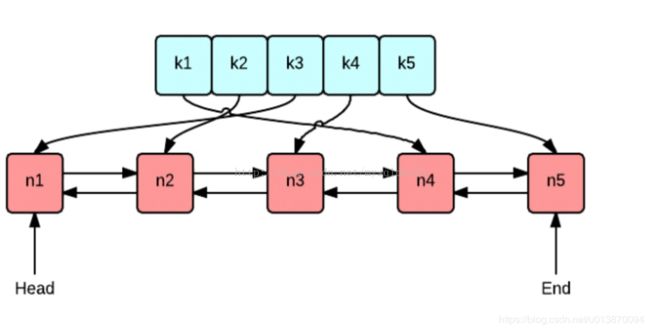
#python实现
class Node:
key=None
value=None
pre=None
next=None
def __init__(self,key,value):
self.key=key
self.value=value
class LRUCache:
capacity=0
map={} # key is string ,and value is Node object
head=None
end=None
def __init__(self,capacity):
self.capacity=capacity
def get(self,key):
if key in self.map:
node=self.map[key]
self.remove(node)
self.setHead(node)
return node.value
else:
return -1
def getAllKeys(self):
tmpNode=None
if self.head:
tmpNode=self.head
while tmpNode:
print (tmpNode.key,tmpNode.value)
tmpNode=tmpNode.next
def remove(self,n):
if n.pre:
n.pre.next=n.next
else:
self.head=n.next
if n.next:
n.next.pre=n.pre
else:
self.end=n.pre
def setHead(self,n):
n.next=self.head
n.pre=None
if self.head:
self.head.pre=n
self.head=n
if not self.end:
self.end=self.head
def set(self,key,value):
if key in self.map:
oldNode=self.map[key]
oldNode.value=value
self.remove(oldNode)
self.setHead(oldNode)
else:
node=Node(key,value)
if len(self.map) >= self.capacity:
self.map.pop(self.end.key)
self.remove(self.end)
self.setHead(node)
else:
self.setHead(node)
self.map[key]=node
def main():
cache=LRUCache(100)
#d->c->b->a
cache.set('a','1')
cache.set('b','2')
cache.set('c',3)
cache.set('d',4)
#遍历lru链表
cache.getAllKeys()
#修改('a','1') ==> ('a',5),使该节点从LRU尾端移动到开头.
cache.set('a',5)
#LRU链表变为 a->d->c->b
cache.getAllKeys()
#访问key='c'的节点,是该节点从移动到LRU头部
cache.get('c')
#LRU链表变为 c->a->d->b
cache.getAllKeys()
if __name__ == '__main__':
main()
通过上面简单的介绍与实现,现在我们基本已经了解了什么是LRU,下面我们来看看LRU算法在redis 内部的实现细节,以及其会在什么情况下带来问题。在redis内部,是通过全局结构体redisServer 保存redis启动之后相关的信息,比如:
struct redisServer {
pid_t pid; /* Main process pid. */
char *configfile; /* Absolute config file path, or NULL */
…..
unsigned lruclock:LRU_BITS; /* Clock for LRU eviction */
...
};
serverCron运行频率hz等lruclock:LRU_BITS,其中存储了服务器自启动之后的lru时钟,该时钟是全局的lru时钟。该时钟100ms(可以通过hz来调整,默认情况hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次。
接下来我们看看LRU时钟的具体实现:
server.lruclock = getLRUClock();
getLRUClock函数如下:
#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
#define LRU_BITS 24
#define LRU_CLOCK_MAX ((1</* Max value of obj->lru */
/* Return the LRU clock, based on the clock resolution. This is a time
* in a reduced-bits format that can be used to set and check the
* object->lru field of redisObject structures. */
unsigned int getLRUClock(void) {
return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX;
}
因此lrulock最大能到(2**24-1)/3600/24 = 194天,如果超过了这个时间,lrulock重新开始。
对于redis server来说,server.lrulock表示的是一个全局的lrulock,那么对于每个redisObject都有一个自己的lrulock。这样每redisObject就可以根据自己的lrulock和全局的server.lrulock比较,来确定是否能够被淘汰掉。
redis key对应的value的存放对象:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to server.lruclock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits decreas time). */
int refcount;
void *ptr;
} robj
那么什么时候,lru会被更新呢 ?访问该key,lru都会被更新,这样该key就能及时的被移动到lru头部,从而避免从lru中淘汰。下面是这一部分的实现:
/* Low level key lookup API, not actually called directly from commands
* implementations that should instead rely on lookupKeyRead(),
* lookupKeyWrite() and lookupKeyReadWithFlags(). */
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
/* Update the access time for the ageing algorithm.
* Don't do it if we have a saving child, as this will trigger
* a copy on write madness. */
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
!(flags & LOOKUP_NOTOUCH))
{
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
unsigned long ldt = val->lru >> 8;
unsigned long counter = LFULogIncr(val->lru & 255);
val->lru = (ldt << 8) | counter;
} else {
val->lru = LRU_CLOCK();
}
}
return val;
} else {
return NULL;
}
}
接下来,我们在来分析,key的lru淘汰策略如何实现,分别有哪几种:
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
# volatile-lru -> Evict using approximated LRU among the keys with an expire set. //在设置了过期时间的key中,使用近似的lru淘汰策略
# allkeys-lru -> Evict any key using approximated LRU. //所有的key均使用近似的lru淘汰策略
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set. //在设置了过期时间的key中,使用lfu淘汰策略
# allkeys-lfu -> Evict any key using approximated LFU. //所有的key均使用lfu淘汰策略
# volatile-random -> Remove a random key among the ones with an expire set. //在设置了过期时间的key中,使用随机淘汰策略
# allkeys-random -> Remove a random key, any key. //所有的key均使用随机淘汰策略
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL) //使用ttl淘汰策略
# noeviction -> Don't evict anything, just return an error on write operations . //不允许淘汰,在写操作发生,但内存不够时,将会返回错误
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.
这里暂不讨论LFU,TTL淘汰算法和noeviction的情况,仅仅讨论lru所有场景下的,淘汰策略具体实现。(LFU和TTL将在下一篇文章中详细分析)。
LRU淘汰的场景:
1.主动淘汰。
1.1 通过定时任务serverCron定期的清理过期的key。
2.被动淘汰
2.1 每次写入key时,发现内存不够,调用activeExpireCycle释放一部分内存。
2.2 每次访问相关的key,如果发现key过期,直接释放掉该key相关的内存。
首先我们来分析LRU主动淘汰的场景:
serverCron每间隔1000/hz ms会调用databasesCron方法来检测并淘汰过期的key。
void databasesCron(void){
/* Expire keys by random sampling. Not required for slaves
* as master will synthesize DELs for us. */
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
…..
}
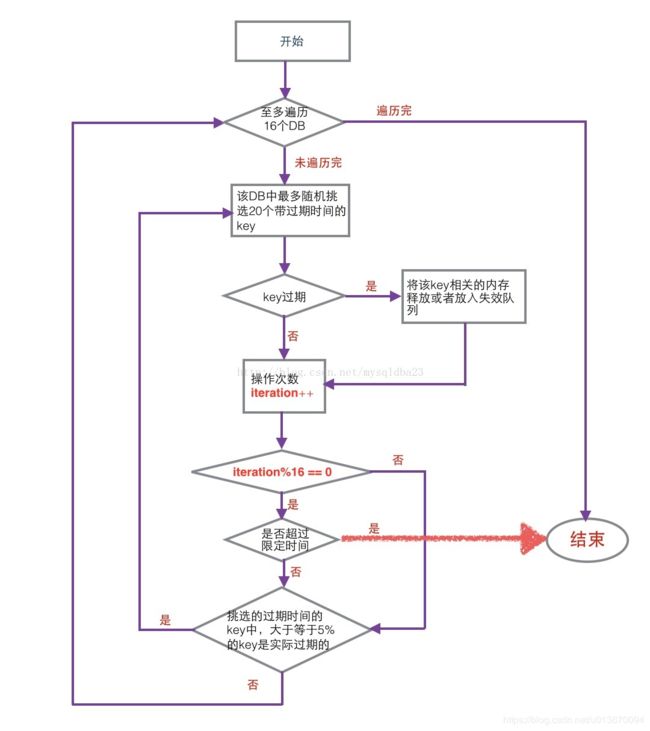
主动淘汰是通过activeExpireCycle 来实现的,这部分的逻辑如下:
1.遍历至多16个DB 。【由宏CRON_DBS_PER_CALL定义,默认为16】
2.随机挑选20个带过期时间的key。【由宏ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP定义,默认20】
3.如果key过期,则将key相关的内存释放,或者放入失效队列。
4.如果操作时间超过允许的限定时间,至多25ms。(timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100,
,ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC=25,server.hz默认为10), 则此次淘汰操作结束返回,否则进入5。
5.如果该DB下,有超过5个key (ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4=5) 实际失效,则进入 2,否则选择下一个DB,再次进入2。
6.遍历完成,结束。
流程图如下
注:(图中大于等于%5的可以是实际过期的,应改为大于等于%25的key是实际过期的。iteration++是在遍历20个key的时候,每次加1)。
被动淘汰 - 内存不够,调用activeExpireCycle释放
该步骤的实现方式如下:
processCommand 函数关于内存淘汰策略的逻辑:
/* Handle the maxmemory directive.
*
* First we try to free some memory if possible (if there are volatile
* keys in the dataset). If there are not the only thing we can do
* is returning an error. */
if (server.maxmemory) {
int retval = freeMemoryIfNeeded();
/* freeMemoryIfNeeded may flush slave output buffers. This may result
* into a slave, that may be the active client, to be freed. */
if (server.current_client == NULL) return C_ERR;
/* It was impossible to free enough memory, and the command the client
* is trying to execute is denied during OOM conditions? Error. */
if ((c->cmd->flags & CMD_DENYOOM) && retval == C_ERR) {
flagTransaction(c);
addReply(c, shared.oomerr);
return C_OK;
}
}
每次执行命令前,都会调用freeMemoryIfNeeded来检查内存的情况,并释放相应的内存,如果释放后,内存仍然不够,直接向请求的客户端返回OOM。
具体的步骤如下:
1.获取redis server当前已经使用的内存mem_reported。
2.如果mem_reported < server.maxmemory ,则返回ok。否则mem_used=mem_reported,进入步骤3。
3.遍历该redis的所slaves,mem_used减去所有slave占用的ClientOutputBuffer。
4.如果配置了AOF,mem_used减去AOF占用的空间。sdslen(server.aof_buf)+aofRewriteBufferSize()。
5.如果mem_used < server.maxmemory,返回ok。否则进入步骤6。
6.如果内存策略配置为noeviction,返回错误。否则进入7。
7.如果是LRU策略,如果是VOLATILE的LRU,则每次从可失效的数据集中,每次随机采样maxmemory_samples(默认为5)个key,从中选取idletime最大的key进行淘汰。
否则,如果是ALLKEYS_LRU则从全局数据中进行采样,每次随机采样maxmemory_samples(默认为5)个key,并从中选择idletime最大的key进行淘汰。
8.如果释放内存之后,还是超过了server.maxmemory,则继续淘汰,只到释放后剩下的内存小于server.maxmemory为止。
被动淘汰 - 每次访问相关的key,如果发现key过期,直接释放掉该key相关的内存:
每次访问key,都会调用expireIfNeeded来判断key是否过期,如果过期,则释放掉,并返回null,否则返回key的值。
总结
1.redis做为缓存,经常采用LRU的策略来淘汰数据,所以如果同时过期的数据太多,就会导致redis发起主动检测时耗费的时间过长(最大为250ms),从而导致最大应用超时 >= 250ms。
timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100
ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC=25
server.hz>=1(默认为10)
timelimit <= 250ms
2.内存使用率过高,则会导致内存不够,从而发起被动淘汰策略,从而使应用访问超时。
3.合理的调整hz参数,从而控制每次主动淘汰的频率,从而有效的缓解过期的key数量太多带来的上述超时问题。
转载自:http://blog.chinaunix.net/uid-20708886-id-5753422.html